Clear Sky Science · pl
Hybrydowy framework XGBoost zoptymalizowany za pomocą SMOTE i modelu mieszanek Gaussowskich do wykrywania zaburzenia dwubiegunowego
Dlaczego ma to znaczenie dla codziennego zdrowia psychicznego
Zaburzenie dwubiegunowe może dramatycznie zaburzyć życie osoby, a mimo to przez lata bywa pomijane lub błędnie diagnozowane. Wielu pacjentów przechodzi przez epizody intensywnych wzlotów i przytłaczających upadków, zanim otrzyma odpowiednią pomoc. Badanie to pokazuje, jak zaawansowane metody komputerowe mogą przesiać rutynowe kwestionariusze kliniczne i zapisy, aby wcześniej i bardziej wiarygodnie wskazywać osoby, które mogą mieć zaburzenie dwubiegunowe. Praca prowadzi ku narzędziom wspomagającym decyzje, które mogłyby współpracować z klinicystami, pomagając im dostrzec wzorce, które ludzkim oczom łatwo umykają, a które są kluczowe dla terminowej opieki.

Trudność w wykrywaniu ukrytych wahań nastroju
Zaburzenie dwubiegunowe nie wygląda jednakowo u każdego pacjenta. Objawy mogą nakładać się z depresją, lękiem i innymi schorzeniami, a wiele ocen opiera się na pamięci pacjentów i interpretacji krótkich wizyt lekarskich. W efekcie ważne sygnały ostrzegawcze są pomijane, a pacjenci mogą otrzymywać leczenie nieodpowiednie dla ich rzeczywistego stanu. Dodatkowo bazy medyczne zwykle zawierają znacznie mniej potwierdzonych przypadków dwubiegunowości niż przypadków bez niej, co utrudnia standardowym modelom komputerowym nauczenie się, jak naprawdę wygląda to zaburzenie. Autorzy przekonują, że potrzebujemy narzędzi radzących sobie z tą nierównowagą, potrafiących odkryć ukryte podgrupy pacjentów i jednocześnie pozostających zrozumiałymi dla klinicystów.
Inteligentny pipeline z prostych elementów
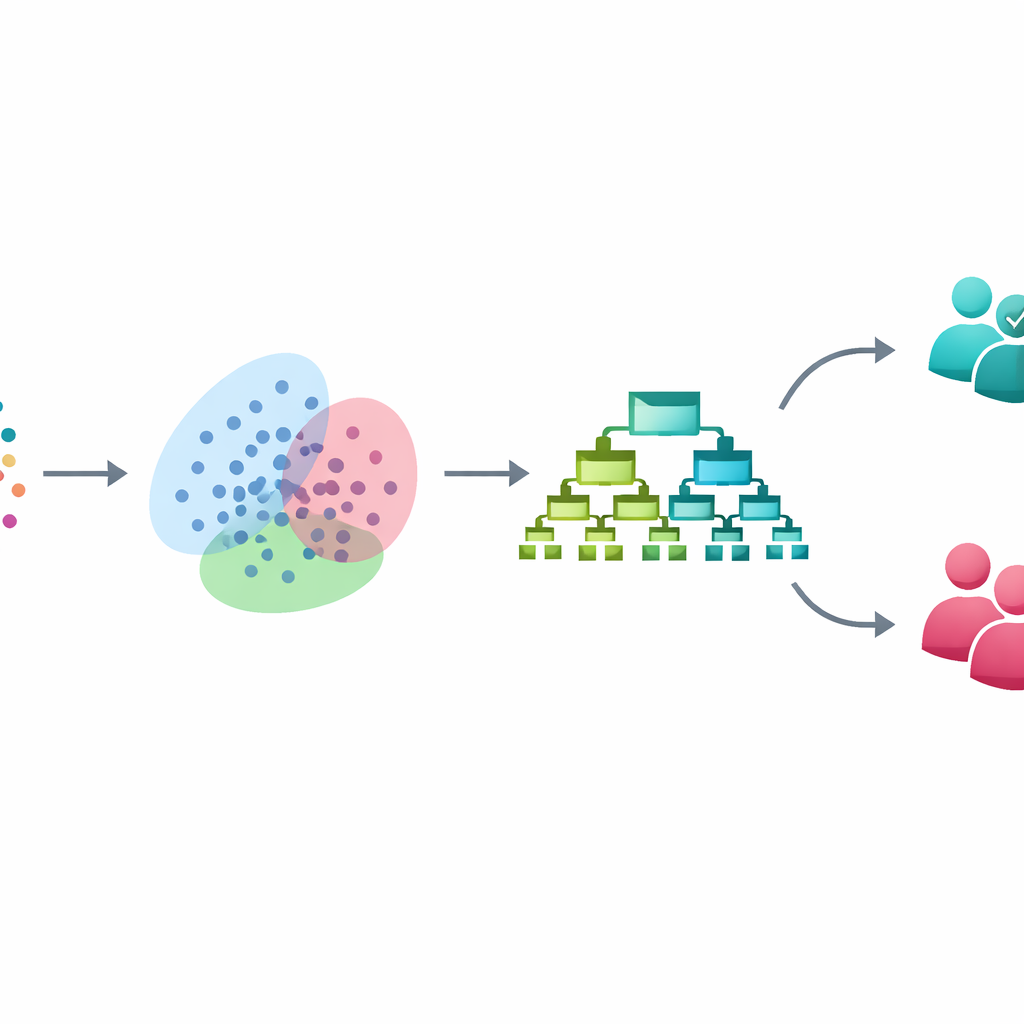
Zamiast sięgać po nieprzejrzyste systemy głębokiego uczenia, badacze zbudowali krok po kroku pipeline z trzech dobrze ugruntowanych technik, z których każda rozwiązuje konkretny problem. Najpierw oczyszczają i standaryzują zbiór danych obejmujący 3753 osoby, z których każda opisana jest 54 cechami klinicznymi i kwestionariuszowymi dotyczącymi nastroju, snu, zachowań i funkcjonowania. Następnie rozwiązują problem nierównej liczby przypadków dwubiegunowych i niedwubiegunowych za pomocą metody zwanej SMOTE. Zamiast po prostu kopiować rzadkie przypadki dwubiegunowe, SMOTE tworzy nowe „pomiędzy” przykłady, delikatnie interpolując między rzeczywistymi pacjentami z dwubiegunowością, dając modelowi bardziej zrównoważone doświadczenie obu grup w trakcie treningu, przy jednoczesnym pozostawieniu danych testowych nietkniętych.
Odkrywanie ukrytych grup w danych
Po zbalansowaniu danych pipeline stosuje modelowanie mieszanek Gaussowskich, elastyczne podejście klastrowania, które szuka naturalnych grup pacjentów bez użycia etykiet diagnozy. Zamiast zmuszać każdą osobę do jednoznacznego przyporządkowania, przypisuje prawdopodobieństwa przynależności do kilku nakładających się grup, odzwierciedlając rozmyte granice często obserwowane w praktyce psychiatrycznej. Te prawdopodobieństwa są następnie dodawane jako nowe, subtelne cechy opisujące pozycję każdego pacjenta wśród tych ukrytych podgrup. W praktyce model uczy się nie tylko na podstawie bezpośrednich pomiarów z kwestionariuszy, lecz także na głębszych wzorcach podobieństwa, które mogą odpowiadać różnym profilom objawów lub etapom choroby.
Przekształcanie wzorców w praktyczne predykcje
Dzięki wzbogaconemu opisowi każdego pacjenta, ostatni etap wykorzystuje XGBoost — potężny zespół drzew decyzyjnych, szczególnie skuteczny na danych tabelarycznych w klinice. Badacze starannie stroją ten model za pomocą walidacji krzyżowej i utrzymują wszystkie kroki balansowania i klastrowania ściśle wewnątrz procesu trenowania, aby uniknąć zanieczyszczenia zbioru testowego. Na nieznanych danych ich system poprawnie klasyfikuje przypadki dwubiegunowe i niedwubiegunowe w 93% przypadków. Wykrywa 97% prawdziwych przypadków dwubiegunowych (wysoka czułość), przy utrzymaniu 93% precyzji i silnej równowagi między wykrywaniem rzeczywistych przypadków a ograniczaniem fałszywych alarmów. W porównaniu z dobrze znanymi metodami, takimi jak regresja logistyczna, drzewa decyzyjne, maszyny wektorów nośnych i lasy losowe, nowy framework poprawia wydajność o 6–12 punktów procentowych, w zależności od porównania.
Co to oznacza dla pacjentów i klinicystów
Dla laika główne przesłanie jest takie, że podejście hybrydowe oferuje bardziej niezawodny system wczesnego ostrzegania, a nie zastępstwo dla psychiatry. Poprzez zbalansowanie danych, odkrycie ukrytych podgrup pacjentów oraz użycie interpretowalnego modelu opartego na drzewach, framework może wskazywać osoby, które prawdopodobnie mają zaburzenie dwubiegunowe, aby klinicyści mogli zbadać je dalej zgodnie ze standardowymi wytycznymi diagnostycznymi, takimi jak DSM-5 czy ICD-11. Autorzy podkreślają, że narzędzie jest wystarczająco przejrzyste, by ujawniać, które cechy kliniczne i podgrupowe mają największe znaczenie, co ułatwia zaufanie i integrację z opieką w praktyce. Choć badanie opiera się na jednym zbiorze danych i będzie wymagało testów w różnych szpitalach i populacjach, pokazuje, że przemyślane połączenie kilku umiarkowanych technik może dać praktyczną, skalowalną pomoc w wcześniejszym i dokładniejszym przesiewie zaburzenia dwubiegunowego.
Cytowanie: Kumar, S., Kumari, D., Panwar, A. et al. A hybrid SMOTE and Gaussian mixture model based optimized XGBoost framework for bipolar disorder detection. Sci Rep 16, 11887 (2026). https://doi.org/10.1038/s41598-026-39104-3
Słowa kluczowe: wykrywanie zaburzenia dwubiegunowego, badanie zdrowia psychicznego, uczenie maszynowe w psychiatrii, wspomaganie decyzji klinicznych, nierównoważne dane medyczne