Clear Sky Science · it
Un framework XGBoost ottimizzato basato su SMOTE ibrido e modello di miscela gaussiana per la rilevazione del disturbo bipolare
Perché questo è importante per la salute mentale di tutti i giorni
Il disturbo bipolare può sconvolgere profondamente la vita di una persona, eppure spesso viene trascurato o diagnosticato in modo errato per anni. Molte persone vivono cicli di picchi emotivi intensi e crolli profondi prima di ricevere l'aiuto adeguato. Questo studio esplora come metodi informatici avanzati possano analizzare questionari clinici di routine e cartelle cliniche per segnalare con maggiore anticipo e affidabilità persone che potrebbero avere un disturbo bipolare. Il lavoro indica la strada verso strumenti di supporto alle decisioni che affiancherebbero i clinici, aiutandoli a individuare schemi che per gli esseri umani sono facili da trascurare ma cruciali per un intervento tempestivo.

La sfida di individuare sbalzi d’umore nascosti
Il disturbo bipolare non si manifesta allo stesso modo in tutte le persone. I sintomi possono sovrapporsi a depressione, ansia e ad altre condizioni, e molte valutazioni si basano su ciò che i pazienti ricordano e su come i medici interpretano visite brevi. Di conseguenza, segnali di allarme importanti vengono persi e i pazienti possono ricevere trattamenti non adatti alla loro condizione reale. Inoltre, i database medici contengono tipicamente molti meno casi confermati di bipolarismo rispetto ai non-bipolari, il che rende più difficile per i modelli computazionali standard apprendere come si presenta davvero il disturbo bipolare. Gli autori sostengono che servono strumenti in grado di gestire questo squilibrio, scoprire sottogruppi di pazienti nascosti e rimanere comunque comprensibili per i clinici.
Una pipeline intelligente costruita da blocchi semplici
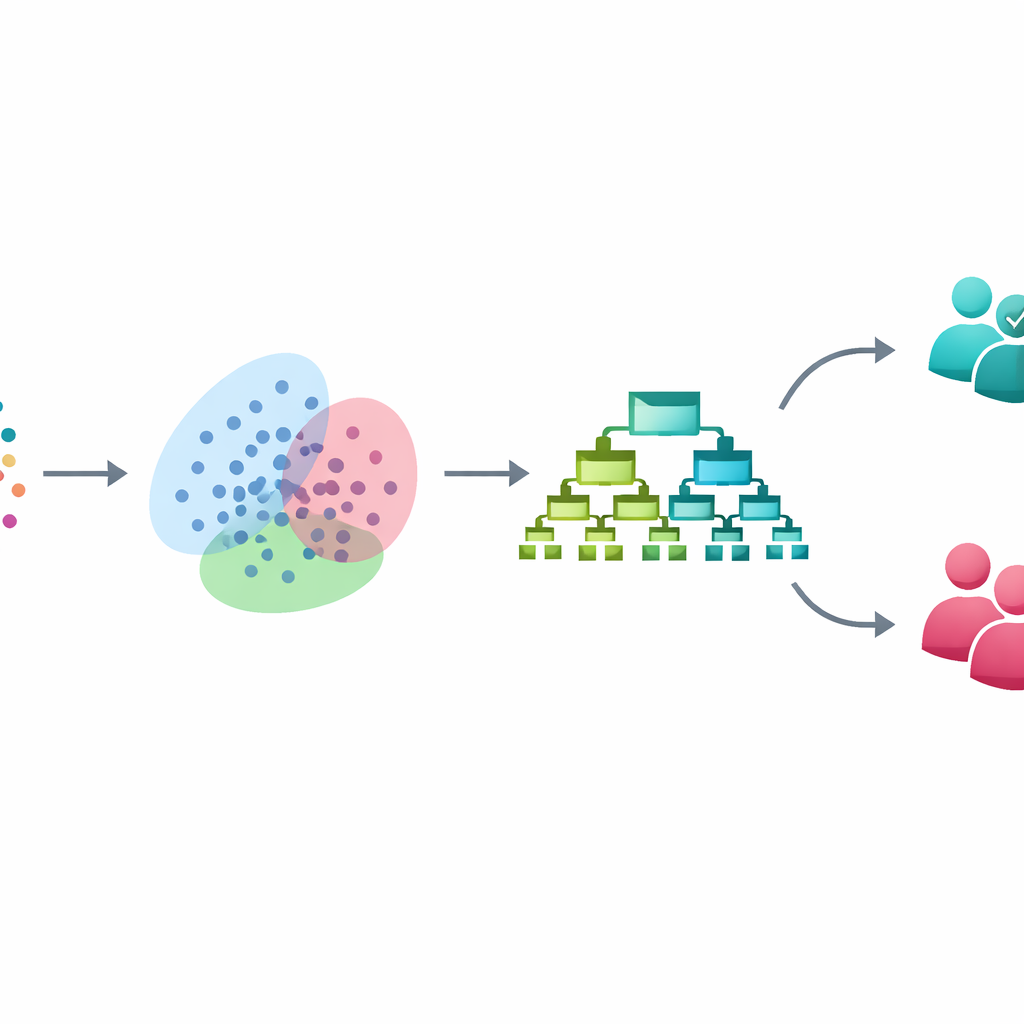
Invece di rivolgersi a sistemi di deep learning opachi, i ricercatori costruiscono una pipeline passo dopo passo a partire da tre tecniche consolidate, ciascuna pensata per risolvere un problema specifico. Prima puliscono e standardizzano un dataset di 3.753 persone, ognuna descritta da 54 variabili cliniche e di questionario relative a umore, sonno, comportamento e funzionamento. Poi affrontano il numero diseguale di casi bipolari e non bipolari utilizzando un metodo chiamato SMOTE. Piuttosto che copiare semplicemente i rari casi bipolari, SMOTE crea nuovi esempi “intermedi” interpolando in modo controllato tra pazienti bipolari reali, dando al modello una esperienza più bilanciata di entrambi i gruppi durante l’addestramento, lasciando però intatti i dati di test.
Trovare gruppi nascosti all’interno dei dati
Dopo aver bilanciato i dati, la pipeline applica un modello di miscela gaussiana, un approccio di clustering flessibile che cerca raggruppamenti naturali nei pazienti senza usare le etichette diagnostiche. Invece di costringere ogni persona in un'unica categoria, assegna probabilità di appartenenza a più gruppi sovrapposti, riflettendo i confini sfumati che spesso si osservano nella pratica psichiatrica reale. Queste probabilità vengono poi aggiunte come nuove, sottili caratteristiche che descrivono la posizione di ciascun paziente tra questi sottogruppi nascosti. Di fatto, il modello impara non solo da quanto misurato direttamente dai questionari, ma anche da modelli di somiglianza più profondi che potrebbero corrispondere a diversi profili sintomatici o fasi della malattia.
Trasformare gli schemi in previsioni pratiche
Con questa descrizione arricchita di ciascun paziente, la fase finale utilizza XGBoost, un potente ensemble di alberi decisionali particolarmente efficace sui dati clinici in formato tabellare. I ricercatori ottimizzano accuratamente questo modello usando la cross-validation e mantengono tutte le fasi di bilanciamento e clustering rigorosamente all'interno del processo di addestramento per evitare la contaminazione del set di test. Su dati non visti, il loro sistema classifica correttamente casi bipolari versus non bipolari nel 93% dei casi. Individua il 97% dei veri casi bipolari (alta sensibilità) mantenendo il 93% di precisione e un forte equilibrio complessivo tra intercettare casi reali ed evitare falsi allarmi. Rispetto a metodi noti come regressione logistica, alberi decisionali, macchine a vettori di supporto e foreste casuali, il nuovo framework migliora le prestazioni del 6-12 punti percentuali, a seconda del confronto.
Cosa significa per pazienti e clinici
Per un lettore non specialista, il messaggio principale è che questo approccio ibrido offre un sistema di allerta precoce più affidabile, non un sostituto dello psichiatra. Bilanciando i dati, scoprendo sottogruppi nascosti di pazienti e usando un modello interpretabile basato su alberi, il framework può segnalare individui con alta probabilità di disturbo bipolare in modo che i clinici possano approfondire con linee guida diagnostiche standard come DSM-5 o ICD-11. Gli autori sottolineano che lo strumento è sufficientemente trasparente da mostrare quali caratteristiche cliniche e di sottogruppo sono più rilevanti, facilitandone la fiducia e l'integrazione nella pratica reale. Pur essendo lo studio basato su un singolo dataset e quindi bisognoso di validazione in diversi ospedali e popolazioni, dimostra che combinare con cura diverse tecniche modeste può produrre un aiuto pratico e scalabile per uno screening più precoce e accurato del disturbo bipolare.
Citazione: Kumar, S., Kumari, D., Panwar, A. et al. A hybrid SMOTE and Gaussian mixture model based optimized XGBoost framework for bipolar disorder detection. Sci Rep 16, 11887 (2026). https://doi.org/10.1038/s41598-026-39104-3
Parole chiave: rilevazione del disturbo bipolare, screening della salute mentale, apprendimento automatico in psichiatria, supporto alle decisioni cliniche, dati medici sbilanciati