Clear Sky Science · nl
Een hybride SMOTE- en Gaussiaans mengmodel-geoptimaliseerd XGBoost-kader voor detectie van bipolaire stoornis
Waarom dit relevant is voor alledaagse geestelijke gezondheid
Bipolaire stoornis kan iemands leven ingrijpend verstoren, maar wordt vaak jaren gemist of verkeerd gediagnosticeerd. Veel mensen doorlopen periodes van intense hoogtepunten en verpletterende dieptepunten voordat ze de juiste hulp krijgen. Deze studie onderzoekt hoe geavanceerde rekenmethoden routinematige klinische vragenlijsten en dossiers kunnen doorzoeken om mensen die mogelijk een bipolaire stoornis hebben eerder en betrouwbaarder te signaleren. Het werk wijst op besluitondersteunende hulpmiddelen die naast clinici kunnen staan en hen helpen patronen te zien die voor mensen gemakkelijk over het hoofd te zien zijn maar cruciaal zijn voor tijdige zorg.

De uitdaging van het opsporen van verborgen stemmingswisselingen
Bipolaire stoornis ziet er niet bij iedereen hetzelfde uit. Symptomen kunnen overlappen met depressie, angst en andere aandoeningen, en veel beoordelingen zijn afhankelijk van wat patiënten zich herinneren en hoe artsen korte consulten interpreteren. Daardoor worden belangrijke waarschuwingssignalen gemist en kunnen mensen behandelingen krijgen die niet bij hun werkelijke aandoening passen. Bovendien bevatten medische databases doorgaans veel minder bevestigde bipolaire gevallen dan niet-bipolaire, wat het voor standaard computermodellen moeilijker maakt te leren hoe bipolaire stoornis er echt uitziet. De auteurs stellen dat we tools nodig hebben die met deze ongelijkheid kunnen omgaan, verborgen patiëntensubgroepen kunnen blootleggen en toch begrijpelijk blijven voor clinici.
Een slimme pijplijn opgebouwd uit eenvoudige bouwstenen
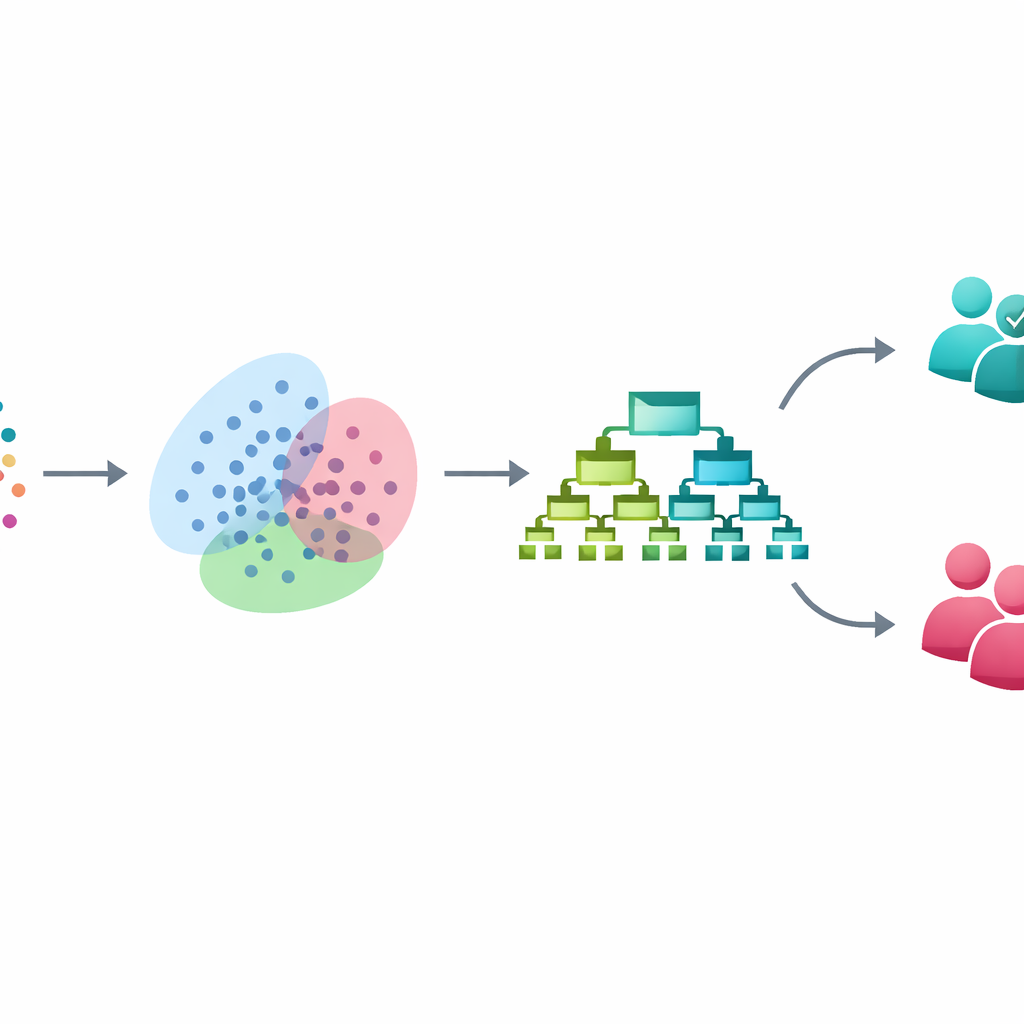
In plaats van te kiezen voor ondoorzichtige deep-learning systemen, bouwen de onderzoekers een stapsgewijze pijplijn uit drie goed gevestigde technieken, waarbij iedere stap een specifiek probleem oplost. Eerst maken ze een dataset van 3.753 mensen schoon en standaardiseren die, waarbij elke persoon wordt beschreven door 54 klinische en vragenlijstachtige kenmerken gerelateerd aan stemming, slaap, gedrag en functioneren. Vervolgens pakken ze de ongelijke aantallen bipolaire en niet-bipolaire gevallen aan met een methode genaamd SMOTE. In plaats van zeldzame bipolaire gevallen simpelweg te kopiëren, creëert SMOTE nieuwe "tussenliggende" voorbeelden door zachtjes te interpoleren tussen echte bipolaire patiënten, waardoor de computer tijdens het trainen meer gebalanceerde voorbeelden van beide groepen krijgt, terwijl de testdata onaangeroerd blijft.
Verborgen groepen in de data vinden
Na het balanceren van de data past de pijplijn Gaussiaans mengmodelklustering toe, een flexibele benadering die naar natuurlijke groepsvorming onder patiënten zoekt zonder de diagnoselabels te gebruiken. In plaats van elke persoon in één hok te dwingen, kent het probabiliteiten toe dat iemand bij meerdere overlappende groepen hoort, wat de vage grenzen weerspiegelt die vaak in de echte psychiatrische praktijk voorkomen. Deze probabiliteiten worden vervolgens toegevoegd als nieuwe, subtiele kenmerken die de positie van elke patiënt binnen deze verborgen subgroepen beschrijven. In wezen leert het model niet alleen van wat de vragenlijsten direct meten, maar ook van diepere gelijkenispatronen die kunnen overeenkomen met verschillende symptoomprofielen of ziektefasen.
Patronen omzetten in praktische voorspellingen
Met deze verrijkte beschrijving van elke patiënt gebruikt de laatste fase XGBoost, een krachtig ensemble van beslissingsbomen dat bijzonder effectief is voor tabelachtige klinische data. De onderzoekers stemmen dit model zorgvuldig af met kruisvalidatie en houden alle balancerings- en clusterstappen strikt binnen het trainingsproces om besmetting van de testset te voorkomen. Op ongeziene data classificeert hun systeem bipolaire versus niet-bipolaire gevallen correct in 93% van de gevallen. Het identificeert 97% van de echte bipolaire gevallen (hoge sensitiviteit) terwijl het 93% precisie behoudt en een sterke algehele balans tussen het vinden van echte gevallen en het vermijden van valse alarmen. Vergeleken met gangbare methoden zoals logistische regressie, beslisbomen, support vector machines en random forests verbetert het nieuwe kader de prestaties met 6 tot 12 procentpunten, afhankelijk van de vergelijking.
Wat dit betekent voor patiënten en clinici
Voor een leek is de belangrijkste conclusie dat deze hybride benadering een betrouwbaarder waarschuwingssysteem biedt, niet een vervanging voor een psychiater. Door de data te balanceren, verborgen patiëntensubgroepen te onthullen en een interpreteerbaar boomgebaseerd model te gebruiken, kan het kader individuen signaleren die waarschijnlijk een bipolaire stoornis hebben, zodat clinici verder onderzoek kunnen doen met behulp van standaard diagnostische richtlijnen zoals DSM-5 of ICD-11. De auteurs benadrukken dat het hulpmiddel transparant genoeg is om te laten zien welke klinische en subgroepkenmerken het meest van belang zijn, wat het vertrouwen en de integratie in de praktijk vergemakkelijkt. Hoewel de studie is gebaseerd op één dataset en getest moet worden in meerdere ziekenhuizen en populaties, laat het zien dat het doordacht combineren van enkele bescheiden technieken kan leiden tot een praktisch, schaalbaar hulpmiddel voor vroegere en nauwkeurigere screening op bipolaire stoornis.
Bronvermelding: Kumar, S., Kumari, D., Panwar, A. et al. A hybrid SMOTE and Gaussian mixture model based optimized XGBoost framework for bipolar disorder detection. Sci Rep 16, 11887 (2026). https://doi.org/10.1038/s41598-026-39104-3
Trefwoorden: detectie van bipolaire stoornis, screening van geestelijke gezondheid, machine learning in de psychiatrie, klinische besluitvorming ondersteuning, ongelijk verdeelde medische data