Clear Sky Science · es
Un marco optimizado XGBoost basado en un híbrido de SMOTE y modelo de mezcla gaussiana para la detección del trastorno bipolar
Por qué esto importa para la salud mental cotidiana
El trastorno bipolar puede alterar dramáticamente la vida de una persona, pero con frecuencia pasa desapercibido o se diagnostica de forma errónea durante años. Muchas personas atraviesan episodios de euforia intensa y depresiones devastadoras antes de recibir la atención adecuada. Este estudio explora cómo métodos informáticos avanzados pueden analizar cuestionarios clínicos rutinarios y registros para señalar a quienes podrían tener trastorno bipolar antes y con mayor fiabilidad. El trabajo apunta a herramientas de apoyo a la decisión que podrían acompañar al clínico, ayudándole a detectar patrones que los humanos fácilmente pasan por alto pero que son cruciales para una atención puntual.

El reto de detectar oscilaciones del ánimo ocultas
El trastorno bipolar no se manifiesta igual en todas las personas. Los síntomas pueden solaparse con la depresión, la ansiedad y otras condiciones, y muchas evaluaciones dependen de la memoria del paciente y de la interpretación de visitas breves por parte del médico. Como resultado, se pasan por alto señales de advertencia importantes y las personas pueden recibir tratamientos que no se ajustan a su condición real. Además, las bases de datos médicas suelen contener muchos menos casos confirmados de bipolaridad que de no bipolaridad, lo que dificulta que los modelos informáticos estándar aprendan cómo es realmente el trastorno bipolar. Los autores sostienen que hacen falta herramientas que manejen ese desequilibrio, descubran subgrupos ocultos de pacientes y sigan siendo comprensibles para los clínicos.
Una canalización inteligente construida con bloques simples
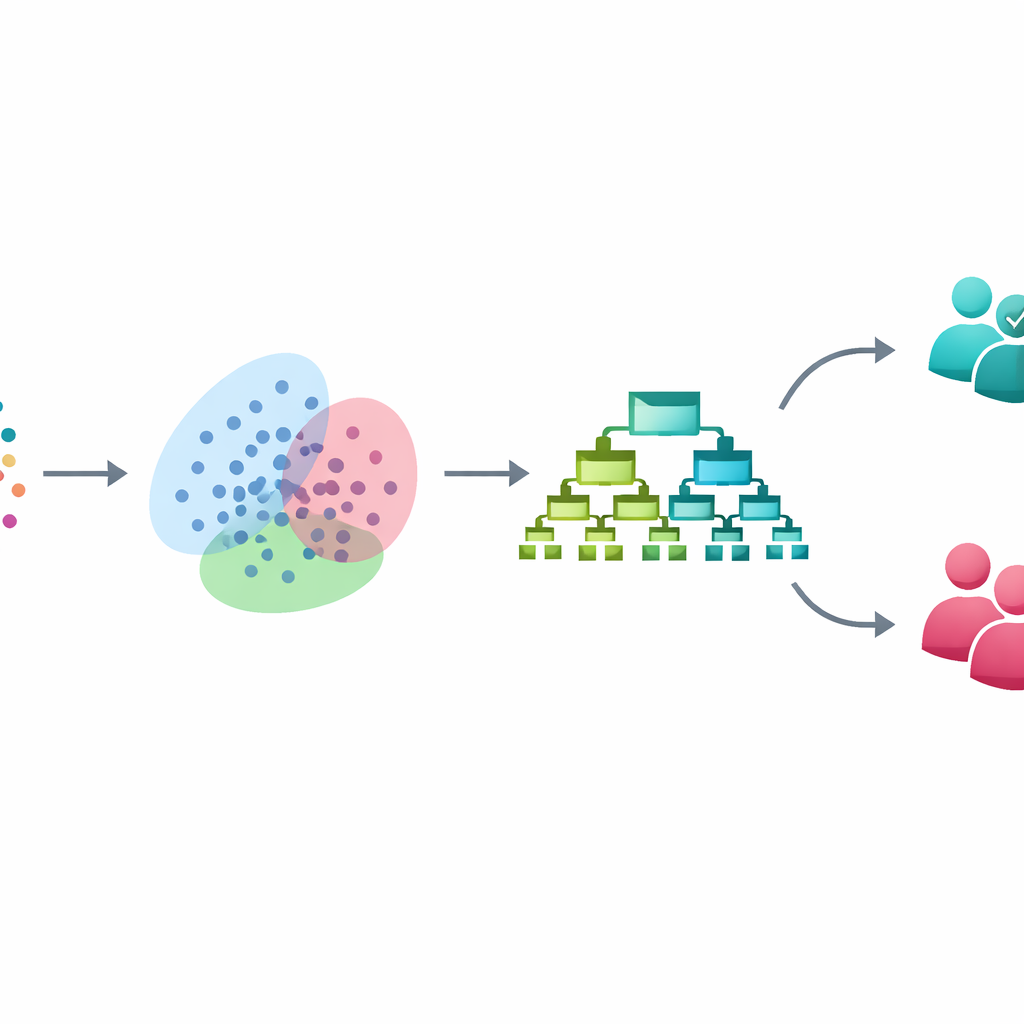
En lugar de recurrir a sistemas opacos de aprendizaje profundo, los investigadores construyen una canalización paso a paso a partir de tres técnicas bien establecidas, cada una resolviendo un problema específico. Primero, limpian y estandarizan un conjunto de datos de 3.753 personas, cada una descrita por 54 características clínicas y tipo cuestionario relacionadas con el estado de ánimo, el sueño, el comportamiento y el funcionamiento. Luego abordan la desigualdad entre el número de casos bipolares y no bipolares usando un método llamado SMOTE. En lugar de copiar simplemente los escasos casos bipolares, SMOTE crea nuevos ejemplos “intermedios” interpolando suavemente entre pacientes bipolares reales, dando al algoritmo una experiencia más equilibrada de ambos grupos durante el entrenamiento mientras deja intactos los datos de prueba.
Encontrar grupos ocultos dentro de los datos
Tras equilibrar los datos, la canalización aplica un modelo de mezcla gaussiana, un enfoque flexible de agrupamiento que busca agrupaciones naturales entre los pacientes sin utilizar las etiquetas de diagnóstico. En lugar de forzar a cada persona a un único grupo, asigna probabilidades de pertenecer a varios grupos solapados, reflejando los límites difusos que a menudo se observan en la práctica psiquiátrica real. Estas probabilidades se añaden luego como nuevas y sutiles características que describen la posición de cada paciente entre esos subgrupos ocultos. En efecto, el modelo aprende no solo de lo que miden directamente los cuestionarios, sino también de patrones más profundos de similitud que podrían corresponder a diferentes perfiles sintomáticos o etapas de la enfermedad.
Convertir patrones en predicciones prácticas
Con esta descripción enriquecida de cada paciente, la fase final utiliza XGBoost, un potente conjunto de árboles de decisión que resulta especialmente eficaz con datos clínicos en formato tabular. Los investigadores afinan cuidadosamente este modelo mediante validación cruzada y mantienen todos los pasos de balanceo y agrupamiento estrictamente dentro del proceso de entrenamiento para evitar la contaminación del conjunto de prueba. En datos no vistos, su sistema clasifica correctamente casos bipolares frente a no bipolares en el 93 % de las ocasiones. Identifica el 97 % de los casos bipolares verdaderos (alta sensibilidad) manteniendo un 93 % de precisión y un sólido equilibrio global entre detectar casos reales y evitar falsas alarmas. En comparación con métodos conocidos como regresión logística, árboles de decisión, máquinas de soporte vectorial y bosques aleatorios, el nuevo marco mejora el rendimiento entre 6 y 12 puntos porcentuales, según la comparación.
Qué significa esto para pacientes y clínicos
Para un lector general, la conclusión principal es que este enfoque híbrido ofrece un sistema de alerta temprana más fiable, no un sustituto del psiquiatra. Al equilibrar los datos, descubrir subgrupos ocultos de pacientes y utilizar un modelo interpretable basado en árboles, el marco puede señalar a individuos con probabilidad de tener trastorno bipolar para que los clínicos los investiguen más a fondo usando guías diagnósticas estándar como el DSM-5 o la CIE-11. Los autores enfatizan que la herramienta es lo bastante transparente como para revelar qué características clínicas y de subgrupo importan más, lo que facilita la confianza e integración en la atención real. Aunque el estudio se basa en un único conjunto de datos y necesitará pruebas en distintos hospitales y poblaciones, muestra que combinar con criterio varias técnicas modestas puede producir una ayuda práctica y escalable para un cribado más temprano y preciso del trastorno bipolar.
Cita: Kumar, S., Kumari, D., Panwar, A. et al. A hybrid SMOTE and Gaussian mixture model based optimized XGBoost framework for bipolar disorder detection. Sci Rep 16, 11887 (2026). https://doi.org/10.1038/s41598-026-39104-3
Palabras clave: detección del trastorno bipolar, cribado de la salud mental, aprendizaje automático en psiquiatría, soporte a la decisión clínica, datos médicos desbalanceados