Clear Sky Science · ru
Гибрид SMOTE и модели гауссовской смеси в оптимизированной рамочной схеме XGBoost для обнаружения биполярного расстройства
Почему это важно для повседневного психического здоровья
Биполярное расстройство может радикально нарушить жизнь человека, но при этом часто остаётся незамеченным или неверно диагностируется годами. Многие люди переживают циклы интенсивных подъёмов и тяжёлых спадов, прежде чем получить правильную помощь. В этом исследовании рассматривается, как продвинутые вычислительные методы могут анализировать рутинные клинические анкеты и записи, чтобы раньше и надёжнее отмечать людей, у которых может быть биполярное расстройство. Работа нацелена на инструменты поддержки принятия решений, которые могут дополнять клиницистов, помогая им выявлять паттерны, которые людям легко упустить, но которые важны для своевременной помощи.

Задача выявления скрытых перепадов настроения
Биполярное расстройство проявляется по-разному у разных людей. Симптомы могут перекрываться с депрессией, тревогой и другими состояниями, а многие оценки зависят от воспоминаний пациента и интерпретации врача во время короткого приёма. В результате важные предвестники остаются незамеченными, и людям могут назначать лечение, не соответствующее их фактическому состоянию. Кроме того, в медицинских базах обычно гораздо меньше подтверждённых случаев биполярного расстройства, чем не-биполярных, что затрудняет стандартным компьютерным моделям изучение реальных проявлений болезни. Авторы утверждают, что нужны инструменты, способные справляться с этим дисбалансом, выявлять скрытые подгруппы пациентов и при этом оставаться понятными для клиницистов.
Умённый конвейер из простых блоков
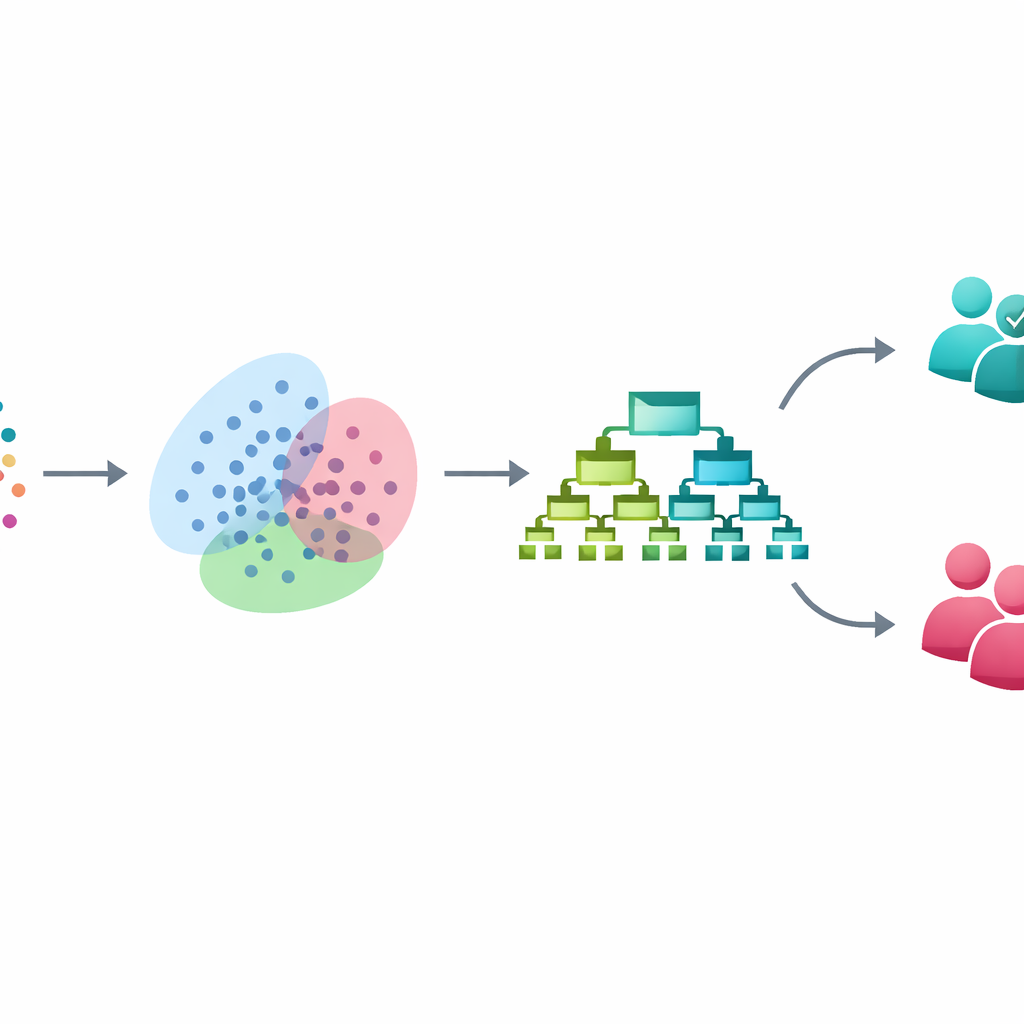
Вместо обращения к непрозрачным системам глубокого обучения исследователи построили пошаговый конвейер из трёх хорошо зарекомендовавших себя приёмов, каждый из которых решает конкретную задачу. Сначала они очищают и стандартизируют набор данных из 3 753 человек, каждый описан 54 клиническими и анкетными признаками, связанными с настроением, сном, поведением и функционированием. Затем они решают проблему неравного числа биполярных и не-биполярных случаев методом SMOTE. Вместо простого копирования редких биполярных записей SMOTE создаёт новые «промежуточные» примеры, аккуратно интерполируя между реальными пациентами с биполярным расстройством, что даёт модели более сбалансированный опыт обеих групп при обучении, при этом тестовые данные остаются нетронутыми.
Поиск скрытых групп внутри данных
После балансировки данных конвейер применяет моделирование гауссовой смеси — гибкий метод кластеризации, который ищет естественные группы пациентов без использования меток диагноза. Вместо того чтобы принудительно относить каждого человека к одной фиксированной группе, метод назначает вероятности принадлежности к нескольким пересекающимся кластерам, что отражает размытые границы, часто встречающиеся в реальной психиатрической практике. Эти вероятности затем добавляются как новые, тонкие признаки, описывающие положение каждого пациента среди скрытых подгрупп. Таким образом модель учится не только на прямых измерениях анкет, но и на более глубинных сходствах, которые могут соответствовать различным профилям симптомов или стадиям заболевания.
Преобразование паттернов в практические прогнозы
С таким обогащённым описанием каждого пациента финальный этап использует XGBoost — мощный ансамбль решающих деревьев, особенно эффективный для табличных клинических данных. Исследователи тщательно настраивают эту модель с помощью кросс-валидации и строго проводят все шаги балансировки и кластеризации внутри процесса обучения, чтобы избежать загрязнения тестовой выборки. На неиспользовавшихся при обучении данных их система правильно классифицирует биполярные и не-биполярные случаи в 93% случаев. Она выявляет 97% истинных биполярных случаев (высокая чувствительность), поддерживая точность 93% и сильный общий баланс между обнаружением реальных случаев и снижением ложных срабатываний. По сравнению с привычными методами, такими как логистическая регрессия, деревья решений, опорные векторы и случайные леса, новая схема улучшает показатели на 6–12 процентных пунктов в зависимости от сравнения.
Что это значит для пациентов и врачей
Для неспециалиста главный вывод таков: этот гибридный подход предлагает более надёжную систему раннего предупреждения, но не заменяет психиатра. Балансируя данные, выявляя скрытые подгруппы пациентов и используя интерпретируемую модель на основе деревьев, рамочная схема может отмечать людей с высокой вероятностью биполярного расстройства, чтобы клиницисты могли дальше проверять их по стандартным диагностическим руководствам, таким как DSM-5 или ICD-11. Авторы подчёркивают, что инструмент достаточно прозрачен, чтобы показать, какие клинические и подгрупповые признаки имеют наибольшее значение, что облегчает доверие и интеграцию в реальную практику. Хотя исследование основано на одной выборке и требует проверки в разных больницах и популяциях, оно демонстрирует, что продуманное сочетание нескольких скромных приёмов может дать практическую, масштабируемую помощь для более раннего и точного скрининга биполярного расстройства.
Цитирование: Kumar, S., Kumari, D., Panwar, A. et al. A hybrid SMOTE and Gaussian mixture model based optimized XGBoost framework for bipolar disorder detection. Sci Rep 16, 11887 (2026). https://doi.org/10.1038/s41598-026-39104-3
Ключевые слова: обнаружение биполярного расстройства, скрининг психического здоровья, машинное обучение в психиатрии, клиническая поддержка принятия решений, несбалансированные медицинские данные