Clear Sky Science · de
Ein hybrides SMOTE- und Gaußsches Mischmodell-basiertes optimiertes XGBoost-Framework zur Erkennung bipolarer Störungen
Warum das für die alltägliche psychische Gesundheit wichtig ist
Bipolare Störung kann das Leben einer Person stark beeinträchtigen, wird aber oft jahrelang übersehen oder falsch diagnostiziert. Viele Menschen durchlaufen Episoden intensiver Hochphasen und lähmender Tiefphasen, bevor sie die richtige Hilfe erhalten. Diese Studie untersucht, wie fortgeschrittene Computerverfahren routinemäßige klinische Fragebögen und Aufzeichnungen durchsieben können, um Personen, die möglicherweise an bipolarer Störung leiden, früher und verlässlicher zu identifizieren. Die Arbeit weist in Richtung Entscheidungsunterstützungswerkzeuge, die neben Klinikern eingesetzt werden könnten und dabei helfen, Muster zu erkennen, die für Menschen leicht zu übersehen, aber für rechtzeitige Versorgung entscheidend sind.

Die Herausforderung, verborgene Stimmungsschwankungen zu erkennen
Bipolare Störung zeigt sich nicht bei jeder Person gleich. Symptome können sich mit Depression, Angststörungen und anderen Zuständen überschneiden, und viele Bewertungen bauen auf dem, was Patienten berichten, sowie auf der Interpretation kurzer Arztbesuche auf. Dadurch werden wichtige Warnzeichen übersehen und Menschen erhalten möglicherweise Behandlungen, die nicht zu ihrem eigentlichen Zustand passen. Hinzu kommt, dass medizinische Datenbanken typischerweise deutlich weniger bestätigte bipolare Fälle als nicht-bipolare enthalten, was es Standard-Computermodellen erschwert, ein aussagekräftiges Bild bipolarer Störungen zu lernen. Die Autoren argumentieren, dass wir Werkzeuge brauchen, die mit diesem Ungleichgewicht umgehen, verborgene Patientensubgruppen aufdecken und zugleich für Klinikern nachvollziehbar bleiben.
Eine intelligente Pipeline aus einfachen Bausteinen
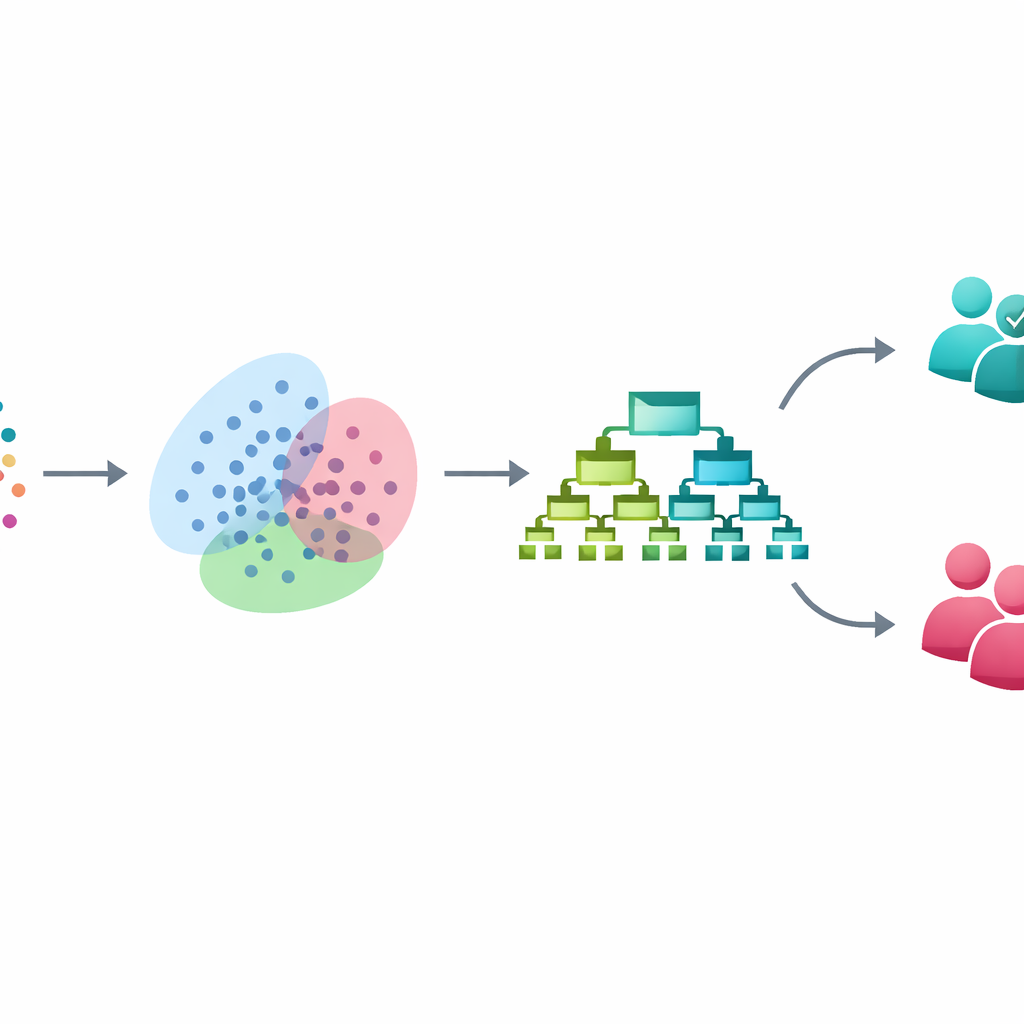
Statt auf undurchsichtige Deep-Learning-Systeme zurückzugreifen, bauen die Forschenden eine schrittweise Pipeline aus drei etablierten Techniken auf, von denen jede ein spezielles Problem löst. Zuerst bereinigen und standardisieren sie einen Datensatz mit 3.753 Personen, die jeweils durch 54 klinische und fragebogenartige Merkmale zu Stimmung, Schlaf, Verhalten und Funktion beschrieben sind. Dann adressieren sie die ungleichen Fallzahlen zwischen bipolaren und nicht-bipolaren Fällen mit einer Methode namens SMOTE. Anstatt seltene bipolare Fälle einfach zu duplizieren, erzeugt SMOTE neue „Zwischen“-Beispiele, indem es sanft zwischen realen bipolaren Patient*innen interpoliert, sodass das Modell während des Trainings ein ausgewogeneres Erlebnis beider Gruppen erhält, während die Testdaten unberührt bleiben.
Verborgene Gruppen in den Daten finden
Nach dem Ausgleichen der Daten wendet die Pipeline Gaußsche Mischmodellierung an, einen flexiblen Clustering-Ansatz, der nach natürlichen Gruppierungen unter den Patient*innen sucht, ohne die Diagnose-Labels zu verwenden. Anstatt jede Person in eine feste Schublade zu stecken, weist das Modell Wahrscheinlichkeiten zu, zu mehreren sich überschneidenden Gruppen zu gehören, und bildet so die oft unscharfen Grenzen der psychiatrischen Praxis ab. Diese Wahrscheinlichkeiten werden dann als neue, subtile Merkmale hinzugefügt, die die Position jeder Person innerhalb dieser verborgenen Subgruppen beschreiben. Effektiv lernt das Modell dadurch nicht nur aus dem, was die Fragebögen direkt messen, sondern auch aus tieferliegenden Ähnlichkeitsmustern, die unterschiedlichen Symptomprofilen oder Krankheitsstadien entsprechen könnten.
Muster in praktische Vorhersagen verwandeln
Mit dieser angereicherten Beschreibung jeder Person nutzt die letzte Stufe XGBoost, ein leistungsfähiges Ensemble aus Entscheidungsbäumen, das sich besonders gut für tabellarische klinische Daten eignet. Die Forschenden stimmen dieses Modell sorgfältig mittels Kreuzvalidierung ab und halten alle Ausgleichs- und Clustering-Schritte strikt innerhalb des Trainingsprozesses, um eine Kontamination des Testsets zu vermeiden. Bei unvertrauten Daten klassifiziert ihr System bipolare versus nicht-bipolare Fälle in 93 % der Fälle korrekt. Es identifiziert 97 % der tatsächlichen bipolaren Fälle (hohe Sensitivität) und erzielt dabei 93 % Präzision sowie ein starkes Gesamtgleichgewicht zwischen dem Erfassen echter Fälle und dem Vermeiden von Fehlalarmen. Im Vergleich zu gängigen Methoden wie logistischer Regression, Entscheidungsbäumen, Support-Vektor-Maschinen und Random Forests verbessert das neue Framework die Leistung je nach Vergleich um 6 bis 12 Prozentpunkte.
Was das für Patient*innen und Klinikende bedeutet
Für Laien ist die wichtigste Erkenntnis, dass dieser hybride Ansatz ein verlässlicheres Frühwarnsystem bieten kann, nicht jedoch ein Ersatz für eine*n Psychiater*in. Durch das Ausgleichen der Daten, das Aufdecken verborgener Patientensubgruppen und die Nutzung eines interpretierbaren baumbasierten Modells kann das Framework Personen markieren, die wahrscheinlich an bipolarer Störung leiden, damit Kliniker*innen mit standardisierten Diagnoseleitlinien wie DSM-5 oder ICD-11 weiter untersuchen können. Die Autor*innen betonen, dass das Werkzeug transparent genug ist, um aufzuzeigen, welche klinischen Merkmale und Subgruppenmerkmale am wichtigsten sind, was Vertrauen und Integration in die Versorgungspraxis erleichtert. Obwohl die Studie auf einem einzelnen Datensatz basiert und noch über Krankenhäuser und Populationen hinweg getestet werden muss, zeigt sie, dass die durchdachte Kombination mehrerer moderater Techniken eine praktische, skalierbare Hilfe für frühere und genauere Screenings bipolarer Störungen liefern kann.
Zitation: Kumar, S., Kumari, D., Panwar, A. et al. A hybrid SMOTE and Gaussian mixture model based optimized XGBoost framework for bipolar disorder detection. Sci Rep 16, 11887 (2026). https://doi.org/10.1038/s41598-026-39104-3
Schlüsselwörter: Erkennung bipolarer Störungen, Screening psychischer Gesundheit, Maschinelles Lernen in der Psychiatrie, klinische Entscheidungsunterstützung, unausgeglichene medizinische Daten