Clear Sky Science · sv
Batchdestillationsdata för utveckling av maskininlärningsmetoder för avvikelsedetektering
Varför det är viktigt att vakta mot problem i kemiska anläggningar
Kemiska anläggningar ligger tyst i bakgrunden och möjliggör mycket av det moderna livet — de tillverkar bränslen, läkemedel, plaster och otaliga vardagsprodukter. När något i dessa komplexa system går fel — en pump sätter igen, en ventil kärvar eller en sensor avdriftar — kan följderna variera från spill till farliga olyckor. Ingenjörer hoppas i allt högre grad använda modern artificiell intelligens för att automatiskt upptäcka tidiga varningssignaler. Men det finns ett grundläggande hinder: avancerade algoritmer behöver stora mängder högkvalitativa, verkliga data att lära sig av, och sådana data delas sällan utanför industrin. Denna artikel tar det hindret direkt genom att bygga en liten men sofistikerad destillationsanläggning i laboratoriet och använda den för att skapa och öppet publicera ett rikt dataset med både normal drift och noggrant konstruerade fel.
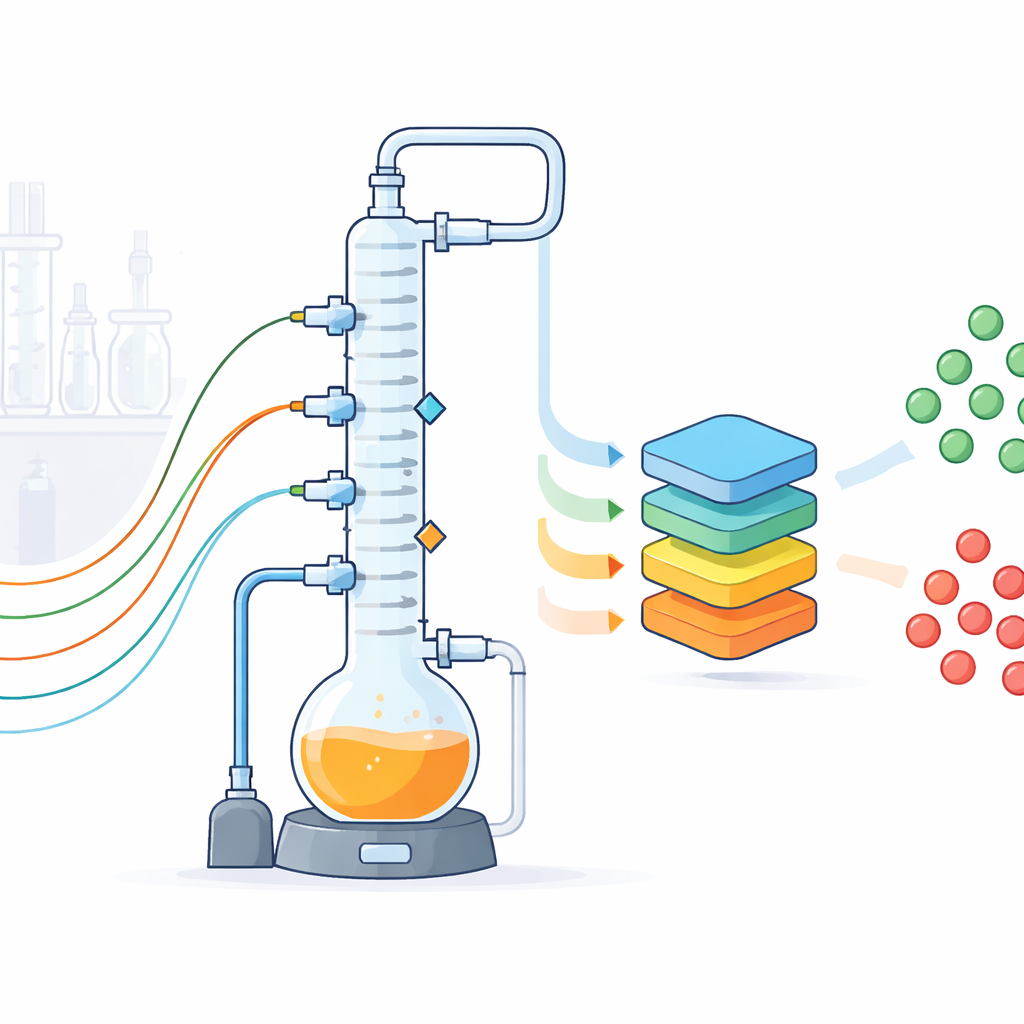
En bänkmodell som står in för en fullskalig kemisk anläggning
Forskarlaget konstruerade en partydestillationsanläggning med glasväggar som efterliknar ett vanligt industriellt separationssteg, där en uppvärmd blandning kokas och dess ångor separeras i en hög kolonn till lättare och tyngre komponenter. Deras laboratorieanläggning innehåller ett tvåliters kokkärl, en kolonn i tre sektioner packad för att förbättra separationen, kondensorer, pumpar och ett vakuumsystem som gör att de kan köra under atmosfärstryck. Utrustningen får plats på ett labbänk men är byggd för att bete sig som en nedskalad industriell enhet, med realistiska rörledningar, isolering och styrdon. Eftersom anläggningen är transparent, flexibel och lättillgänglig kan teamet experimentera fritt på sätt som skulle vara riskabla eller opraktiska i en fabrik.
Följer varje rörelse med många sorters sensorer
För att förvandla anläggningen till en datafabrik utrustade författarna den med en uppsättning konventionella och okonventionella sensorer. Standardinstrument mäter temperaturer på flera punkter upp och ner i kolonnen, tryck, vätskenivåer och flödeshastigheter för produkt, reflux och kylarvatten. Varje sensors noggrannhet och osäkerhet kalibrerades och dokumenterades. Utöver dessa spelar tre kameror in bilder av nyckelkärl och kondensorer varannan sekund, en mikrofon lyssnar på ljuden från pumpar och kokning, och en kompakt kärnmagnetresonans (NMR)-spektrometer följer kontinuerligt hur blandningens sammansättning förändras över tid. Ytterligare prover analyseras med gaskromatografi. Alla enheter knyts ihop av ett Python-baserat styrsystem som kör recept, loggar varje händelse och inställningsändring och strömmar avläsningar varje sekund till strukturerade filer, där saknade värden tydligt markeras.
Skapar och märker fel medvetet
Projektets kärna är inte bara att samla data från rutinella körningar, utan att medvetet få anläggningen att bete sig fel på kontrollerade sätt. I 119 experiment genomförde teamet både felfria och felaktiga körningar för flera flytande blandningar. Under drift introducerade de störningar som tillfälliga förändringar av värmarens effekt eller kolonntryck, förändrad kylning, rubbad refluxfördelning, inläggning av extra ämnen eller förvrängning av sensorsignaler. Varje störning leder till en ”avvikelse” — en synlig avvikelse i en eller flera sensorkurvor. Responsen delas naturligt in i tre faser: en initial blind fas där förändringen ännu inte syns i avläsningarna, en avvikelsefas där avvikelsen är tydlig, och en återhämtningsfas där systemet driver tillbaka mot normalt när felet avlägsnas. Några experiment återhämtar sig aldrig helt och efterliknar allvarliga industriella fel. För många avvikande körningar finns även en nära matchande normal körning under samma förhållanden.
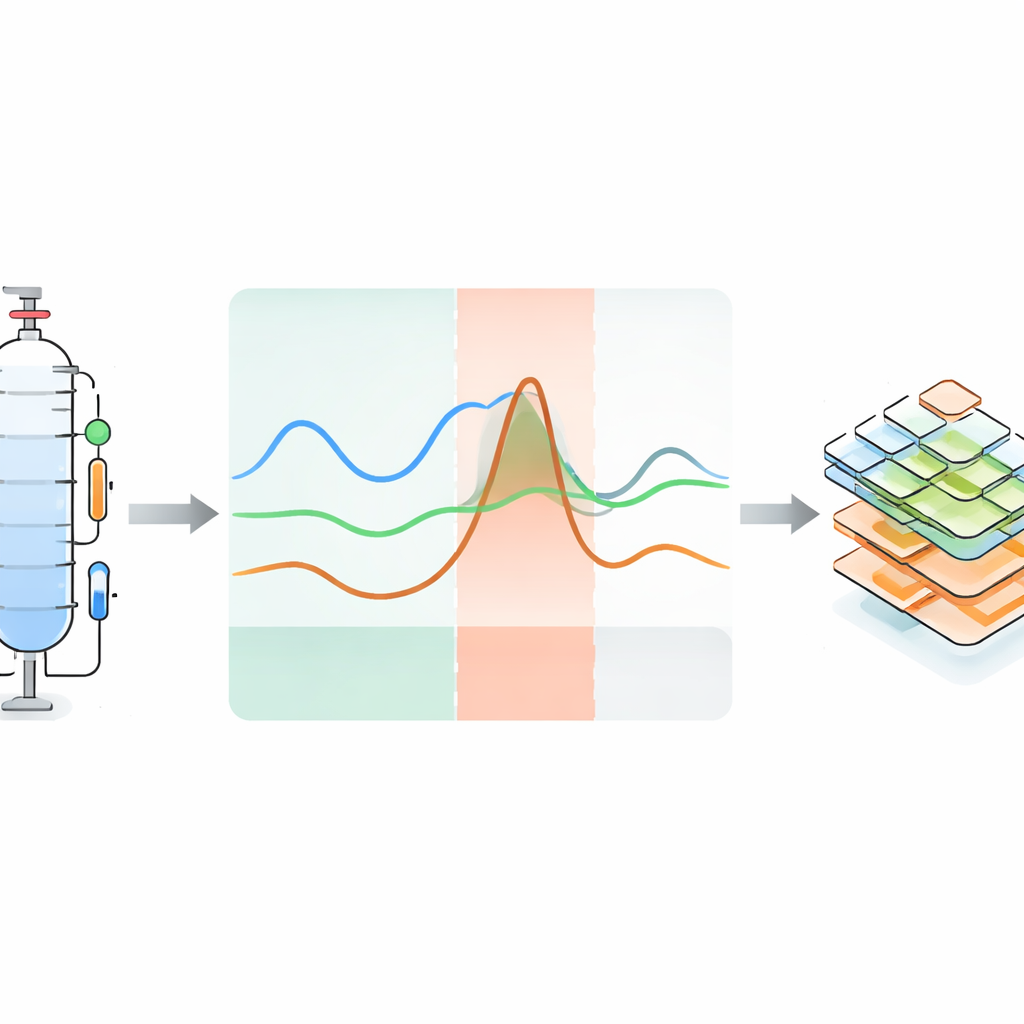
Gör processstörningar till maskinläsbar kunskap
Författarna insåg att siffror inte är nog och bifogar detaljerad metadata som förklarar vad som hände i varje avvikande körning och varför. De bygger vidare på befintliga ontologiramverk — formella vokabulärer för att beskriva sensorer, system och fel — för att koda, på ett strukturerat sätt, typen av störning, den drabbade komponenten, det observerbara utfallet och tidpunkten för varje fas. Dessa beskrivningar lagras i människoläsbara YAML-filer men är också maskininterpreterbara och länkar specifika avvikelser till specifika sensorer och delar av anläggningen. Datasetet är organiserat hierarkiskt: användare kan navigera från allmän information om anläggningen till särskilda maskinkonfigurationer och driftpunkter ner till individuella experiment med tillhörande tidsserier, bilder, ljud, NMR-data, osäkerhetsinformation och avvikelseannoteringar.
Sätter moderna AI-metoder på ett verkligt prov
För att visa datasetets värde och svårighetsgrad tillämpade författarna en rad toppmoderna metoder för avvikelsedetektering i tidsserier, inklusive prognosmodeller, rekonstruktionsbaserade angreppssätt, generativa modeller och hybrider som tidigare visat utmärkta resultat på en välkänd syntetisk referens kallad Tennessee-Eastman Process. På de simulerade dataen presterade dessa metoder återigen mycket bra. Men när de tränades på en delmängd av det nya experimentella batchdestillationsdatasetet och utvärderades med ett standardmått baserat på precision–recall föll deras prestanda kraftigt över hela linjen. Denna kontrast understryker hur mycket rörigare och mer utmanande verkliga processignaler är jämfört med idealiserade simuleringar, med rikare brus, subtila drifter och komplexa kopplingar mellan variabler.
Vad detta innebär för säkrare och smartare anläggningar
För en icke-specialist är huvudbudskapet att detta arbete tillhandahåller den saknade ”träningsmarken” som modern AI behöver för att bli verkligt användbar vid övervakning av kemiska operationer. Genom att öppet släppa en noggrant dokumenterad, multisensorisk registrering av en realistisk destillationsprocess — komplett med kända fel och expertexplikationer av deras orsaker — ger författarna forskare en gemensam, krävande testbädd. Framtida studier kan använda dessa data för att jämföra algoritmer, utveckla mer transparenta och förklarliga modeller och utforska strategier för att inte bara upptäcka avvikelser utan också förstå och mildra dem. På lång sikt kan framsteg byggda på dataset som detta hjälpa verkliga anläggningar att upptäcka problem tidigare, minska svinn och driva säkrare.
Citering: Arweiler, J., Jungjohann, I., Muraleedharan, A. et al. Batch Distillation Data for Developing Machine Learning Anomaly Detection Methods. Sci Data 13, 513 (2026). https://doi.org/10.1038/s41597-026-07124-3
Nyckelord: avvikelsedetektering, batchdestillation, kemiska processdata, maskininlärning, tidsseriedataset