Clear Sky Science · pl
Dane z destylacji wsadowej do opracowywania metod wykrywania anomalii w uczeniu maszynowym
Dlaczego obserwowanie problemów w zakładach chemicznych ma znaczenie
Zakłady chemiczne cicho wspierają nowoczesne życie, produkując paliwa, leki, tworzywa sztuczne i niezliczone produkty codziennego użytku. Jednak gdy coś w tych złożonych systemach zawodzi — gdy pompa się zapycha, zawór zaciąga lub czujnik dryfuje — konsekwencje mogą obejmować straty surowca aż po niebezpieczne wypadki. Inżynierowie coraz częściej liczą na nowoczesną sztuczną inteligencję, by automatycznie wykrywać wczesne sygnały ostrzegawcze. Istnieje jednak zasadnicza przeszkoda: zaawansowane algorytmy potrzebują dużych ilości wysokiej jakości, rzeczywistych danych do uczenia się, a takie dane rzadko są udostępniane poza przemysłem. Artykuł ten podejmuje tę przeszkodę wprost, budując niewielką, lecz zaawansowaną instalację destylacyjną w laboratorium i używając jej do stworzenia oraz otwartego udostępnienia bogatego zbioru danych obejmującego zarówno normalne zachowanie, jak i celowo wygenerowane usterki.
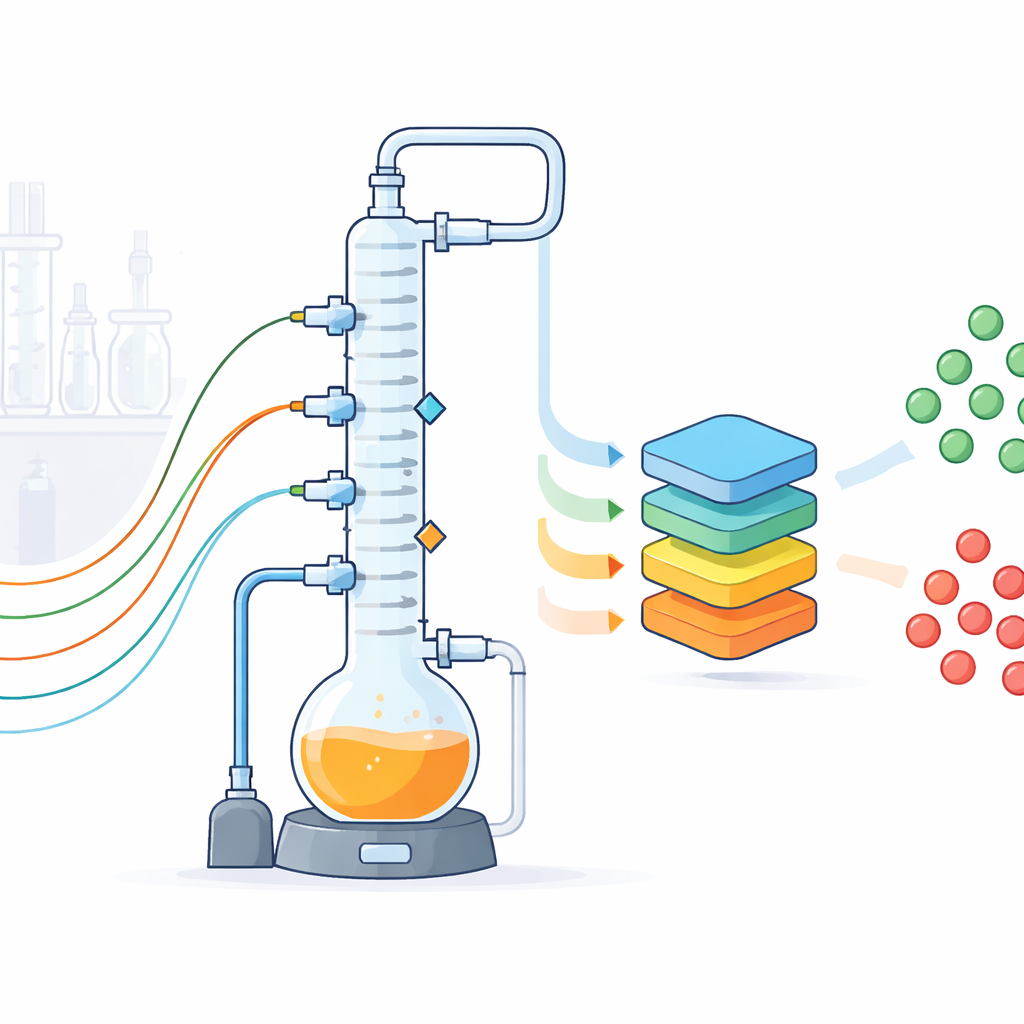
Stołowy substytut pełnego zakładu chemicznego
Badacze zaprojektowali szklany, ścienny układ destylacji wsadowej, który odwzorowuje powszechny przemysłowy etap separacji: podgrzewana mieszanina jest wrząca, a jej opary są rozdzielane w wysokiej kolumnie na komponenty lżejsze i cięższe. Laboratorium zawiera naczynie wrzenia o pojemności dwóch litrów, trójsekcyjną kolumnę wypełnioną elementami zwiększającymi separację, skraplacze, pompy i układ próżniowy pozwalający pracować poniżej ciśnienia atmosferycznego. Choć sprzęt mieści się na ławce laboratoryjnej, został zbudowany tak, by zachowywać się jak pomniejszona wersja jednostki przemysłowej, z realistycznym okablowaniem, izolacją i sprzętem sterującym. Dzięki temu, że instalacja jest przejrzysta, elastyczna i łatwo dostępna, zespół może eksperymentować swobodnie w sposób, który w fabryce byłby ryzykowny lub niepraktyczny.
Obserwowanie każdego ruchu wieloma rodzajami czujników
Aby przekształcić tę instalację w fabrykę danych, autorzy wyposażają ją w zestaw konwencjonalnych i niekonwencjonalnych czujników. Standardowe przyrządy mierzą temperatury w kilku punktach kolumny, ciśnienia, poziomy cieczy oraz przepływy produktu, refluksu i wody chłodzącej. Dokładność i niepewność każdego czujnika zostały skalibrowane i udokumentowane. Dodatkowo trzy kamery rejestrują obrazy kluczowych zbiorników i skraplaczy co dwie sekundy, mikrofon nasłuchuje dźwięków pomp i wrzenia, a kompaktowy spektrometr magnetycznego rezonansu jądrowego (NMR) ciągle śledzi zmiany składu mieszaniny w czasie. Dodatkowe próbki są analizowane chromatografią gazową. Wszystkie urządzenia są połączone systemem sterowania opartym na Pythonie, który uruchamia procedury, zapisuje każde zdarzenie i zmianę ustawienia oraz strumieniuje odczyty co sekundę do ustrukturyzowanych plików, z wyraźnie oznaczonymi brakującymi wartościami.
Tworzenie i etykietowanie usterek na zamówienie
Istotą projektu nie jest tylko zbieranie danych z rutynowych przebiegów, lecz umyślne wywoływanie nieprawidłowości w kontrolowany sposób. W trakcie 119 eksperymentów zespół przeprowadził zarówno przebiegi bezusterkowe, jak i z wadami dla kilku mieszanin ciekłych. Podczas pracy wprowadzano zaburzenia, takie jak chwilowa zmiana mocy grzałki lub ciśnienia w kolumnie, zmiana chłodzenia, zaburzenie podziału refluksu, dawkowanie dodatkowych substancji lub celowe zniekształcenie sygnałów czujników. Każde takie zaburzenie prowadzi do „anomalii” — widocznego odchylenia w jednym lub kilku przebiegach czujników. Reakcję naturalnie dzielono na trzy fazy: początkową fazę „ślepą”, gdy zmiana jeszcze nie pojawiła się w odczytach, fazę anomalii, gdy odchylenie jest wyraźne, oraz fazę odzyskiwania, gdy system wraca w stronę normy po usunięciu usterki. Niektóre eksperymenty nie powracają całkowicie do stanu początkowego, imitując poważne awarie przemysłowe. Dla wielu przebiegów anormalnych dostarczono także odpowiadający im przebieg normalny przeprowadzony w tych samych warunkach.
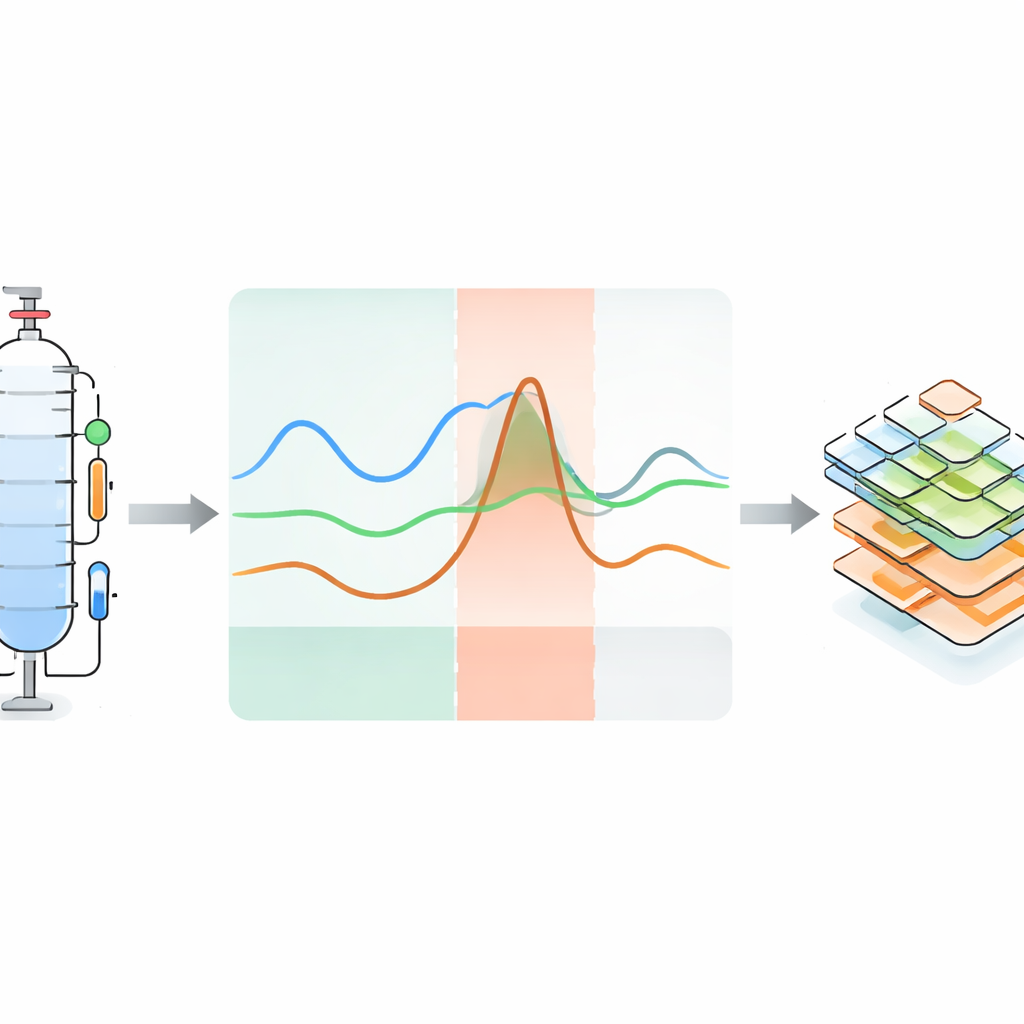
Przekształcanie zakłóceniem procesów w wiedzę czytelną dla maszyn
Autorzy zdają sobie sprawę, że same liczby to za mało, więc dołączają szczegółowe metadane wyjaśniające, co wydarzyło się w każdym przebiegu anormalnym i dlaczego. Opierają się na istniejących ramach ontologicznych — formalnych słownikach opisujących czujniki, systemy i awarie — aby w sposób ustrukturyzowany zakodować rodzaj perturbacji, dotknięty komponent, obserwowalny efekt oraz timing każdej fazy. Opisy te są przechowywane w plikach YAML czytelnych dla człowieka, ale także interpretowalnych przez maszyny, łącząc konkretne anomalie z konkretnymi czujnikami i częściami instalacji. Zbiór danych jest zorganizowany hierarchicznie: użytkownik może przechodzić od ogólnych informacji o instalacji, do szczególnych konfiguracji sprzętowych i punktów pracy, aż do pojedynczych eksperymentów z powiązanymi szeregami czasowymi, obrazami, dźwiękiem, danymi NMR, informacjami o niepewnościach i adnotacjami anomalii.
Wystawienie nowoczesnych metod AI na próbę w rzeczywistych warunkach
Aby pokazać wartość i trudność zbioru danych, autorzy zastosowali szereg nowoczesnych metod wykrywania anomalii w szeregach czasowych, w tym modele prognostyczne, podejścia oparte na rekonstrukcji, modele generatywne i hybrydy, które wcześniej osiągały znakomite wyniki na znanym sztucznym benchmarku zwanym Tennessee-Eastman Process. Na tych symulowanych danych metody ponownie uzyskały bardzo wysokie wyniki. Jednak po przeszkoleniu na podzbiorze nowych eksperymentalnych danych z destylacji wsadowej i ocenie za pomocą standardowej metryki precyzja–przypomnienie ich wydajność gwałtownie spadła. Kontrast ten podkreśla, jak znacznie bardziej złożone i trudniejsze są rzeczywiste sygnały procesowe w porównaniu z idealizowanymi symulacjami — zawierają bogatszy szum, subtelne dryfy i skomplikowane sprzężenia między zmiennymi.
Co to oznacza dla bezpieczniejszych i mądrzejszych zakładów
Dla osoby niespecjalizującej kluczowym wnioskiem jest to, że praca dostarcza brakującego „poligonu doświadczalnego”, którego nowoczesna AI potrzebuje, by stać się naprawdę użyteczna w monitorowaniu operacji chemicznych. Poprzez otwarte udostępnienie starannie udokumentowanego, wieloczujnikowego zapisu realistycznego procesu destylacji — z znanymi usterkami i eksperckimi wyjaśnieniami ich przyczyn — autorzy dają badaczom wspólny, wymagający test. Przyszłe badania mogą używać tych danych do porównywania algorytmów, opracowywania bardziej przejrzystych i wyjaśnialnych modeli oraz badania strategii nie tylko wykrywania anomalii, ale także ich zrozumienia i ograniczania. W dłuższej perspektywie postępy oparte na takich zbiorach danych mogą pomóc prawdziwym zakładom wcześniej wykrywać problemy, zmniejszać straty i działać bezpieczniej.
Cytowanie: Arweiler, J., Jungjohann, I., Muraleedharan, A. et al. Batch Distillation Data for Developing Machine Learning Anomaly Detection Methods. Sci Data 13, 513 (2026). https://doi.org/10.1038/s41597-026-07124-3
Słowa kluczowe: wykrywanie anomalii, destylacja wsadowa, dane z procesów chemicznych, uczenie maszynowe, zbiór danych szeregów czasowych