Clear Sky Science · pt
Dados de Destilação em Lotes para Desenvolver Métodos de Detecção de Anomalias por Aprendizado de Máquina
Por que é importante ficar de olho em problemas nas plantas químicas
Plantas químicas sustentam discretamente a vida moderna, produzindo combustíveis, medicamentos, plásticos e inúmeros produtos do dia a dia. Mas quando algo nesses sistemas complexos falha — quando uma bomba entope, uma válvula trava ou um sensor deriva — as consequências podem variar desde desperdício de material até acidentes perigosos. Engenheiros esperam cada vez mais usar inteligência artificial moderna para detectar automaticamente sinais de alerta precoce. Ainda assim existe um obstáculo básico: algoritmos avançados precisam de grandes quantidades de dados do mundo real, de alta qualidade, para aprender, e esses dados raramente são compartilhados fora da indústria. Este artigo enfrenta esse obstáculo de frente ao construir uma pequena, porém sofisticada, planta de destilação em laboratório e usá-la para criar e liberar publicamente um conjunto de dados rico contendo tanto comportamento normal quanto falhas cuidadosamente encenadas.
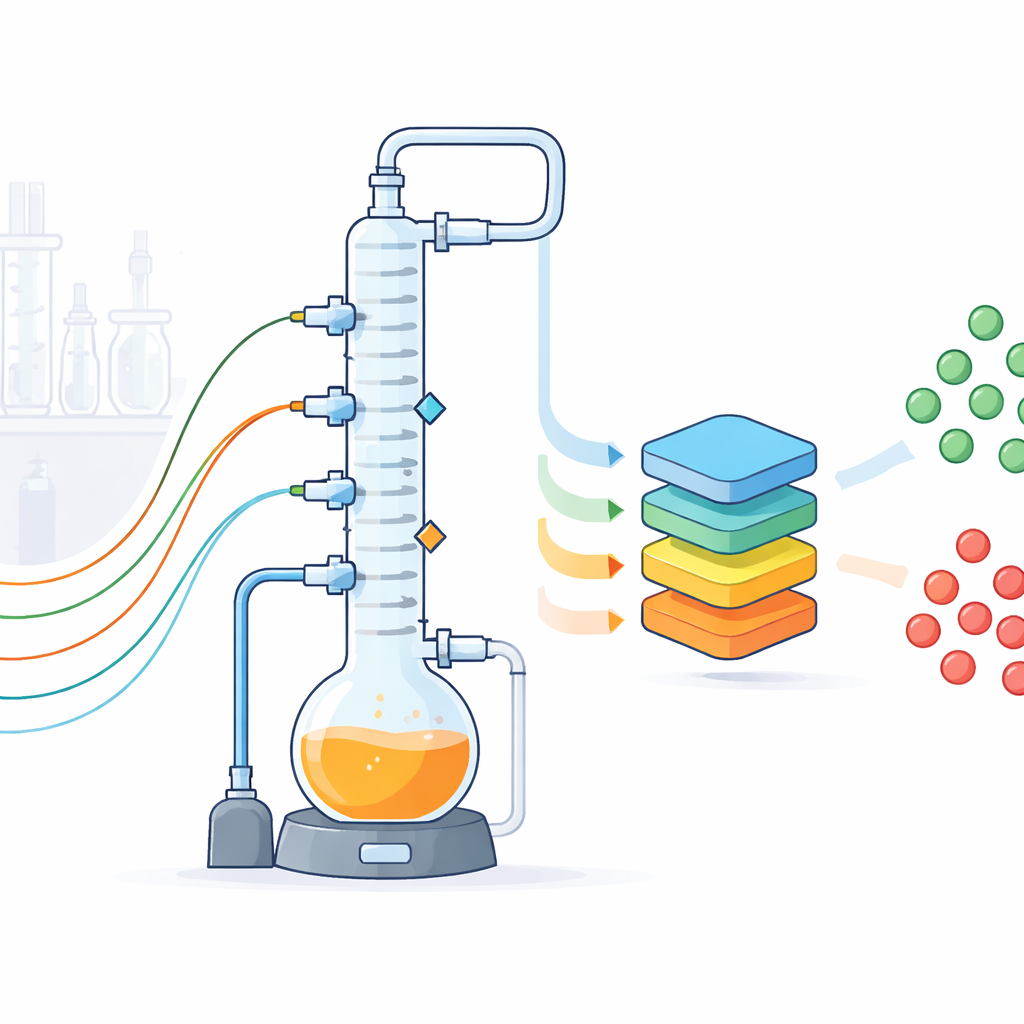
Um representante de bancada para uma planta química completa
Os pesquisadores projetaram um sistema de destilação em lotes com paredes de vidro que imita uma etapa de separação industrial comum, onde uma mistura aquecida é fervida e seus vapores são separados em uma coluna alta em componentes mais leves e mais pesados. A planta de laboratório inclui um vaso de ebulição de dois litros, uma coluna com três seções preenchidas para melhorar a separação, condensadores, bombas e um sistema de vácuo que permite operar abaixo da pressão atmosférica. Embora o equipamento caiba em uma bancada, ele foi construído para se comportar como uma unidade industrial em escala reduzida, com tubulação, isolamento e hardware de controle realistas. Como a planta é transparente, flexível e acessível, a equipe pode experimentar livremente de maneiras que seriam arriscadas ou impraticáveis em uma fábrica.
Monitorando cada movimento com vários tipos de sensores
Para transformar essa planta em uma fábrica de dados, os autores a equiparam com um conjunto de sensores convencionais e não convencionais. Instrumentos padrão medem temperaturas em vários pontos ao longo da coluna, pressões, níveis de líquido e vazões de produto, refluxo e água de resfriamento. A precisão e a incerteza de cada sensor foram calibradas e documentadas. Além disso, três câmeras registram imagens de vasos-chave e dos condensadores a cada dois segundos, um microfone capta os sons das bombas e da ebulição, e um espectrômetro compacto de ressonância magnética nuclear (RMN) acompanha continuamente como a composição da mistura muda ao longo do tempo. Amostras adicionais são analisadas por cromatografia gasosa. Todos os dispositivos são integrados por um sistema de controle baseado em Python que executa receitas, registra cada evento e alteração de ajuste, e transmite leituras a cada segundo para arquivos estruturados, com valores ausentes claramente sinalizados.
Criando e rotulando falhas de propósito
O cerne do projeto não é apenas coletar dados de corridas rotineiras, mas fazer a planta se comportar mal de forma deliberada e controlada. Em 119 experimentos, a equipe realizou execuções tanto sem falhas quanto com falhas para várias misturas líquidas. Durante a operação, introduziram perturbações como alteração temporária da potência do aquecedor ou da pressão da coluna, modificação do resfriamento, perturbação da divisão do refluxo, injeção de substâncias extras ou corrupção de sinais de sensores. Cada perturbação leva a uma “anomalia” — uma discrepância visível em uma ou mais curvas de sensores. A resposta se divide naturalmente em três fases: uma fase cega inicial em que a mudança ainda não aparece nas leituras, uma fase anômala em que a discrepância é clara, e uma fase de recuperação em que o sistema tende de volta ao normal depois que a falha é removida. Alguns experimentos nunca se recuperam totalmente, imitando falhas industriais graves. Para muitas execuções anômalas, também é fornecida uma execução normal correspondente sob as mesmas condições.
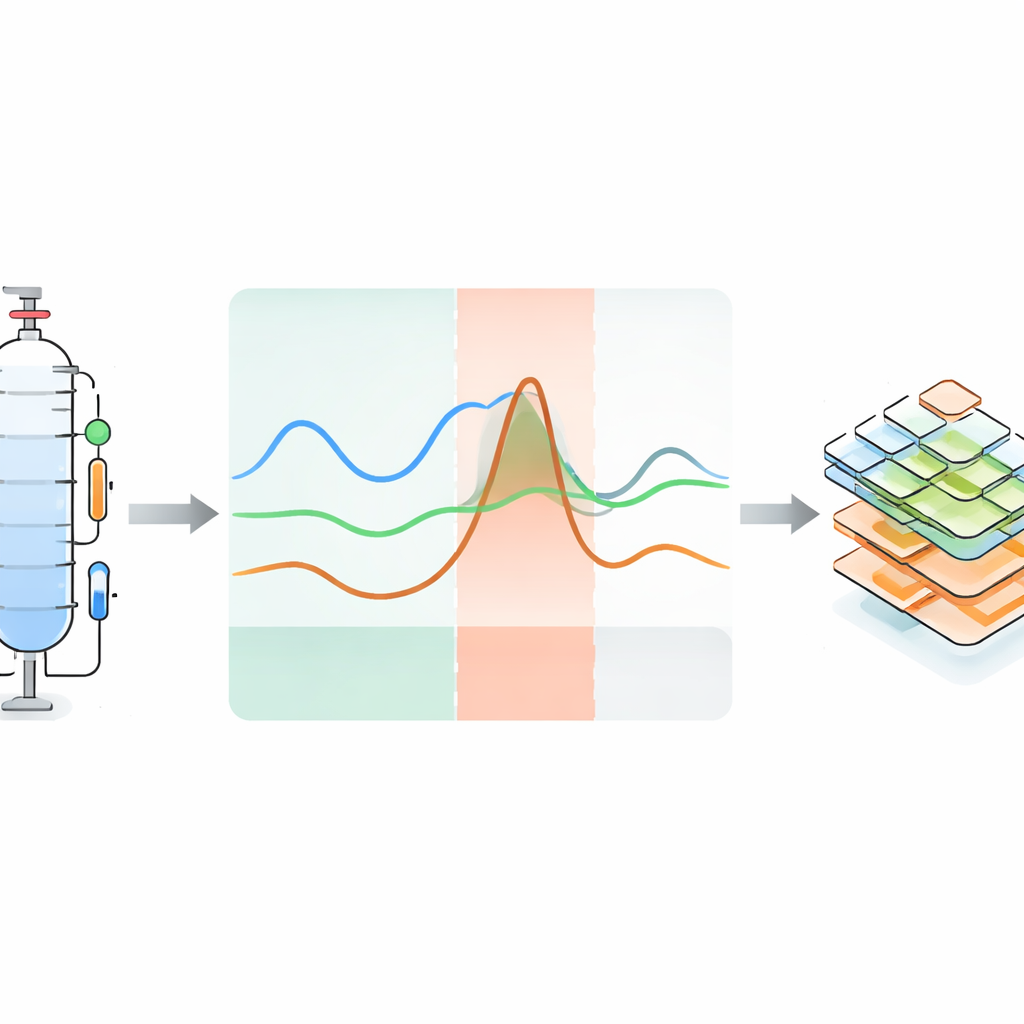
Transformando solavancos do processo em conhecimento legível por máquina
Reconhecendo que números sozinhos não são suficientes, os autores anexam metadados detalhados que explicam o que ocorreu em cada execução anômala e por quê. Eles se apoiam em estruturas de ontologia existentes — vocabulários formais para descrever sensores, sistemas e falhas — para codificar, de maneira estruturada, o tipo de perturbação, o componente afetado, o efeito observável e o momento de cada fase. Essas descrições são armazenadas em arquivos YAML legíveis por humanos, mas também são interpretáveis por máquinas, vinculando anomalias específicas a sensores e partes da planta. O conjunto de dados é organizado hierarquicamente: os usuários podem navegar desde informações gerais sobre a planta, para configurações de hardware e pontos de operação particulares, até experimentos individuais com séries temporais associadas, imagens, áudio, dados de RMN, informações de incerteza e anotações de anomalias.
Colocando métodos modernos de IA à prova no mundo real
Para demonstrar o valor e a dificuldade do conjunto de dados, os autores aplicaram uma variedade de métodos de detecção de anomalias em séries temporais de ponta, incluindo modelos de previsão, abordagens baseadas em reconstrução, modelos generativos e híbridos que anteriormente mostraram excelentes resultados em um conhecido benchmark sintético chamado Processo Tennessee‑Eastman. Naquele conjunto simulado, esses métodos novamente alcançaram pontuações muito altas. Mas quando treinados em um subconjunto dos novos dados experimentais de destilação em lotes e avaliados usando uma métrica padrão de precisão–recall, seu desempenho caiu acentuadamente em toda a linha. Esse contraste ressalta o quanto os sinais de processos reais são mais bagunçados e desafiadores em comparação com simulações idealizadas, com ruídos mais ricos, derivações sutis e acoplamentos complexos entre variáveis.
O que isso significa para plantas mais seguras e mais inteligentes
Para um leitor não especialista, a conclusão principal é que este trabalho fornece o “terreno de treinamento” que falta para que a IA moderna se torne realmente útil para monitorar operações químicas. Ao liberar abertamente um registro multissensor, cuidadosamente documentado, de um processo de destilação realista — completo com falhas conhecidas e explicações de especialistas sobre suas causas — os autores oferecem aos pesquisadores um campo de testes comum e exigente. Estudos futuros podem usar esses dados para comparar algoritmos, desenvolver modelos mais transparentes e explicáveis, e explorar estratégias não apenas para detectar anomalias, mas também para compreendê‑las e mitigá‑las. A longo prazo, avanços baseados em conjuntos de dados como este podem ajudar plantas reais a detectar problemas mais cedo, reduzir desperdícios e operar com mais segurança.
Citação: Arweiler, J., Jungjohann, I., Muraleedharan, A. et al. Batch Distillation Data for Developing Machine Learning Anomaly Detection Methods. Sci Data 13, 513 (2026). https://doi.org/10.1038/s41597-026-07124-3
Palavras-chave: detecção de anomalias, destilação em lotes, dados de processos químicos, aprendizado de máquina, conjunto de dados de séries temporais