Clear Sky Science · it
Dati di distillazione batch per sviluppare metodi di rilevamento delle anomalie con apprendimento automatico
Perché è importante sorvegliare i problemi negli impianti chimici
Gli impianti chimici sostengono silenziosamente la vita moderna, producendo carburanti, farmaci, materie plastiche e innumerevoli prodotti di uso quotidiano. Ma quando qualcosa in questi sistemi complessi va storto — una pompa si ottura, una valvola si blocca o un sensore deriva — le conseguenze possono spaziare dallo spreco di materiale ad incidenti pericolosi. Gli ingegneri sperano sempre più di usare l’intelligenza artificiale moderna per individuare automaticamente segnali precoci di guasto. Tuttavia esiste un ostacolo fondamentale: gli algoritmi avanzati richiedono grandi quantità di dati reali e di alta qualità per apprendere, e tali dati raramente vengono condivisi al di fuori dell’industria. Questo articolo affronta direttamente l’ostacolo costruendo un piccolo ma sofisticato impianto di distillazione in laboratorio e usandolo per creare e rendere pubblicamente disponibile un ricco dataset contenente sia comportamenti normali che guasti studiati appositamente.
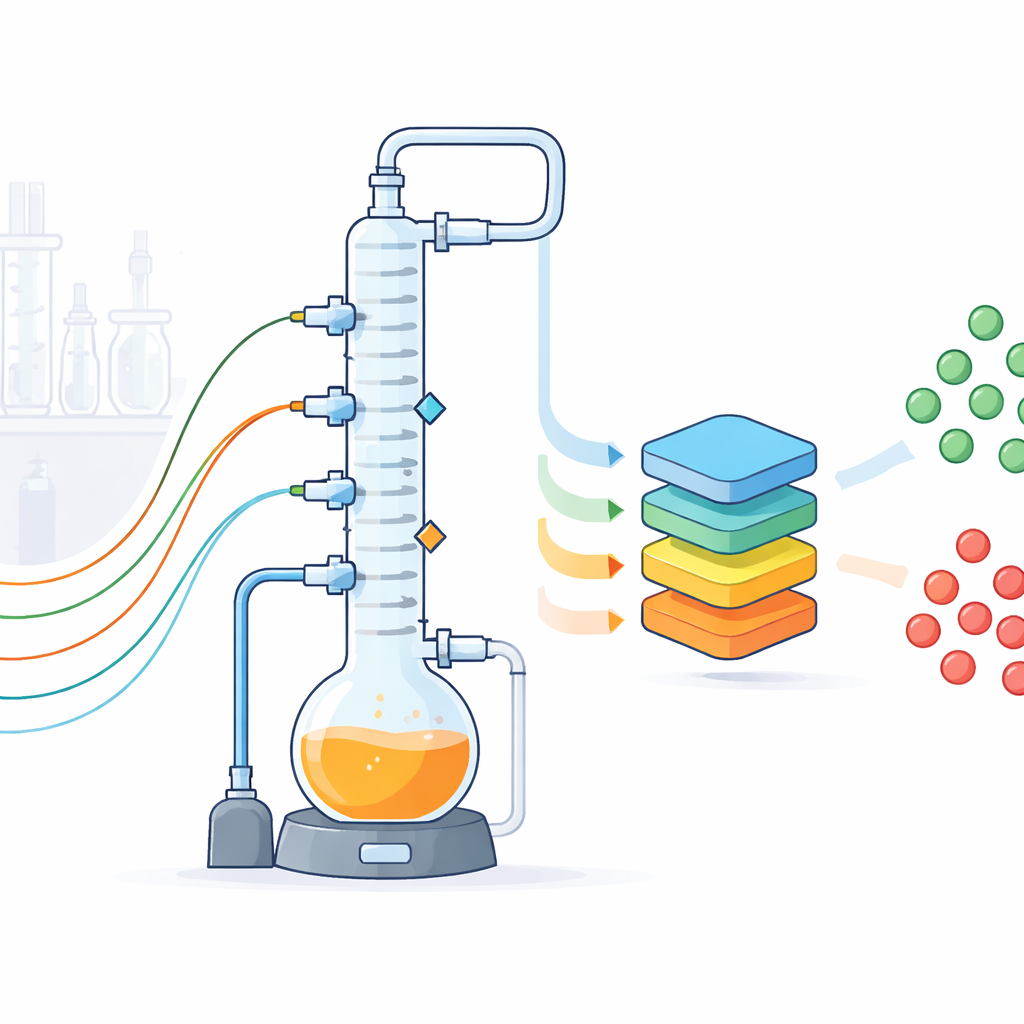
Un banco prova che riproduce un impianto chimico completo
I ricercatori hanno progettato un impianto di distillazione batch a pareti di vetro che imita un comune stadio di separazione industriale, in cui una miscela riscaldata viene fatta bollire e i vapori sono separati in una colonna alta in componenti più leggeri e più pesanti. Il loro impianto di laboratorio include un recipiente di ebollizione da due litri, una colonna a tre sezioni riempita per migliorare la separazione, condensatori, pompe e un sistema a vuoto che consente di operare sotto pressione atmosferica. Pur essendo adatto a un banco di laboratorio, l’apparecchiatura è costruita per comportarsi come un’unità industriale in scala ridotta, con tubazioni realistiche, isolamento e componenti di controllo. Poiché l’impianto è trasparente, flessibile e accessibile, il team può sperimentare liberamente in modi che sarebbero rischiosi o impraticabili in uno stabilimento.
Osservare ogni movimento con molti tipi di sensori
Per trasformare questo impianto in una fabbrica di dati, gli autori l’hanno dotato di una serie di sensori convenzionali e non convenzionali. Strumenti standard misurano le temperature in più punti lungo la colonna, pressioni, livelli di liquido e portate di prodotto, reflusso e acqua di raffreddamento. L’accuratezza e l’incertezza di ciascun sensore sono state calibrate e documentate. Oltre a questi, tre telecamere registrano immagini dei recipienti chiave e dei condensatori ogni due secondi, un microfono ascolta i suoni di pompe e bollitura e uno spettrometro a risonanza magnetica nucleare (NMR) compatto monitora continuamente come la composizione della miscela cambia nel tempo. Campioni aggiuntivi vengono analizzati con gascromatografia. Tutti i dispositivi sono collegati da un sistema di controllo basato su Python che esegue ricette, registra ogni evento e variazione di impostazione e invia letture ogni secondo in file strutturati, con i valori mancanti chiaramente segnalati.
Creare e etichettare volontariamente i guasti
Il cuore del progetto non è solo raccogliere dati da corse di routine, ma provocare intenzionalmente comportamenti anomali in modo controllato. In 119 esperimenti, il team ha eseguito manche sia prive di guasti sia difettose per diverse miscele liquide. Durante il funzionamento hanno introdotto perturbazioni come la modifica temporanea della potenza del riscaldatore o della pressione della colonna, alterazioni del raffreddamento, interferenze nella frazione di reflusso, iniezione di sostanze extra o corruzione dei segnali dei sensori. Ciascuna perturbazione dà luogo a un “anomalía” — una deviazione visibile in una o più tracce dei sensori. La risposta si divide naturalmente in tre fasi: una fase iniziale cieca in cui il cambiamento non si è ancora manifestato nelle misure, una fase anomala in cui la deviazione è chiara e una fase di recupero in cui il sistema ritorna verso la normalità una volta rimosso il guasto. Alcuni esperimenti non si riprendono completamente, imitando guasti industriali gravi. Per molte corse anomale è fornita anche una corsa normale corrispondente nelle stesse condizioni.
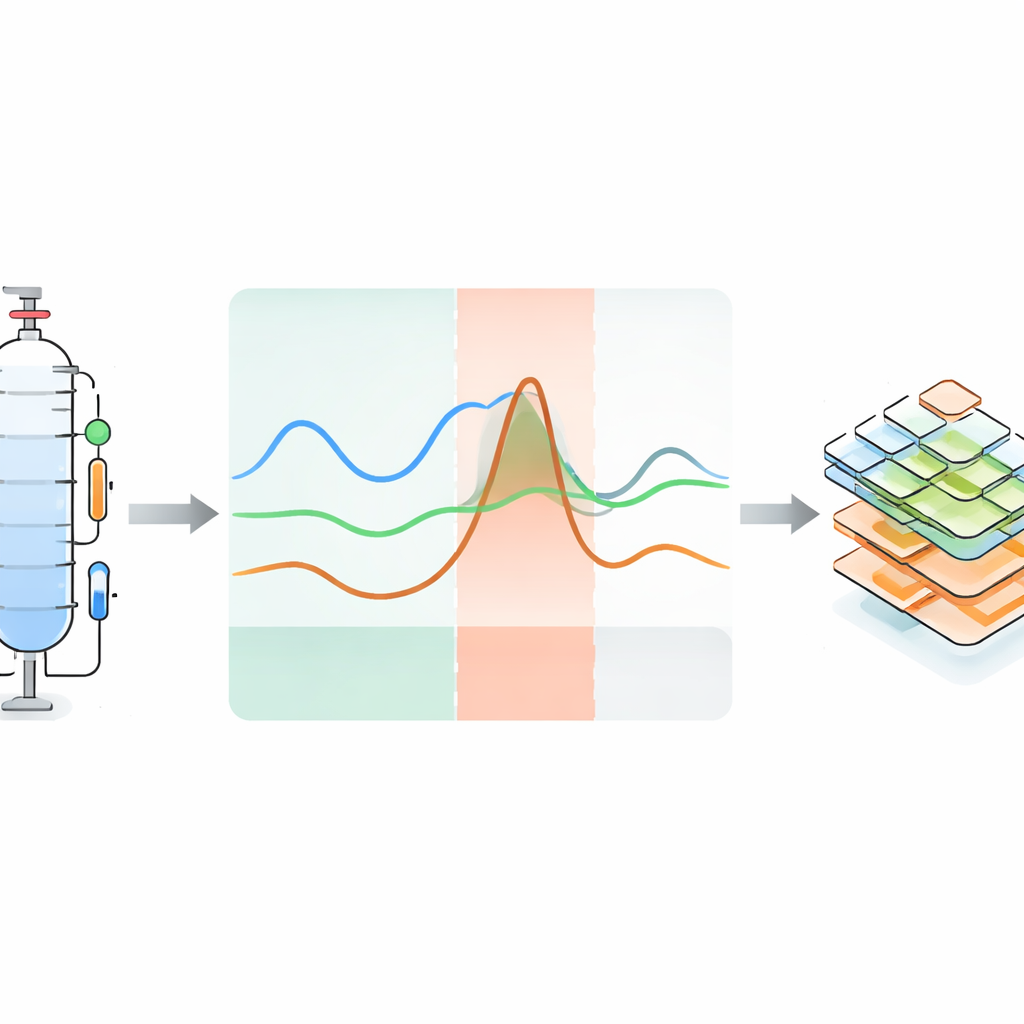
Convertire i problemi di processo in conoscenza leggibile dalle macchine
Consapevoli che i numeri da soli non bastano, gli autori allegano metadati dettagliati che spiegano cosa è accaduto in ogni corsa anomala e perché. Si basano su framework ontologici esistenti — vocabolari formali per descrivere sensori, sistemi e guasti — per codificare, in modo strutturato, il tipo di perturbazione, il componente interessato, l’effetto osservabile e la tempistica di ciascuna fase. Queste descrizioni sono archiviate in file YAML leggibili dall’uomo ma anche interpretabili da macchine, collegando anomalie specifiche a sensori e parti specifiche dell’impianto. Il dataset è organizzato gerarchicamente: gli utenti possono navigare dalle informazioni generali sull’impianto, a configurazioni hardware e punti di esercizio particolari, fino ai singoli esperimenti con le serie temporali associate, immagini, audio, dati NMR, informazioni sulle incertezze e annotazioni delle anomalie.
Mettere i metodi di IA moderni alla prova nel mondo reale
Per dimostrare il valore e la difficoltà del dataset, gli autori hanno applicato una gamma di metodi all’avanguardia per il rilevamento delle anomalie su serie temporali, inclusi modelli di previsione, approcci basati sulla ricostruzione, modelli generativi e ibridi che in precedenza avevano ottenuto ottimi risultati su un noto benchmark sintetico chiamato Tennessee-Eastman Process. Su quei dati simulati, questi metodi avevano nuovamente ottenuto punteggi molto alti. Ma quando sono stati addestrati su un sottoinsieme dei nuovi dati sperimentali di distillazione batch e valutati con una metrica standard precision–recall, le loro prestazioni sono diminuite drasticamente in tutti i casi. Questo contrasto sottolinea quanto siano più rumorosi e complicati i segnali dei processi reali rispetto alle simulazioni idealizzate, con rumore più ricco, derive sottili e accoppiamenti complessi tra variabili.
Cosa significa per impianti più sicuri e intelligenti
Per un non specialista, la conclusione principale è che questo lavoro fornisce il “campo di addestramento” mancante di cui l’IA moderna ha bisogno per diventare davvero utile nel monitoraggio delle operazioni chimiche. Rendendo pubblici dei registri multisensore accuratamente documentati di un processo di distillazione realistico — completi di guasti noti e spiegazioni esperte delle loro cause — gli autori offrono ai ricercatori una piattaforma di prova comune e impegnativa. Studi futuri potranno usare questi dati per confrontare algoritmi, sviluppare modelli più trasparenti e spiegabili ed esplorare strategie non solo per rilevare le anomalie ma anche per comprenderle e mitigarle. A lungo termine, i progressi basati su dataset di questo tipo potrebbero aiutare gli impianti reali a individuare i problemi prima, ridurre gli sprechi e operare in modo più sicuro.
Citazione: Arweiler, J., Jungjohann, I., Muraleedharan, A. et al. Batch Distillation Data for Developing Machine Learning Anomaly Detection Methods. Sci Data 13, 513 (2026). https://doi.org/10.1038/s41597-026-07124-3
Parole chiave: rilevamento anomalie, distillazione batch, dati di processo chimico, apprendimento automatico, dataset di serie temporali