Clear Sky Science · nl
Batchdestillatiegegevens voor het ontwikkelen van machine learning-methoden voor anomaliedetectie
Waarom het belangrijk is om in chemische fabrieken op problemen te letten
Chemische fabrieken vormen stilletjes de basis van het moderne leven: ze produceren brandstoffen, medicijnen, kunststoffen en talloze alledaagse producten. Maar als er iets misgaat in deze complexe systemen—een pomp raakt verstopt, een klep blijft hangen of een sensor raakt ontregeld—kan dat variëren van verspilde grondstoffen tot gevaarlijke ongevallen. Ingenieurs hopen steeds vaker moderne kunstmatige intelligentie te gebruiken om vroegtijdig automatisch waarschuwingssignalen te herkennen. Er is echter een fundamenteel obstakel: geavanceerde algoritmen hebben grote hoeveelheden hoogwaardige, real-world data nodig om van te leren, en zulke data worden zelden buiten de industrie gedeeld. Dit artikel pakt dat probleem rechtstreeks aan door een kleine maar geavanceerde destillatie-installatie in het lab te bouwen en die te gebruiken om een rijk dataset van zowel normaal gedrag als zorgvuldig geïntroduceerde storingen te creëren en openbaar vrij te geven.
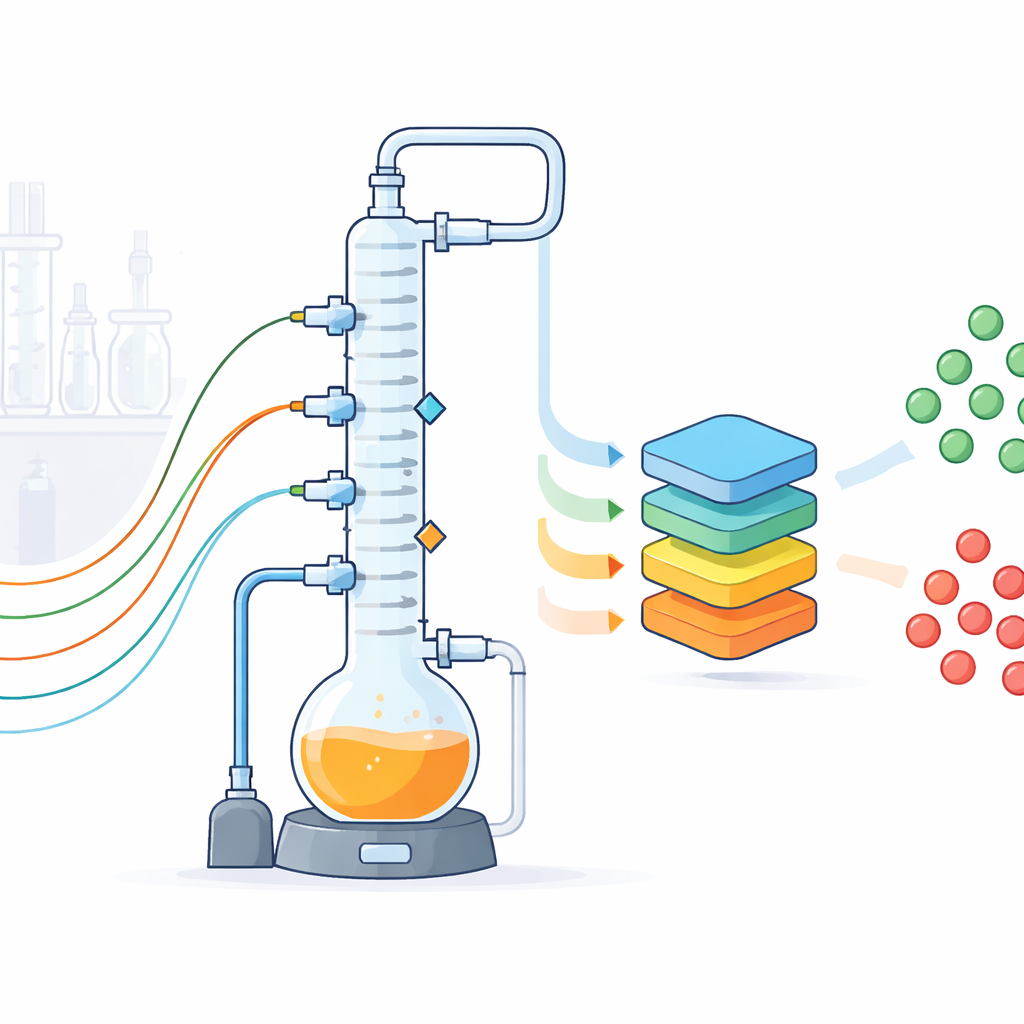
Een tafelmodel als stand-in voor een volledige chemische fabriek
De onderzoekers ontwierpen een batchdestillatie-opstelling met glazen wanden die een veelvoorkomende industriële scheidingsstap nabootst: een verwarmde mengsel wordt gekookt en de dampen worden in een hoge kolom gescheiden in lichtere en zwaardere componenten. Hun laboratoriuminstallatie omvat een twee-liter kookvat, een kolom met drie secties die is opgevuld om de scheiding te verbeteren, condensors, pompen en een vacuümsysteem waarmee ze onder atmosferische druk kunnen werken. Hoewel de apparatuur op een labbank past, is ze gebouwd om zich te gedragen als een verkleinde industriële eenheid, met realistische leidingen, isolatie en besturingshardware. Omdat de installatie transparant, flexibel en goed toegankelijk is, kan het team vrij experimenteren op manieren die in een fabriek riskant of onpraktisch zouden zijn.
Elke beweging volgen met veel verschillende soorten sensoren
Om van deze installatie een gegevensfabriek te maken, rustten de auteurs deze uit met een reeks conventionele en onconventionele sensoren. Standaardinstrumenten meten temperaturen op verschillende punten langs de kolom, drukken, vloeistofniveaus en debieten van product, reflux en koelwater. De nauwkeurigheid en onzekerheid van elke sensor werden gekalibreerd en gedocumenteerd. Daarbovenop nemen drie camera’s elke twee seconden beelden op van belangrijke vaten en de condensors, een microfoon luistert naar het geluid van pompen en koken, en een compacte kernspinresonantie (NMR)-spectrometer volgt continu hoe de samenstelling van het mengsel in de tijd verandert. Extra monsters worden geanalyseerd met gaschromatografie. Alle apparaten zijn gekoppeld via een op Python gebaseerd besturingssysteem dat recepturen uitvoert, elk evenement en elke instelling wijziging logt, en elke seconde metingen naar gestructureerde bestanden streamt, waarbij ontbrekende waarden duidelijk worden gemarkeerd.
Opzettelijk storingen creëren en labelen
De kern van het project is niet alleen het verzamelen van gegevens tijdens routinematige runs, maar het opzettelijk laten afwijkingen van de installatie op gecontroleerde wijze. In 119 experimenten voerde het team zowel foutvrije als foutieve runs uit voor meerdere vloeistofmengsels. Tijdens de werking introduceerden ze verstoringen zoals het tijdelijk veranderen van de verwarmingsvermogen of kolomdruk, het aanpassen van de koeling, het verstoren van de refluxverdeling, het injecteren van extra stoffen of het corrupt maken van sensorsignalen. Elke verstoring leidt tot een “anomalie”—een zichtbare afwijking in een of meer sensorkrommen. De respons is natuurlijk verdeeld in drie fasen: een initiële blinde fase waarin de verandering nog niet in de metingen zichtbaar is, een anomaliefase waarin de afwijking duidelijk is, en een herstel fase waarin het systeem terugdrijft richting normaal zodra de storing is verwijderd. Sommige experimenten herstellen nooit volledig, wat ernstige industriële storingen nabootst. Voor veel anomalieruns is er ook een nauw overeenkomende normale run onder dezelfde omstandigheden beschikbaar.
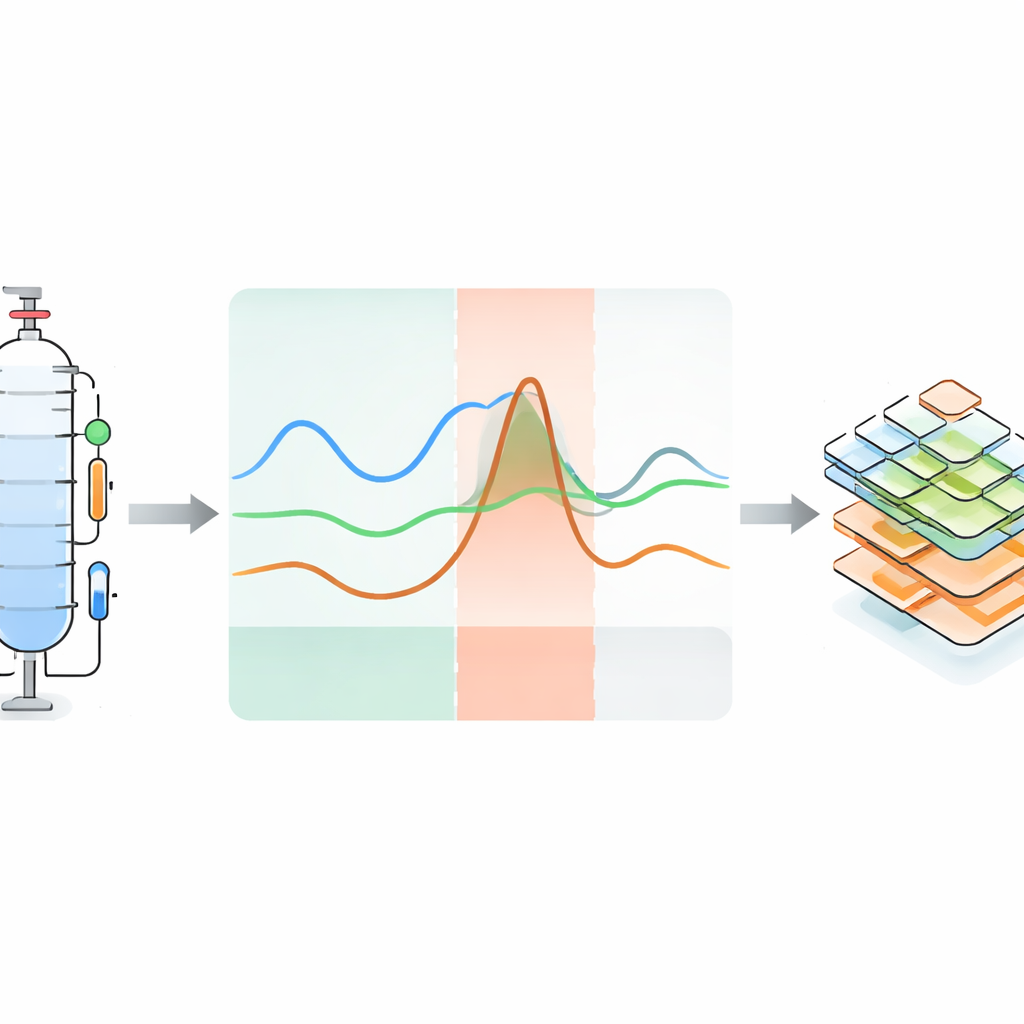
Proceshaperingen omzetten in machineleesbare kennis
De auteurs beseffen dat cijfers alleen niet voldoende zijn en voegen gedetailleerde metadata toe die uitleggen wat er in elke anomalierun gebeurde en waarom. Ze bouwen voort op bestaande ontologie-frameworks—formele woordenschatten om sensoren, systemen en storingen te beschrijven—om op gestructureerde wijze het type verstoring, het getroffen component, het observeerbare effect en de timing van elke fase vast te leggen. Deze beschrijvingen worden opgeslagen in menselijk leesbare YAML-bestanden maar zijn ook machine-interpretabel, waarbij specifieke anomalieën worden gekoppeld aan specifieke sensoren en delen van de installatie. De dataset is hiërarchisch georganiseerd: gebruikers kunnen navigeren van algemene informatie over de installatie, naar specifieke hardwareconfiguraties en bedrijfsinstellingen, tot individuele experimenten met bijbehorende tijdreeksen, beelden, audio, NMR-gegevens, onzekerheidsinformatie en anomalieannotaties.
Moderne AI-methoden aan een real-world test onderwerpen
Om de waarde en de moeilijkheidsgraad van de dataset aan te tonen, pasten de auteurs een reeks state-of-the-art methoden voor anomaliedetectie in tijdreeksen toe, waaronder voorspellingsmodellen, reconstructie-gebaseerde benaderingen, generatieve modellen en hybriden die eerder uitstekende resultaten hadden laten zien op een bekend synthetisch benchmark genaamd het Tennessee-Eastman Process. Op die gesimuleerde data behaalden deze methoden opnieuw zeer hoge scores. Maar wanneer ze werden getraind op een subset van de nieuwe experimentele batchdestillatiegegevens en geëvalueerd met een standaard precision–recall-metriek, daalde hun prestatie scherp over de hele linie. Dit contrast benadrukt hoe veel rommeliger en uitdagender echte processignalen zijn vergeleken met geïdealiseerde simulaties, met rijkere ruis, subtiele drifts en complexe koppelingen tussen variabelen.
Wat dit betekent voor veiligere en slimere installaties
Voor niet-specialisten is de belangrijkste conclusie dat dit werk het ontbrekende “oefenterrein” levert dat moderne AI nodig heeft om echt nuttig te worden voor het monitoren van chemische processen. Door openlijk een zorgvuldig gedocumenteerd, multisensorig verslag van een realistisch destillatieproces vrij te geven—compleet met bekende storingen en deskundige verklaringen van hun oorzaken—geven de auteurs onderzoekers een gemeenschappelijke, veeleisende testomgeving. Toekomstige onderzoeken kunnen deze gegevens gebruiken om algoritmen te benchmarken, meer transparante en uitlegbare modellen te ontwikkelen en strategieën te verkennen om niet alleen anomalieën te detecteren, maar ze ook te begrijpen en te mitigeren. Op de lange termijn kunnen op datasets als deze gebaseerde vooruitgangen echte installaties helpen problemen eerder te ontdekken, afval te verminderen en veiliger te werken.
Bronvermelding: Arweiler, J., Jungjohann, I., Muraleedharan, A. et al. Batch Distillation Data for Developing Machine Learning Anomaly Detection Methods. Sci Data 13, 513 (2026). https://doi.org/10.1038/s41597-026-07124-3
Trefwoorden: anomaliendetectie, batchdestillatie, gegevens van chemische processen, machine learning, tijdsreeksdataset