Clear Sky Science · sv
ReactionSeek: LLM-driven gruvdrift i litteraturdata och kunskapsupptäckt inom organisk syntes
Varför det spelar roll att göra gamla kemirapporter till data
Moderna genombrott inom medicin, material och grön teknik förlitar sig i ökande grad på datorer för att hitta mönster och föreslå nya molekyler. Men det mesta av kemisk kunskap ligger fortfarande begravd i ett århundrades forskningsartiklar, skrivna för människor snarare än maskiner. Den här artikeln presenterar ReactionSeek, ett system som lär artificiell intelligens att läsa dessa artiklar, plocka ut viktiga experimentella detaljer och omvandla dem till organiserad data. För alla som är intresserade av hur AI förändrar vetenskapen — från läkemedelsupptäckt till renare tillverkning — visar detta arbete hur vi slutligen kan låsa upp det omfattande ”dolda arkivet” inom kemi.
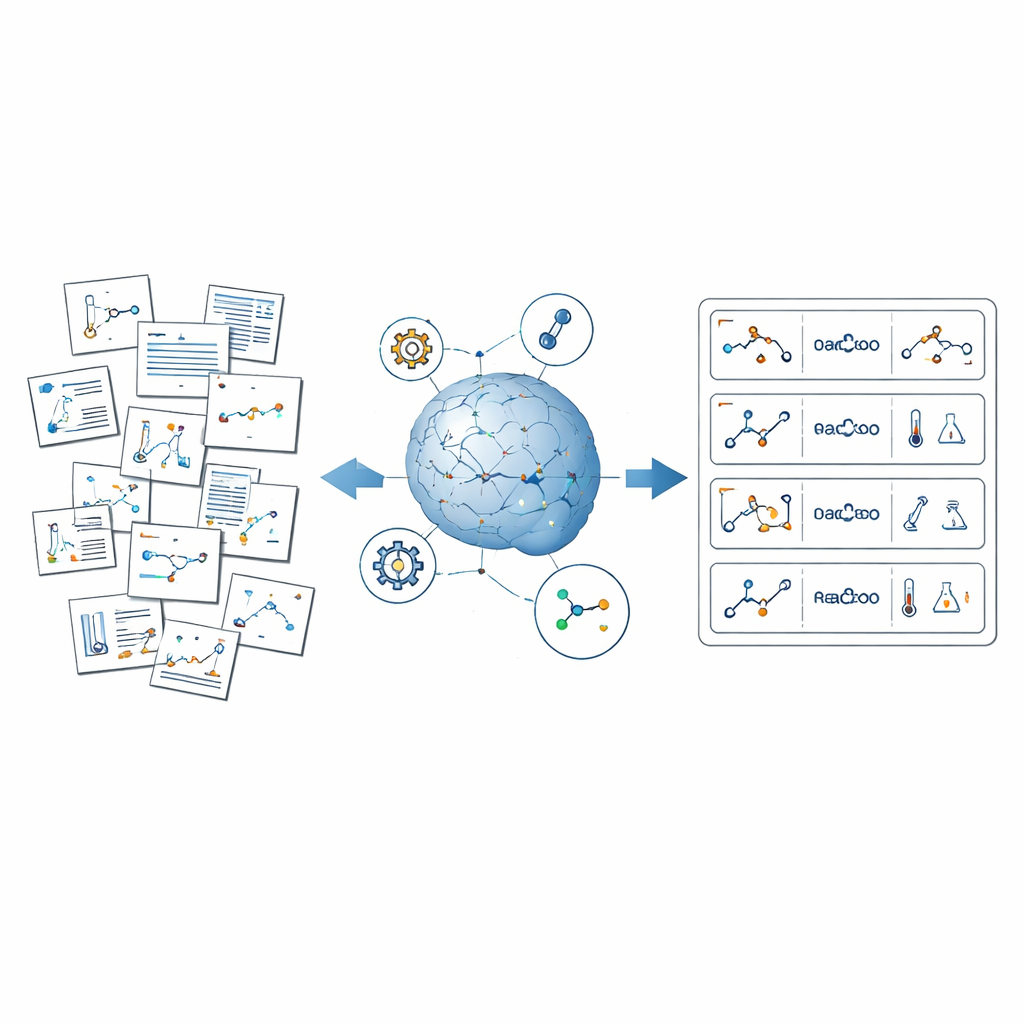
Problemet med dold kemisk kunskap
Organisk syntes, hantverket att bygga komplexa molekyler från enkla utgångsmaterial, står i centrum för kemin. Forskare har publicerat tiotusentals detaljerade recept som beskriver vilka ingredienser de använde, i vilka mängder, vid vilken temperatur och med vilken framgång. Ändå är denna information spridd över löpande text, diagram, tabeller och kompletterande filer. Befintliga databaser täcker bara en bråkdel av detta landskap, är ofta proprietära och missar ibland ovanliga reaktioner. Automatiserade laborationer kan generera välordnade dataset, men de är dyra och utforskar endast ett begränsat kemiskt område. Som en följd tränas många AI-verktyg på förenklad, städad data och kan inte fullt ut återspegla det röriga rikedom som kännetecknar verkligt laboratoriearbete.
En ny metod för att lära AI läsa kemiska artiklar
ReactionSeek tacklar denna utmaning genom att kombinera stora språkmodeller — AI-system tränade för att förstå och generera text och bilder — med specialiserad kemisk programvara. Ramverket fungerar som en automatiserad läsare som går igenom artiklar från den långlivade samlingen Organic Syntheses. Först analyserar den reaktionsdiagram och strukturritningar och kopplar varje skissad molekyl till dess roll i reaktionen, såsom utgångsmaterial eller produkt. Därefter läser den de skrivna procedurerna för att extrahera detaljer som vilka föreningar som användes, i vilka kvantiteter, hur länge reaktionerna kördes och vilka utbyten som uppnåddes. Slutligen standardiserar systemet allt — namn, enheter och format — så att tusentals olika artiklar kan slås samman till en sammanhängande, sökbar datamängd.
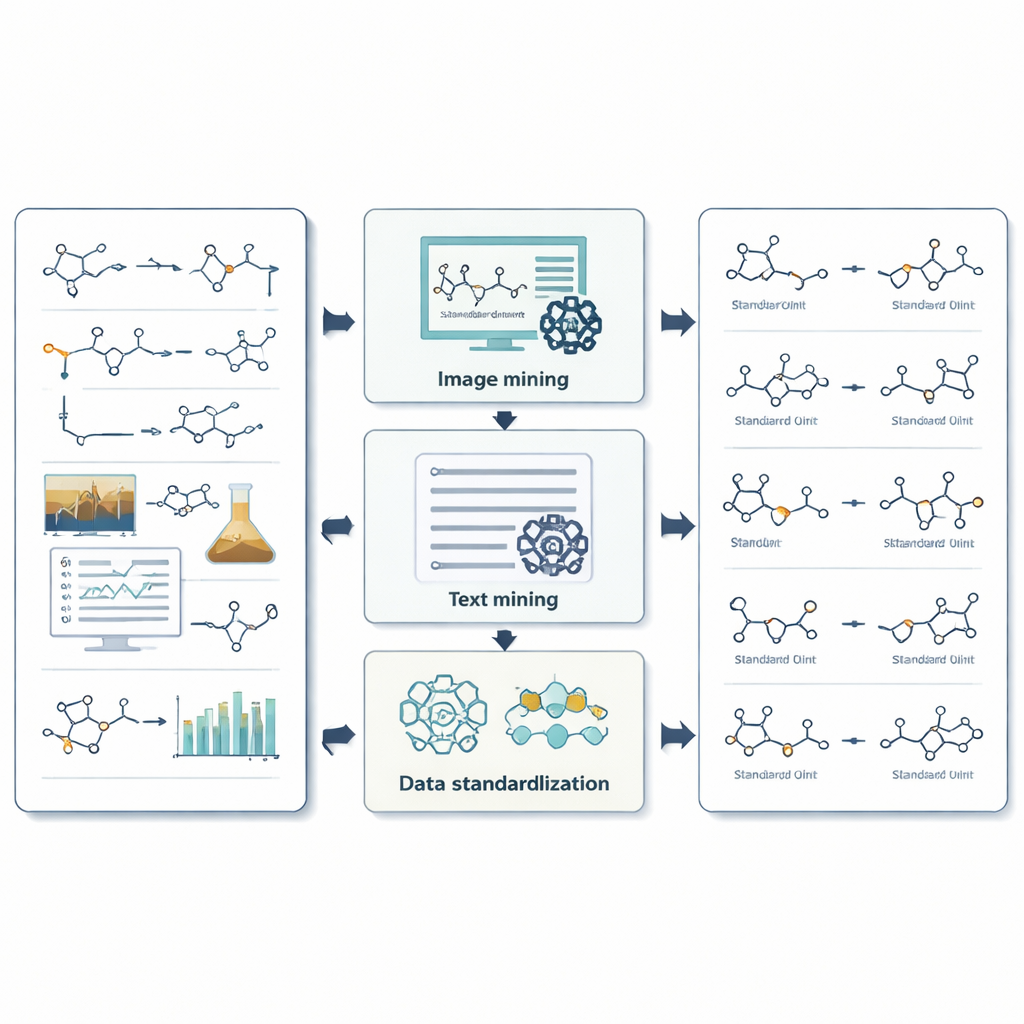
Hur systemet utvinner bilder, text och numeriska data
För bilder använder ReactionSeek en visionskapabel språkmodell för att identifiera vilka ritade strukturer som motsvarar vilka etiketter, och om de agerar som reaktanter eller produkter. En separat igenkännare för kemiska ritningar konverterar sedan dessa former till digitala molekylformat som datorer kan bearbeta. För text styrs språkmodellen av noggrant utformade instruktioner som hjälper den att navigera den intrikata stilen i experimentella beskrivningar, så att den kan upptäcka varje förening, matcha den till rätt rubrik och fånga villkor som temperatur, tid och lösningsmedel. Systemet tar ytterligare steg genom att extrahera komplexa mätdata, som kärnmagnetisk resonans och massespektra, vilka kemister förlitar sig på för att bekräfta att de framställt rätt molekyl. Där generiska AI-verktyg ofta snubblar — till exempel när långa kemiska namn ska översättas till exakta strukturer — korskontrollerar ReactionSeek mot offentliga kemidatabaser och dedikerade namn-till-struktur-program, och använder språkmodellen främst som en intelligent matchare snarare än ensam beslutsgivare.
Från en tidskrift till ett sekel av kemiska trender
För att testa angreppssättet använde författarna ReactionSeek på 100 volymer av Organic Syntheses, som täcker reaktioner publicerade från 1921 till 2021. Systemet bearbetade över tremiljarder — ursäkta, över tre tusen artiklar på minuter per artikel i stället för de många timmar en mänsklig kurator skulle behöva. Det fångade reaktionsingredienser, villkor och resultat med över 95% precision och återkallning för centrala fält. Detta nyligen strukturerade dataset innehåller nästan fyra tusen distinkta reaktioner och tusentals unika föreningar, alla på tillförlitlig gram-skala och granskade av gemenskapen. Utöver detta byggde forskarna en interaktiv assistent kallad SynChat, som låter kemister ställa frågor i naturligt språk — eventuellt inklusive ritade molekyler — och få svar förankrade i den utvunna litteraturen, kompletta med länkar tillbaka till originalprocedurerna.
Att låta AI upptäcka mönster i ett sekel av experiment
När reaktionsdatan väl var organiserad använde teamet en annan avancerad språkmodell för att leta efter långsiktiga trender över tid. Utan att bli uttryckligen instruerad om vad den skulle förvänta sig återupptäckte AI:n välkända skiften inom fältet: uppgången för asymmetrisk katalys efter cirka 1980, förskjutningen från enkla huvudgruppsreagenser mot sofistikerade övergångsmetallkatalysatorer, och den gradvisa minskningen av mycket giftiga metaller. Den identifierade också förändrade preferenser i reaktionspartners och katalytiska metaller, vilket speglar hur kemisternas verktyg utvecklats under årtiondena. Dessa resultat tyder på att en rik och trovärdig datamängd kan göra det möjligt för AI att ge historisk och strategisk insikt som stämmer väl överens med expertbedömningar.
Vad detta innebär för framtida kemisk upptäckt
Kort sagt är ReactionSeek en bro mellan dammiga kemiska arkiv och de AI-verktyg som lovar att påskynda framtida upptäckter. Genom att automatisera det mödosamma arbetet att läsa, extrahera och rensa reaktionsdetaljer levererar det högkvalitativ, maskinläsbar data som kan driva bättre prediktiva modeller, smartare laboratorieplanering och mer intuitiva sökverktyg för forskare. Även om systemet fortfarande möter utmaningar med sällsynta kemiska namn, komplexa tabeller och ofullkomlig strukturigenkänning visar det redan att noggrann promptdesign och en klok blandning av AI- och regelbaserade verktyg kan förvandla ostrukturerad vetenskaplig litteratur till en levande kunskapsbas. För kemister och icke-specialister pekar detta mot en framtid där årtionden av experimentellt arbete kan utforskas, ifrågasättas och byggas vidare på med hjälp av intelligenta maskiner.
Citering: Li, J., Li, M., Yang, Q. et al. ReactionSeek: LLM-powered literature data mining and knowledge discovery in organic synthesis. Nat Commun 17, 3356 (2026). https://doi.org/10.1038/s41467-026-70180-1
Nyckelord: kemisk datautvinning, stora språkmodeller, organisk syntes, vetenskaplig textextraktion, AI inom kemi