Clear Sky Science · en
ReactionSeek: LLM-powered literature data mining and knowledge discovery in organic synthesis
Why turning old chemistry papers into data matters
Modern breakthroughs in medicine, materials, and green technology increasingly rely on computers to spot patterns and suggest new molecules. But most chemical know-how is still buried in a century’s worth of research papers, written for humans, not machines. This article introduces ReactionSeek, a system that teaches artificial intelligence to read these papers, pull out important experimental details, and turn them into organized data. For anyone interested in how AI is changing science—from drug discovery to cleaner manufacturing—this work shows how we might finally unlock the vast “hidden archive” of chemistry.
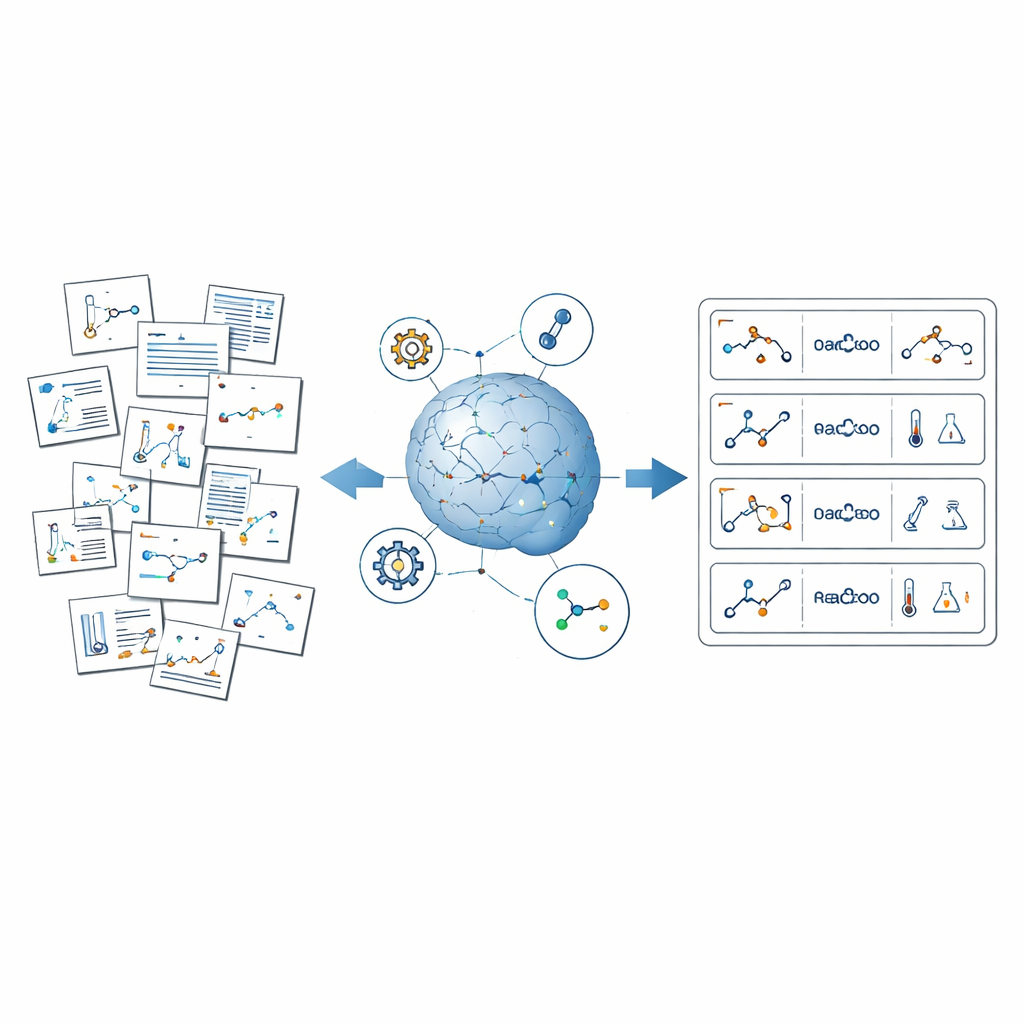
The problem of hidden chemical knowledge
Organic synthesis, the craft of building complex molecules from simple ones, is at the heart of chemistry. Researchers have published tens of thousands of detailed recipes describing which ingredients they used, in what amounts, at what temperature, and with what success. Yet this information is scattered across text paragraphs, diagrams, tables, and supporting files. Existing databases cover only a fraction of this landscape, are often proprietary, and sometimes miss unusual reactions. Automated lab experiments can generate neat datasets, but they are expensive and explore only a narrow range of chemistry. As a result, most AI tools are trained on simplified, cleaned-up data and cannot fully reflect the messy richness of real laboratory work.
A new way to teach AI to read chemistry papers
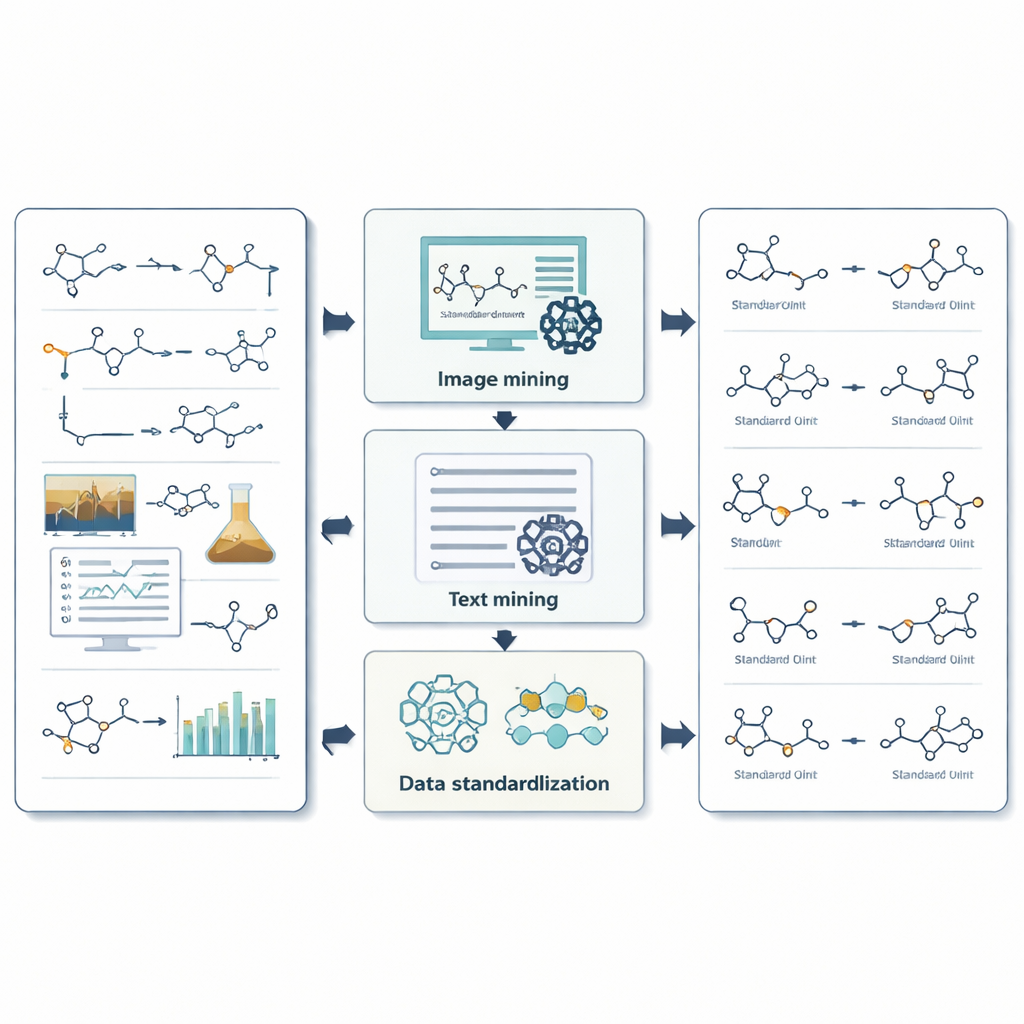
ReactionSeek tackles this challenge by combining large language models—AI systems trained to understand and generate text and images—with specialized chemistry software. The framework works like an automated reader that goes through articles from the long-running Organic Syntheses collection. First, it studies reaction diagrams and structure drawings, linking each sketched molecule to its role in the reaction, such as starting material or product. Then it reads the written procedures to extract details like which compounds were used, in what quantities, how long the reactions ran, and what yields were obtained. Finally, it standardizes everything—names, units, and formats—so that thousands of different articles can be merged into one coherent, searchable dataset.
How the system mines images, text, and numbers
For images, ReactionSeek uses a vision-capable language model to identify which drawn structures correspond to which labels, and whether they act as reactants or products. A separate chemical drawing recognizer then converts these shapes into digital molecular formats that computers can work with. For text, carefully crafted prompts guide the language model through the intricate style of experimental write-ups, helping it detect each compound, match it to its heading, and capture conditions such as temperature, time, and solvent. The system goes a step further by extracting complex measurement data, like nuclear magnetic resonance and mass spectra, which chemists rely on to confirm that they made the right molecule. Where generic AI tools often stumble—such as translating long chemical names into exact structures—ReactionSeek cross-checks against public chemistry databases and dedicated name-to-structure programs, using the language model mainly as a smart matcher rather than a lone decision-maker.
From one journal to a century of chemical trends
To test the approach, the authors unleashed ReactionSeek on 100 volumes of Organic Syntheses, covering reactions published from 1921 to 2021. The system processed over three thousand papers in minutes per article instead of the many hours a human curator would need. It captured reaction ingredients, conditions, and results with over 95% precision and recall for key fields. This newly structured dataset contains nearly four thousand distinct reactions and thousands of unique compounds, all on reliable gram-scale and vetted by the community. On top of this, the researchers built an interactive assistant called SynChat, which lets chemists ask natural-language questions—optionally including drawn molecules—and receive answers grounded in the mined literature, complete with links back to the original procedures.
Letting AI discover patterns in a century of experiments
Once the reaction data were organized, the team used another advanced language model to look for big-picture trends over time. Without being explicitly told what to expect, the AI rediscovered well-known shifts in the field: the rise of asymmetric catalysis after about 1980, the move from simple main-group reagents toward sophisticated transition-metal catalysts, and the gradual decline of highly toxic metals. It also picked out changing preferences in reaction partners and catalytic metals, mirroring how chemists’ tools have evolved over the decades. These results suggest that, when fed a rich and trustworthy dataset, AI can provide historical and strategic insight that aligns with expert understanding.
What this means for future chemical discovery
In plain terms, ReactionSeek is a bridge between dusty chemistry archives and the AI tools that promise to accelerate future discoveries. By automating the tedious work of reading, extracting, and cleaning up reaction details, it delivers high-quality, machine-ready data that can power better predictive models, smarter laboratory planning, and more intuitive search tools for scientists. While the system still faces challenges with rare chemical names, complex tables, and imperfect structure recognition, it already shows that careful prompt design and a smart mix of AI and rule-based tools can turn unstructured scientific literature into a living knowledge base. For chemists and non-specialists alike, this points to a future where decades of experimental work can be explored, questioned, and extended with the help of intelligent machines.
Citation: Li, J., Li, M., Yang, Q. et al. ReactionSeek: LLM-powered literature data mining and knowledge discovery in organic synthesis. Nat Commun 17, 3356 (2026). https://doi.org/10.1038/s41467-026-70180-1
Keywords: chemical data mining, large language models, organic synthesis, scientific text extraction, AI in chemistry