Clear Sky Science · es
ReactionSeek: minería de datos y descubrimiento de conocimiento en síntesis orgánica impulsados por LLM
Por qué convertir artículos antiguos de química en datos importa
Los avances modernos en medicina, materiales y tecnología verde dependen cada vez más de los ordenadores para detectar patrones y sugerir nuevas moléculas. Pero la mayor parte del saber químico sigue enterrado en un siglo de artículos de investigación, escritos para humanos y no para máquinas. Este artículo presenta ReactionSeek, un sistema que enseña a la inteligencia artificial a leer esos artículos, extraer detalles experimentales importantes y convertirlos en datos organizados. Para cualquiera interesado en cómo la IA está cambiando la ciencia —desde el descubrimiento de fármacos hasta procesos de fabricación más limpios— este trabajo muestra cómo podríamos finalmente desbloquear el vasto “archivo oculto” de la química.
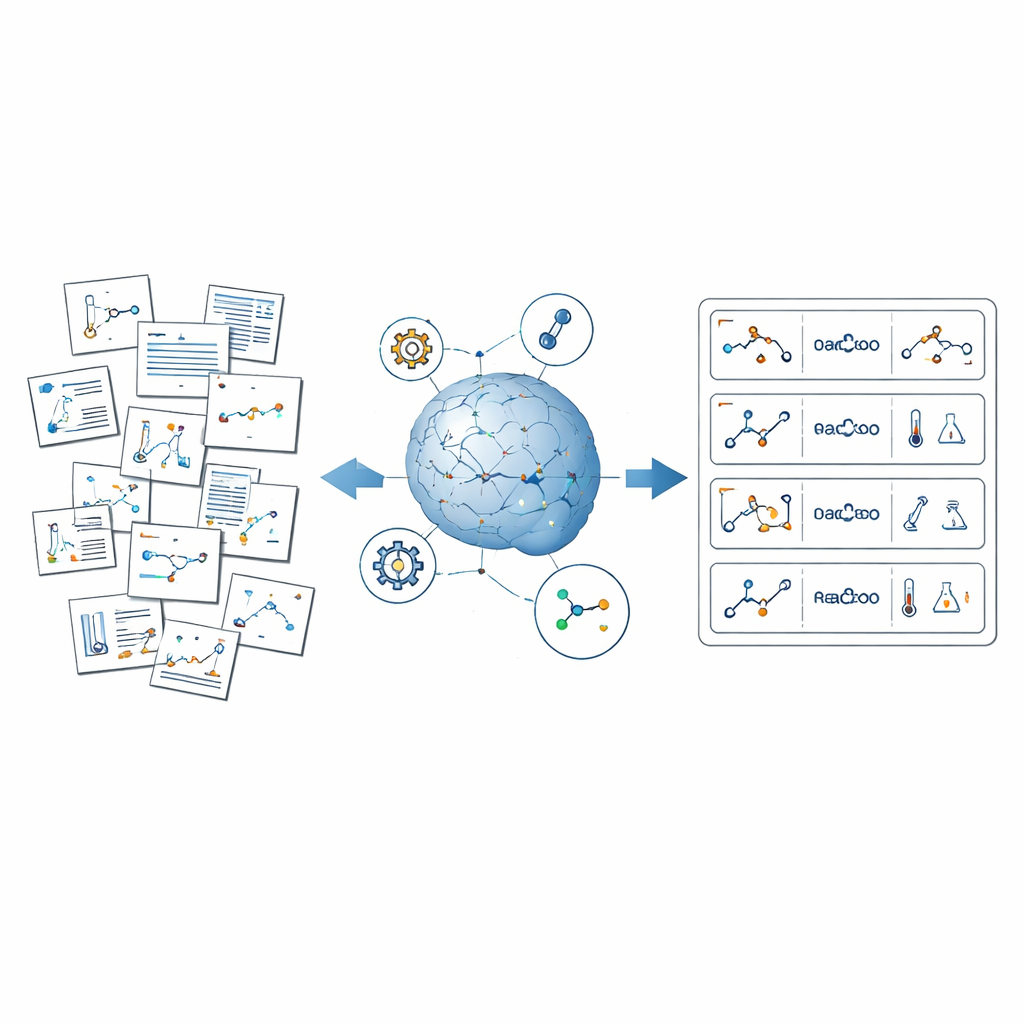
El problema del conocimiento químico oculto
La síntesis orgánica, el arte de construir moléculas complejas a partir de otras más sencillas, está en el núcleo de la química. Los investigadores han publicado decenas de miles de recetas detalladas que describen qué ingredientes usaron, en qué cantidades, a qué temperatura y con qué éxito. Sin embargo, esta información está dispersa en párrafos de texto, diagramas, tablas y archivos suplementarios. Las bases de datos existentes cubren sólo una fracción de este panorama, suelen ser propietarias y a veces pasan por alto reacciones inusuales. Los experimentos automatizados en laboratorio pueden generar conjuntos de datos ordenados, pero son costosos y exploran sólo un rango estrecho de la química. Como resultado, la mayoría de las herramientas de IA se entrenan con datos simplificados y depurados que no reflejan plenamente la riqueza desordenada del trabajo de laboratorio real.
Una nueva forma de enseñar a la IA a leer artículos de química
ReactionSeek aborda este desafío combinando modelos de lenguaje grandes —sistemas de IA entrenados para entender y generar texto e imágenes— con software químico especializado. El marco funciona como un lector automatizado que analiza artículos de la longeva colección Organic Syntheses. Primero estudia los diagramas de reacción y los dibujos estructurales, vinculando cada molécula dibujada con su papel en la reacción, como material de partida o producto. Luego lee los procedimientos escritos para extraer detalles como qué compuestos se usaron, en qué cantidades, cuánto tiempo duraron las reacciones y qué rendimientos se obtuvieron. Finalmente, estandariza todo —nombres, unidades y formatos— de modo que miles de artículos diferentes puedan fusionarse en un único conjunto de datos coherente y buscable.
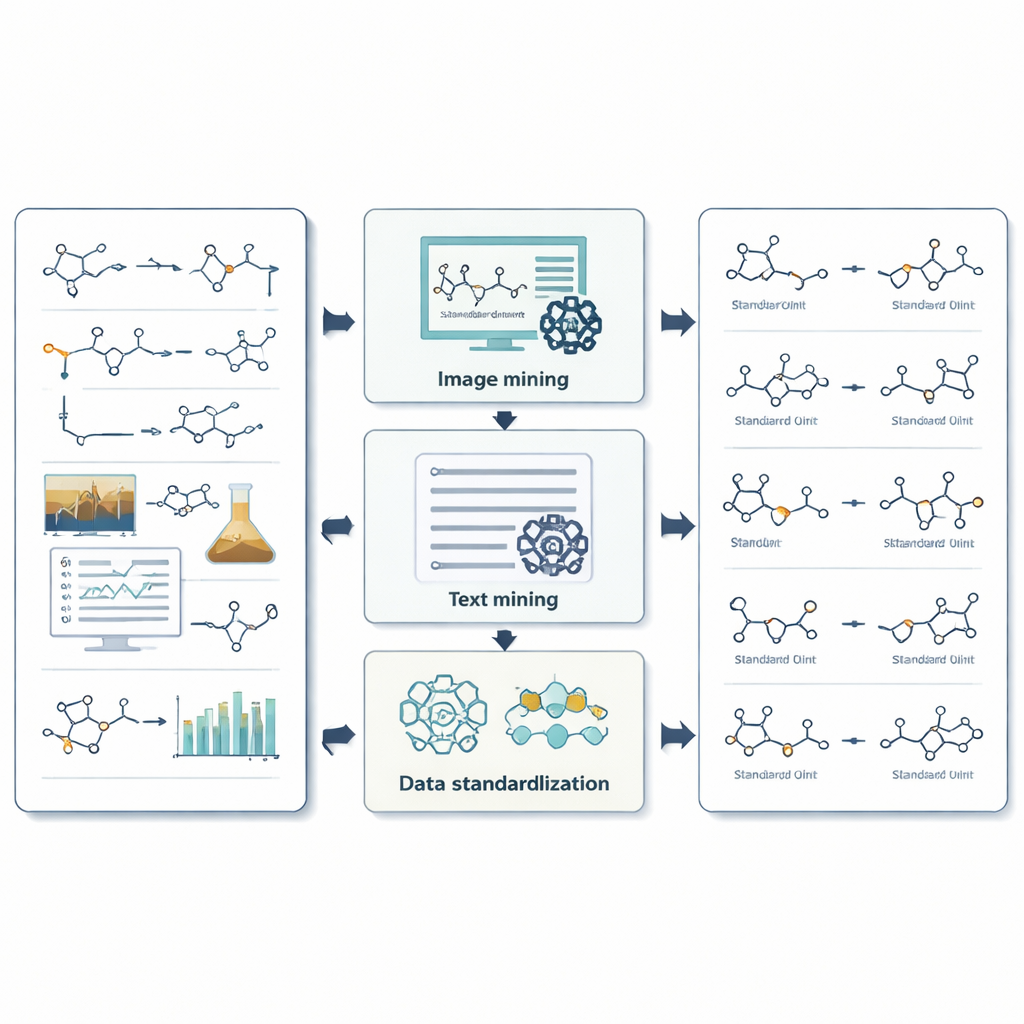
Cómo el sistema extrae información de imágenes, texto y números
Para las imágenes, ReactionSeek usa un modelo de lenguaje con capacidad visual para identificar qué estructuras dibujadas corresponden a qué etiquetas y si actúan como reactivos o productos. Un reconocedor de dibujos químicos por separado convierte esas formas en formatos moleculares digitales con los que los ordenadores pueden trabajar. Para el texto, prompts cuidadosamente diseñados guían al modelo de lenguaje a través del estilo intrincado de los relatos experimentales, ayudándole a detectar cada compuesto, emparejarlo con su encabezado y capturar condiciones como temperatura, tiempo y disolvente. El sistema va más allá extrayendo datos de medición complejos, como espectros de resonancia magnética nuclear y espectrometría de masas, que los químicos usan para confirmar que han obtenido la molécula correcta. Donde las herramientas genéricas de IA a menudo tropiezan —por ejemplo, traducir nombres químicos largos en estructuras exactas— ReactionSeek verifica con bases de datos químicas públicas y programas dedicados de nombre-a-estructura, usando el modelo de lenguaje más como un emparejador inteligente que como un único tomador de decisiones.
De una revista a un siglo de tendencias químicas
Para probar el enfoque, los autores aplicaron ReactionSeek a 100 volúmenes de Organic Syntheses, que abarcan reacciones publicadas entre 1921 y 2021. El sistema procesó más de tres mil artículos en minutos por artículo en lugar de las muchas horas que requeriría un curador humano. Capturó ingredientes de reacción, condiciones y resultados con más del 95% de precisión y recuperación en campos clave. Este conjunto de datos recién estructurado contiene casi cuatro mil reacciones distintas y miles de compuestos únicos, todos a escala de gramos y validados por la comunidad. Además, los investigadores construyeron un asistente interactivo llamado SynChat, que permite a los químicos formular preguntas en lenguaje natural —incluyendo opcionalmente moléculas dibujadas— y recibir respuestas fundadas en la literatura extraída, completas con enlaces a los procedimientos originales.
Permitir que la IA descubra patrones en un siglo de experimentos
Una vez organizados los datos de reacción, el equipo usó otro modelo de lenguaje avanzado para buscar tendencias de gran calado a lo largo del tiempo. Sin que se le indicara explícitamente qué esperar, la IA redescubrió cambios bien conocidos en el campo: el auge de la catálisis asimétrica a partir de alrededor de 1980, el desplazamiento desde reactivos sencillos de los grupos principales hacia catalizadores sofisticados de metales de transición y la disminución gradual de metales altamente tóxicos. También destacó cambios en las preferencias por socios de reacción y metales catalíticos, reflejando cómo las herramientas de los químicos han evolucionado a lo largo de las décadas. Estos resultados sugieren que, con un conjunto de datos rico y fiable, la IA puede ofrecer perspectivas históricas y estratégicas que se alinean con la comprensión experta.
Qué significa esto para el descubrimiento químico futuro
En términos sencillos, ReactionSeek es un puente entre los polvorientos archivos de la química y las herramientas de IA que prometen acelerar futuros descubrimientos. Al automatizar el trabajo tedioso de leer, extraer y limpiar los detalles de las reacciones, aporta datos listos para máquinas y de alta calidad que pueden impulsar modelos predictivos mejores, una planificación de laboratorio más inteligente y herramientas de búsqueda más intuitivas para los científicos. Aunque el sistema aún enfrenta desafíos con nombres químicos raros, tablas complejas y reconocimiento imperfecto de estructuras, ya demuestra que un diseño de prompts cuidadoso y una mezcla inteligente de IA y reglas basadas en software pueden convertir la literatura científica no estructurada en una base de conocimiento viva. Para químicos y no especialistas por igual, esto apunta a un futuro en el que décadas de trabajo experimental pueden ser exploradas, cuestionadas y ampliadas con la ayuda de máquinas inteligentes.
Cita: Li, J., Li, M., Yang, Q. et al. ReactionSeek: LLM-powered literature data mining and knowledge discovery in organic synthesis. Nat Commun 17, 3356 (2026). https://doi.org/10.1038/s41467-026-70180-1
Palabras clave: minería de datos químicos, modelos de lenguaje grande, síntesis orgánica, extracción de texto científico, IA en química