Clear Sky Science · de
ReactionSeek: LLM-gestütztes Data-Mining in der Literatur und Wissensentdeckung in der organischen Synthese
Warum es wichtig ist, alte Chemiearbeiten in Daten zu verwandeln
Moderne Durchbrüche in Medizin, Materialwissenschaften und grüner Technologie verlassen sich zunehmend auf Computer, die Muster erkennen und neue Moleküle vorschlagen. Doch das meiste chemische Wissen steckt noch in einem Jahrhundert voller Forschungsarbeiten, die für Menschen und nicht für Maschinen geschrieben wurden. Dieser Artikel stellt ReactionSeek vor, ein System, das künstliche Intelligenz anleitet, diese Arbeiten zu lesen, wichtige experimentelle Details herauszuziehen und in organisierte Daten zu überführen. Für alle, die sich dafür interessieren, wie KI die Wissenschaft verändert – von der Wirkstoffforschung bis zur saubereren Produktion – zeigt diese Arbeit, wie sich das riesige „versteckte Archiv“ der Chemie endlich erschließen lässt.
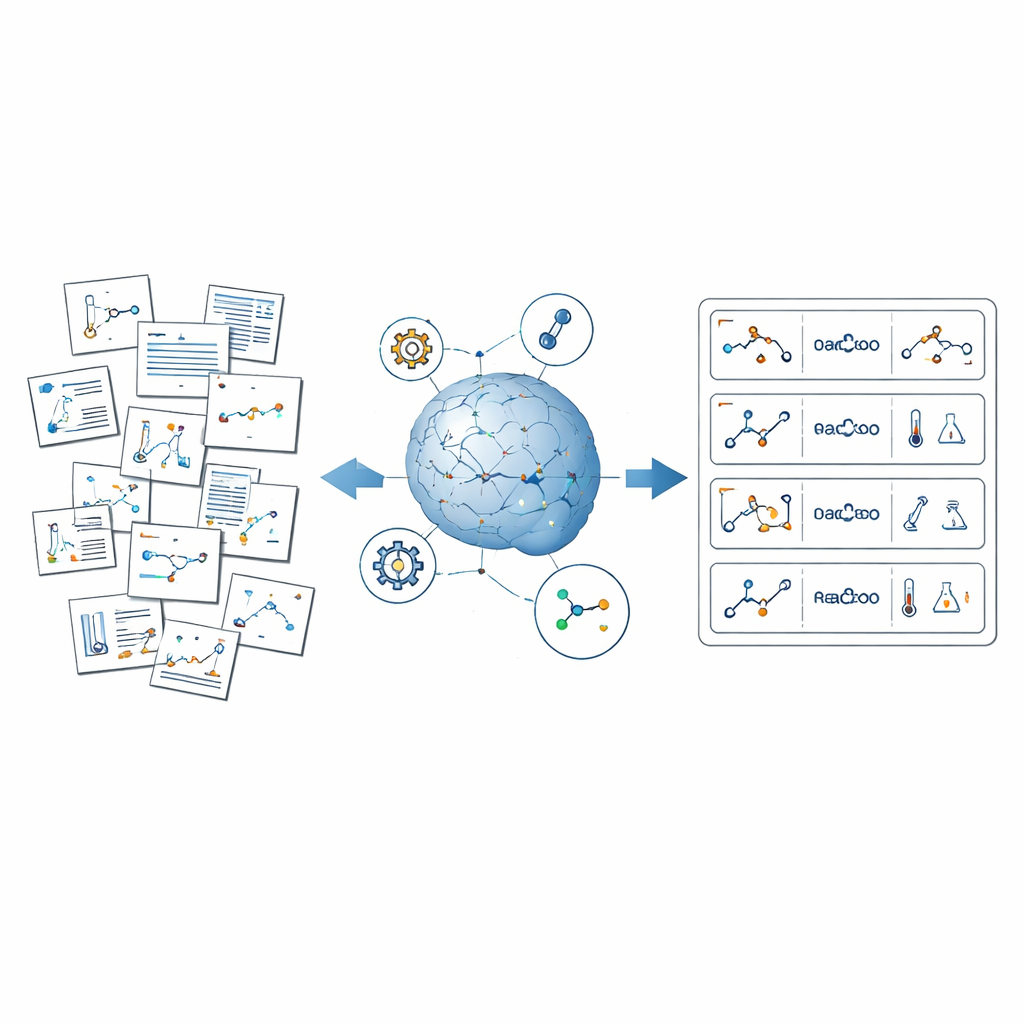
Das Problem des verborgenen chemischen Wissens
Die organische Synthese, die Kunst, komplexe Moleküle aus einfachen Bausteinen zu erzeugen, steht im Zentrum der Chemie. Forschende haben Zehntausende detaillierter Rezepte veröffentlicht, die beschreiben, welche Zutaten sie verwendeten, in welchen Mengen, bei welchen Temperaturen und mit welchem Erfolg. Diese Informationen sind jedoch über Fließtext, Diagramme, Tabellen und ergänzende Dateien verstreut. Bestehende Datenbanken decken nur einen Bruchteil dieses Bestands ab, sind oft proprietär und übersehen manchmal ungewöhnliche Reaktionen. Automatisierte Laborversuche können ordentliche Datensätze erzeugen, sind aber teuer und erforschen nur einen engen Bereich der Chemie. Daher werden viele KI-Werkzeuge mit vereinfachten, bereinigten Daten trainiert und können die unordentliche Vielfalt realer Laborarbeit nicht vollständig abbilden.
Ein neuer Weg, KI das Lesen von Chemieartikeln beizubringen
ReactionSeek begegnet dieser Herausforderung, indem es große Sprachmodelle – KI-Systeme, die auf das Verstehen und Generieren von Text und Bildern trainiert sind – mit spezialisierter Chemiesoftware kombiniert. Das Framework funktioniert wie ein automatisierter Leser, der Artikel aus der langjährig erscheinenden Sammlung Organic Syntheses durchgeht. Zuerst analysiert es Reaktionsschemata und Strukturzeichnungen und verknüpft jede skizzierte Verbindung mit ihrer Rolle in der Reaktion, etwa als Ausgangsstoff oder Produkt. Dann liest es die beschriebenen Verfahren, um Details zu extrahieren, beispielsweise welche Verbindungen verwendet wurden, in welchen Mengen, wie lange die Reaktionen liefen und welche Ausbeuten erzielt wurden. Schließlich standardisiert es alles – Namen, Einheiten und Formate – sodass Tausende verschiedener Artikel zu einem kohärenten, durchsuchbaren Datensatz zusammengeführt werden können.
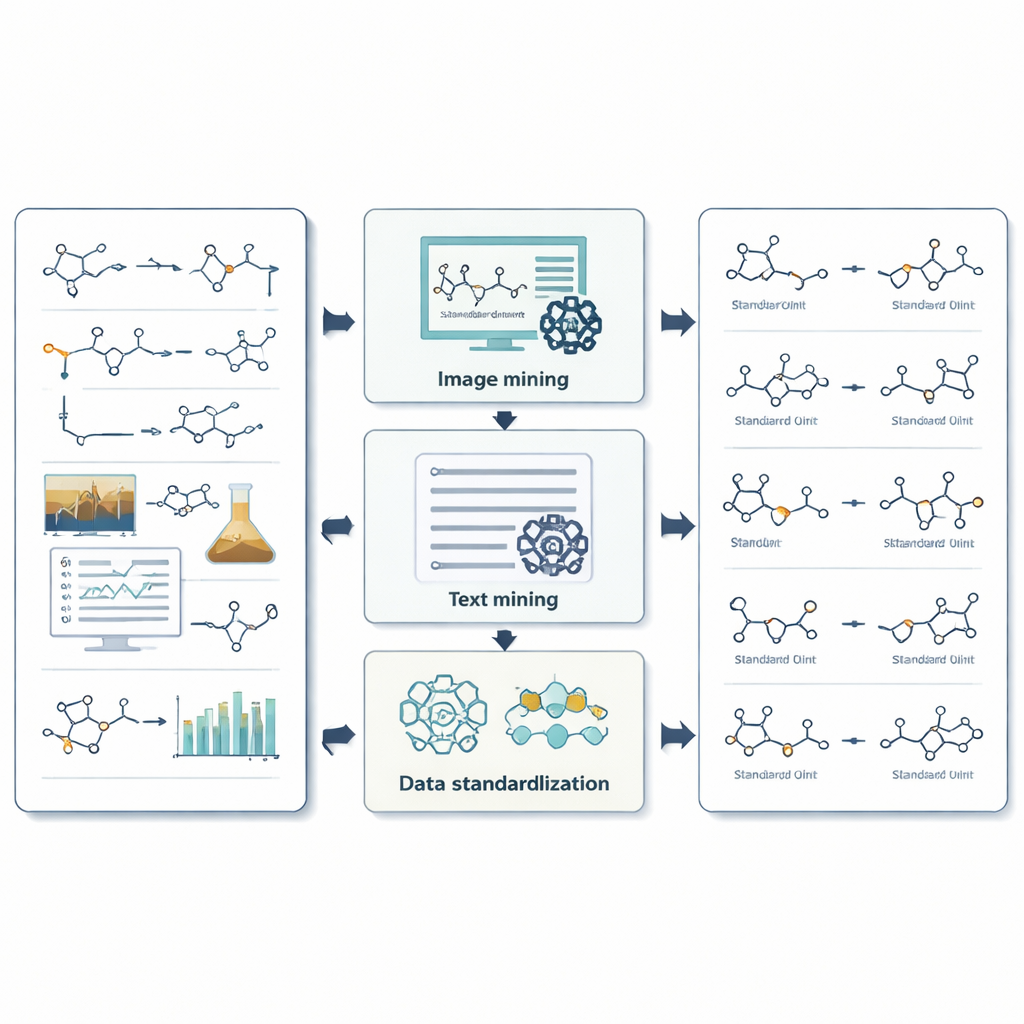
Wie das System Bilder, Text und Zahlen bergmännisch erschließt
Für Bilder nutzt ReactionSeek ein visionsfähiges Sprachmodell, um zu erkennen, welche gezeichneten Strukturen welchen Beschriftungen entsprechen und ob sie als Reaktanten oder Produkte fungieren. Ein separates Programm zur Erkennung chemischer Zeichnungen wandelt diese Formen dann in digitale Molekülformate um, mit denen Computer arbeiten können. Für den Text führen sorgfältig gestaltete Prompts das Sprachmodell durch den komplexen Stil experimenteller Beschreibungen und helfen ihm, jede Verbindung zu identifizieren, sie ihrer Überschrift zuzuordnen und Bedingungen wie Temperatur, Zeit und Lösungsmittel zu erfassen. Das System geht weiter, indem es komplexe Messdaten extrahiert, etwa Kernspinresonanzen und Massenspektren, auf die Chemiker zur Bestätigung der richtigen Struktur angewiesen sind. Dort, wo generische KI-Tools oft stolpern – etwa bei der Übersetzung langer chemischer Namen in exakte Strukturen – prüft ReactionSeek gegen öffentliche Chemiedatenbanken und spezialisierte Namens-zu-Struktur-Programme und verwendet das Sprachmodell hauptsächlich als intelligentes Zuordnungswerkzeug statt als alleinige Entscheidungsinstanz.
Von einer Zeitschrift zu einem Jahrhundert chemischer Trends
Um den Ansatz zu testen, setzten die Autoren ReactionSeek auf 100 Bände von Organic Syntheses an, die Reaktionen aus den Jahren 1921 bis 2021 umfassen. Das System verarbeitete über dreitausend Artikel in Minuten pro Artikel, statt der vielen Stunden, die ein menschlicher Kurator benötigen würde. Es erfasste Reaktionsbestandteile, Bedingungen und Ergebnisse mit über 95 % Präzision und Rückrufrate für die wichtigsten Felder. Dieser neu strukturierte Datensatz enthält nahezu viertausend verschiedene Reaktionen und tausende einzigartige Verbindungen, alle verlässlich im Grammmaßstab und von der Community geprüft. Darüber hinaus entwickelten die Forschenden einen interaktiven Assistenten namens SynChat, der Chemikern erlaubt, Fragen in natürlicher Sprache zu stellen – optional inklusive gezeichneter Moleküle – und Antworten zu erhalten, die auf der erschlossenen Literatur beruhen, einschließlich Verlinkungen zu den Originalprozeduren.
KI Muster in einem Jahrhundert Experimenten entdecken lassen
Sobald die Reaktionsdaten organisiert waren, nutzte das Team ein weiteres fortgeschrittenes Sprachmodell, um nach großflächigen Trends über die Zeit zu suchen. Ohne explizite Vorgaben entdeckte die KI bekannte Verschiebungen im Feld wieder: den Aufstieg der asymmetrischen Katalyse nach etwa 1980, den Wechsel von einfachen Hauptgruppereagenzien hin zu ausgefeilteren Übergangsmetallkatalysatoren und den allmählichen Rückgang hochtoxischer Metalle. Sie identifizierte auch veränderte Präferenzen bei Reaktionspartnern und katalytischen Metallen, was die Entwicklung der chemischen Werkzeuge über die Jahrzehnte widerspiegelt. Diese Ergebnisse deuten darauf hin, dass KI, wenn sie mit einem reichen und verlässlichen Datensatz gefüttert wird, historische und strategische Einsichten liefern kann, die mit Expertenwissen übereinstimmen.
Was das für die zukünftige chemische Entdeckung bedeutet
Einfach ausgedrückt ist ReactionSeek eine Brücke zwischen verstaubten Chemiearchiven und den KI-Werkzeugen, die zukünftige Entdeckungen beschleunigen könnten. Durch die Automatisierung der mühsamen Arbeit des Lesens, Extrahierens und Bereinigens von Reaktionsdetails liefert es hochwertige, maschinenlesbare Daten, die bessere Vorhersagemodelle, intelligentere Laborplanung und intuitivere Suchwerkzeuge für Wissenschaftler ermöglichen. Obwohl das System weiterhin Herausforderungen bei seltenen chemischen Namen, komplexen Tabellen und unvollkommener Strukturerkennung hat, zeigt es bereits, dass sorgfältig gestaltete Prompts und eine kluge Mischung aus KI- und regelbasierten Werkzeugen unstrukturierte wissenschaftliche Literatur in eine lebendige Wissensbasis verwandeln können. Für Chemiker wie auch für Nicht-Fachleute weist dies auf eine Zukunft, in der Jahrzehnte experimenteller Arbeit mithilfe intelligenter Maschinen erkundet, hinterfragt und erweitert werden können.
Zitation: Li, J., Li, M., Yang, Q. et al. ReactionSeek: LLM-powered literature data mining and knowledge discovery in organic synthesis. Nat Commun 17, 3356 (2026). https://doi.org/10.1038/s41467-026-70180-1
Schlüsselwörter: Chemische Datengewinnung, Große Sprachmodelle, Organische Synthese, Wissenschaftliche Textextraktion, KI in der Chemie