Clear Sky Science · nl
ReactionSeek: door LLM aangedreven literatuur-datamining en kennisontdekking in organische synthese
Waarom het omzetten van oude chemieartikelen in data ertoe doet
Moderne doorbraken in geneeskunde, materialen en groentechnologie vertrouwen steeds vaker op computers om patronen te herkennen en nieuwe moleculen voor te stellen. Maar de meeste chemische kennis ligt nog begraven in een eeuw aan onderzoeksartikelen, geschreven voor mensen en niet voor machines. Dit artikel introduceert ReactionSeek, een systeem dat kunstmatige intelligentie leert deze artikelen te lezen, belangrijke experimentele details te halen en om te zetten in gestructureerde data. Voor iedereen die geïnteresseerd is in hoe AI de wetenschap verandert — van geneesmiddelenontwikkeling tot schonere productieprocessen — laat dit werk zien hoe we eindelijk het enorme “verborgen archief” van de chemie kunnen ontsluiten.
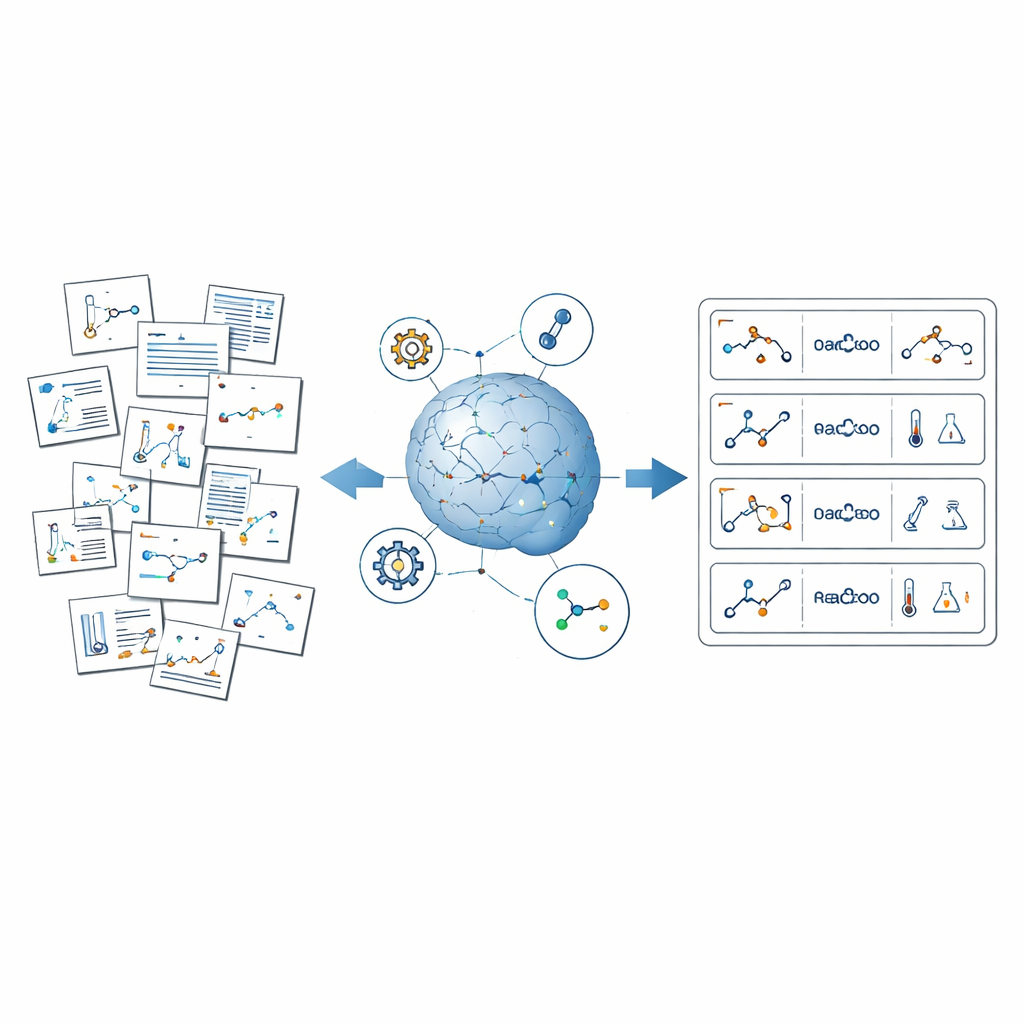
Het probleem van verborgen chemische kennis
Organische synthese, het vakmanschap van het opbouwen van complexe moleculen uit eenvoudige beginstoffen, vormt het hart van de chemie. Onderzoekers hebben tienduizenden gedetailleerde recepten gepubliceerd waarin staat welke ingrediënten ze gebruikten, in welke hoeveelheden, bij welke temperatuur en met welk succes. Toch is deze informatie verspreid over tekstparagrafen, diagrammen, tabellen en aanvullende bestanden. Bestaande databanken bestrijken slechts een fractie van dit landschap, zijn vaak propriëtair en missen soms ongebruikelijke reacties. Geautomatiseerde laboratoriumexperimenten kunnen nette datasets opleveren, maar ze zijn duur en verkennen slechts een smal deel van de chemie. Daardoor zijn de meeste AI-tools getraind op vereenvoudigde, opgeschoonde data en kunnen ze de rommelige rijkdom van echt labouratoriumwerk niet volledig weerspiegelen.
Een nieuwe manier om AI te leren chemieartikelen te lezen
ReactionSeek pakt deze uitdaging aan door grote taalmodellen — AI-systemen getraind om tekst en beelden te begrijpen en te genereren — te combineren met gespecialiseerde chemiesoftware. Het raamwerk werkt als een geautomatiseerde lezer die artikelen uit de langlopende collectie Organic Syntheses doorloopt. Eerst analyseert het reactiediagrammen en structuurtekeningen, waarbij elke geschetste molecule wordt gekoppeld aan zijn rol in de reactie, zoals beginmateriaal of product. Daarna leest het de geschreven procedure om details te extraheren, zoals welke verbindingen werden gebruikt, in welke hoeveelheden, hoelang de reacties liepen en welke opbrengsten werden behaald. Ten slotte standaardiseert het alles — namen, eenheden en formaten — zodat duizenden verschillende artikelen kunnen worden samengevoegd tot één coherent, doorzoekbaar dataset.
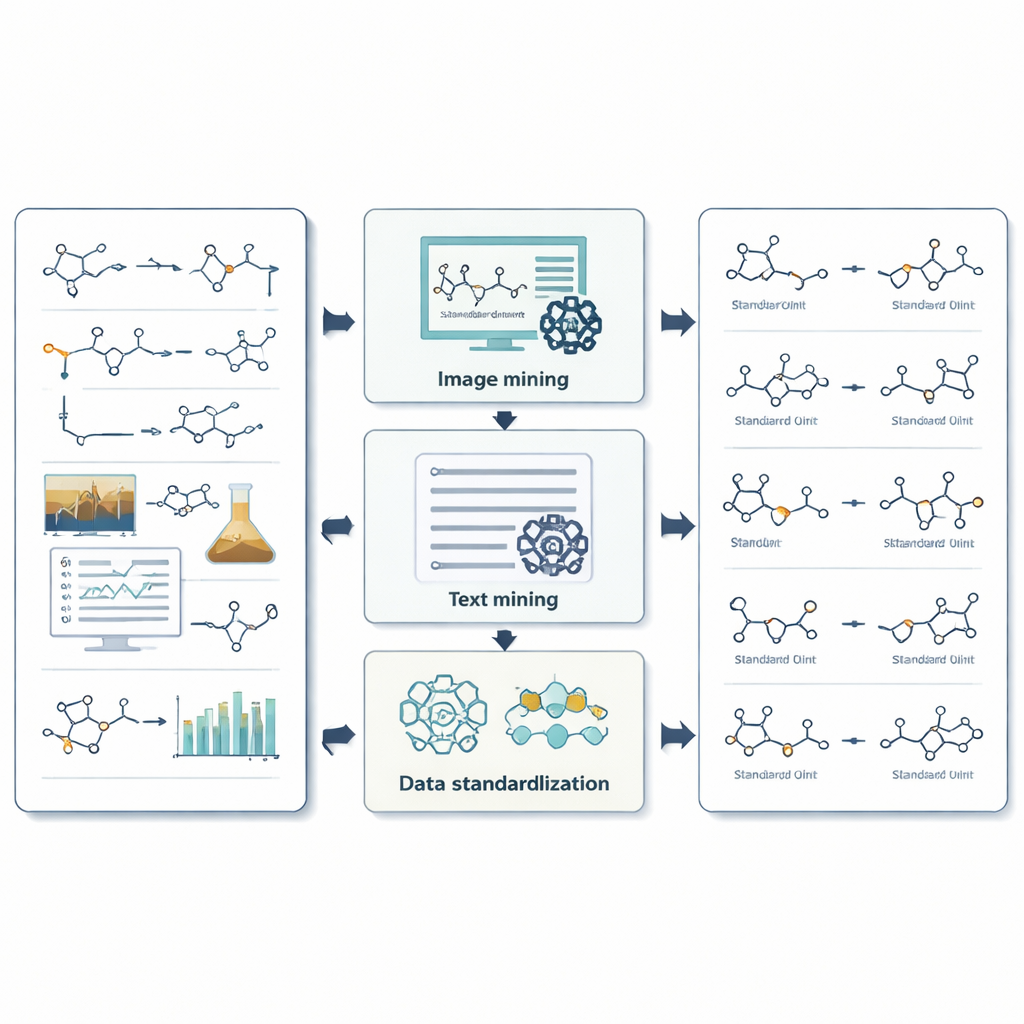
Hoe het systeem beelden, tekst en cijfers ontgint
Voor beelden gebruikt ReactionSeek een vision-capabel taalmodel om te identificeren welke getekende structuren overeenkomen met welke labels en of ze als reagentia of producten fungeren. Een apart herkenningssysteem voor chemische tekeningen zet deze vormen vervolgens om in digitale moleculaire formaten waarmee computers kunnen werken. Voor tekst leiden zorgvuldig opgestelde prompts het taalmodel door de complexe stijl van experimentele beschrijvingen, waardoor het elk verbinding kan detecteren, aan de juiste kop kan koppelen en condities zoals temperatuur, tijd en oplosmiddel kan vastleggen. Het systeem gaat nog een stap verder door complexe meetgegevens te extraheren, zoals NMR- en massaspectra, waarop chemici vertrouwen om te bevestigen dat ze het juiste molecuul hebben gemaakt. Waar generieke AI-tools vaak struikelen — bijvoorbeeld bij het omzetten van lange chemische namen naar exacte structuren — controleert ReactionSeek terug tegen openbare chemiedatabanken en speciale naam-naar-structuurprogramma's en gebruikt het taalmodel hoofdzakelijk als slimme matchmaker in plaats van als eenzame beslisser.
Van één tijdschrift naar een eeuw aan chemische trends
Om de aanpak te testen, zetten de auteurs ReactionSeek in op 100 delen van Organic Syntheses, met reacties gepubliceerd van 1921 tot 2021. Het systeem verwerkte meer dan drieduizend artikelen in minuten per artikel in plaats van de vele uren die een menselijke curator nodig zou hebben. Het legde reactiebestanddelen, condities en resultaten vast met meer dan 95% precisie en terugroep voor sleutelvelden. Deze nieuw gestructureerde dataset bevat bijna vierduizend verschillende reacties en duizenden unieke verbindingen, allemaal op betrouwbare gramschaal en beoordeeld door de gemeenschap. Daarbovenop bouwden de onderzoekers een interactieve assistent genaamd SynChat, waarmee chemici in natuurlijke taal vragen kunnen stellen — optioneel met ingesloten tekeningen van moleculen — en antwoorden ontvangen die geworteld zijn in de ontgonnen literatuur, compleet met links terug naar de oorspronkelijke procedures.
AI patronen laten ontdekken in een eeuw aan experimenten
Zodra de reactiedata waren georganiseerd, gebruikte het team een ander geavanceerd taalmodel om naar grote lijnen en trends over de tijd te zoeken. Zonder expliciet te worden verteld wat te verwachten, herontdekte de AI bekende verschuivingen in het veld: de opkomst van asymmetrische katalyse na ongeveer 1980, de beweging van eenvoudige hoofdgroepreagentia naar verfijnde overgangsmetaalkatalysatoren en de geleidelijke afname van sterk toxische metalen. Het identificeerde ook veranderende voorkeuren in reactiepartners en katalytische metalen, die weerspiegelen hoe de gereedschappen van chemici door de decennia heen zijn geëvolueerd. Deze resultaten suggereren dat AI, wanneer gevoed met een rijke en betrouwbare dataset, historische en strategische inzichten kan bieden die overeenkomen met de expertise van vakgenoten.
Wat dit betekent voor toekomstige chemische ontdekking
In eenvoudige bewoordingen is ReactionSeek een brug tussen stoffige chemiearchieven en de AI-tools die beloven toekomstige ontdekkingen te versnellen. Door het saaie werk van lezen, extraheren en opschonen van reactiedetails te automatiseren, levert het hoogwaardige, machineklare data die betere voorspellende modellen, slimmer laboratoriumplanning en meer intuïtieve zoektools voor wetenschappers kunnen aandrijven. Hoewel het systeem nog uitdagingen kent met zeldzame chemische namen, complexe tabellen en onvolmaakte structuurerkenning, laat het al zien dat zorgvuldige promptontwerpen en een slimme mix van AI- en regelgebaseerde hulpmiddelen ongestructureerde wetenschappelijke literatuur kunnen omzetten in een levende kennisbasis. Voor zowel chemici als niet-specialisten wijst dit op een toekomst waarin decennia aan experimenteel werk kunnen worden verkend, bevraagd en uitgebreid met hulp van intelligente machines.
Bronvermelding: Li, J., Li, M., Yang, Q. et al. ReactionSeek: LLM-powered literature data mining and knowledge discovery in organic synthesis. Nat Commun 17, 3356 (2026). https://doi.org/10.1038/s41467-026-70180-1
Trefwoorden: chemische datamining, grote taalmodellen, organische synthese, wetenschappelijke tekstanalyse, AI in chemie