Clear Sky Science · pl
ReactionSeek: Wydobywanie danych z literatury i odkrywanie wiedzy w syntezie organicznej wspomagane przez LLM
Dlaczego warto zamieniać stare artykuły chemiczne w dane
Współczesne przełomy w medycynie, materiałach i zielonych technologiach coraz częściej opierają się na komputerach analizujących wzorce i sugerujących nowe cząsteczki. Jednak większość wiedzy chemicznej wciąż jest zakopana w dekadach artykułów naukowych, pisanych dla ludzi, a nie dla maszyn. Niniejszy artykuł przedstawia ReactionSeek — system, który uczy sztuczną inteligencję czytania tych tekstów, wydobywania istotnych szczegółów eksperymentalnych i przekształcania ich w uporządkowane dane. Dla każdego zainteresowanego tym, jak AI zmienia naukę — od odkrywania leków po czystsze procesy produkcyjne — praca ta pokazuje, jak wreszcie możemy odblokować ogromne „ukryte archiwum” chemii.
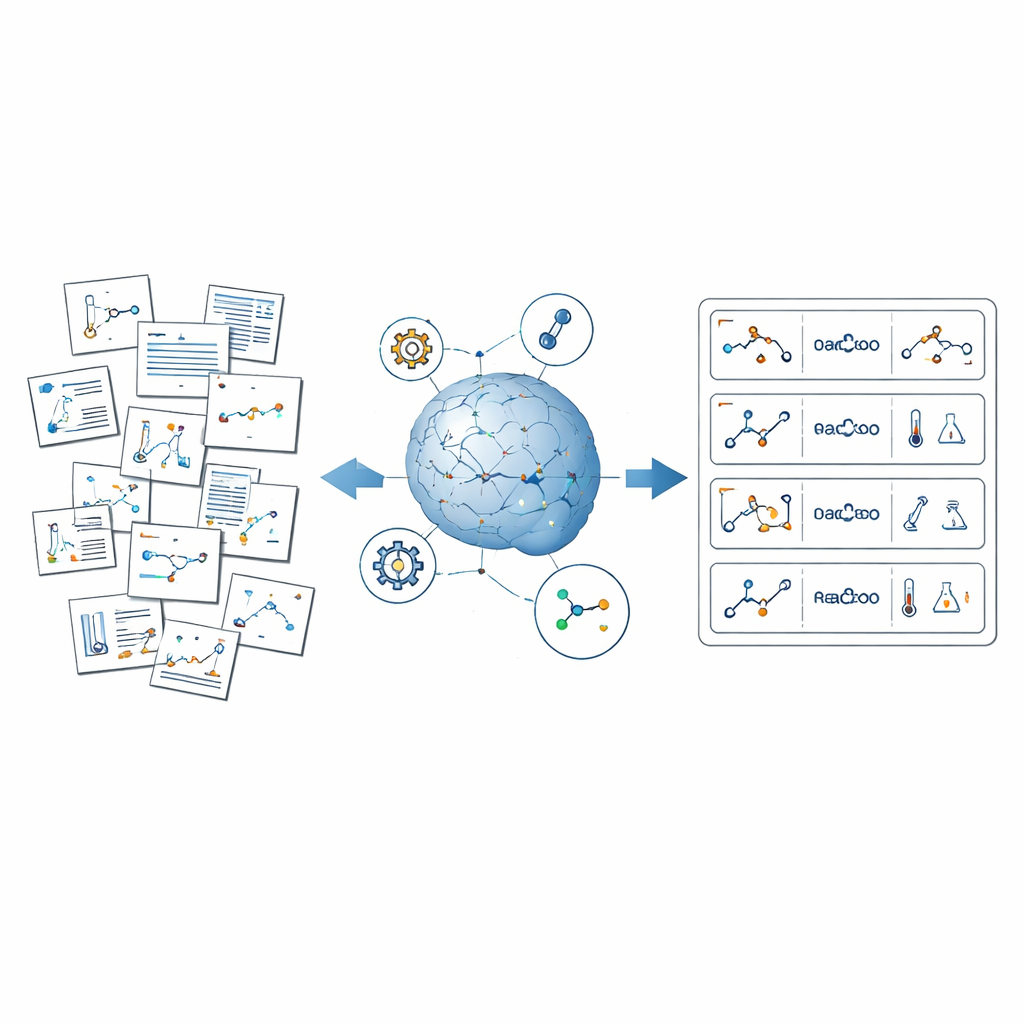
Problem ukrytej wiedzy chemicznej
Synteza organiczna, sztuka budowania złożonych cząsteczek z prostszych, leży w sercu chemii. Badacze opublikowali dziesiątki tysięcy szczegółowych receptur opisujących, jakich składników używali, w jakich ilościach, w jakiej temperaturze i z jakim wynikiem. Jednak te informacje są rozproszone w akapitach tekstu, schematach, tabelach i plikach uzupełniających. Istniejące bazy danych obejmują tylko fragment tego krajobrazu, często są własnościowe i czasem pomijają nietypowe reakcje. Zautomatyzowane eksperymenty laboratoryjne potrafią wygenerować porządne zbiory danych, ale są kosztowne i badają tylko wąski wycinek chemii. W rezultacie większość narzędzi AI trenuje się na uproszczonych, wyczyszczonych danych i nie jest w stanie w pełni odzwierciedlić złożonej, nieuporządkowanej rzeczywistości pracy laboratoryjnej.
Nowy sposób nauczania AI czytania artykułów chemicznych
ReactionSeek rozwiązuje to wyzwanie, łącząc duże modele językowe — systemy AI przeszkolone do rozumienia i generowania tekstu i obrazów — ze specjalistycznym oprogramowaniem chemicznym. Ramy działania przypominają zautomatyzowanego czytelnika przechodzącego przez artykuły z długowiecznej kolekcji Organic Syntheses. Najpierw analizuje schematy reakcji i rysunki struktur, łącząc każdą narysowaną cząsteczkę z jej rolą w reakcji, np. substratu czy produktu. Następnie czyta opisy procedur, aby wydobyć szczegóły takie jak użyte związki, ich ilości, czas trwania reakcji i uzysk. Na koniec standaryzuje wszystko — nazwy, jednostki i formaty — tak, by tysiące różnych artykułów dało się połączyć w spójny, przeszukiwalny zestaw danych.
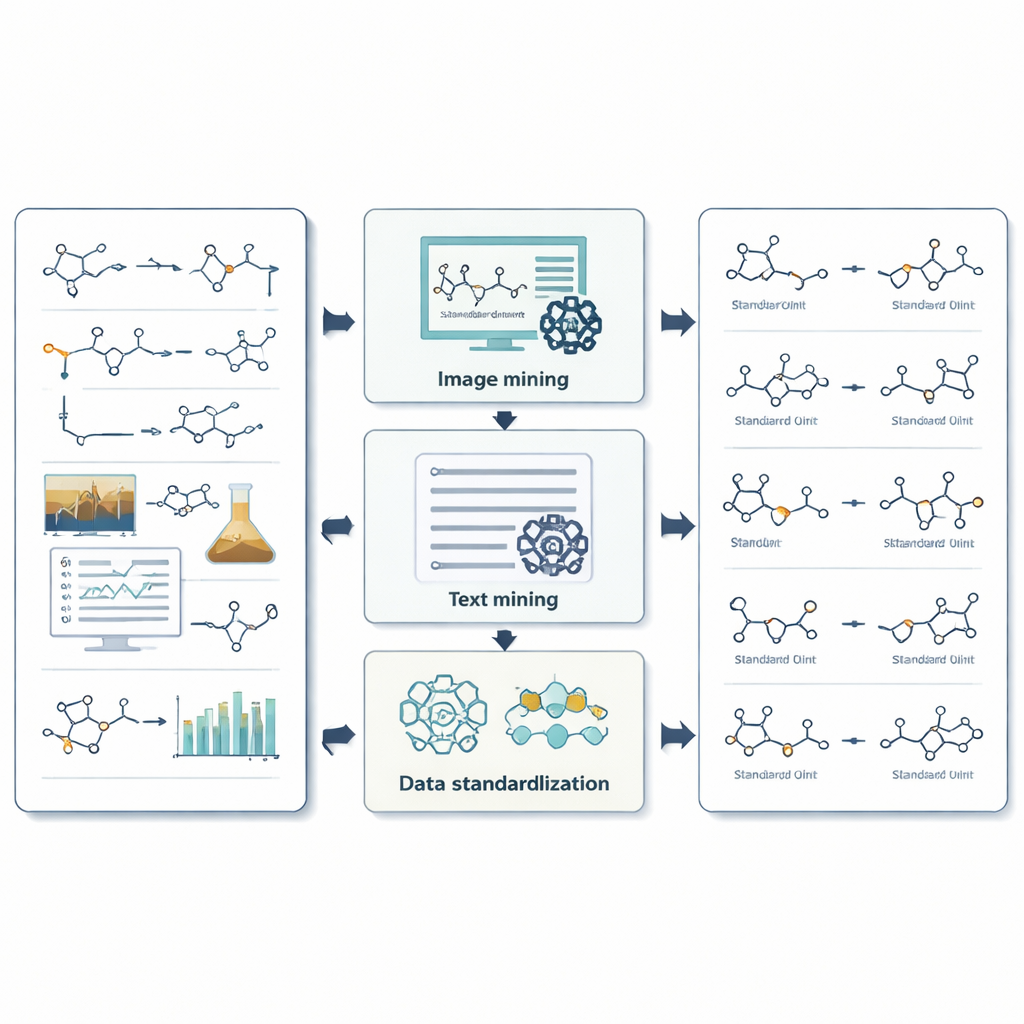
Jak system wydobywa informacje z obrazów, tekstu i liczb
W przypadku obrazów ReactionSeek korzysta z modelu językowego z funkcjami wizualnymi, by rozpoznać, które narysowane struktury odpowiadają którym etykietom i czy pełnią rolę substratów czy produktów. Osobny rozpoznawacz rysunków chemicznych przekształca te kształty w cyfrowe formaty molekularne zrozumiałe dla komputerów. Dla tekstu starannie opracowane prompt’y kierują modelem językowym przez zawiły styl opisów eksperymentalnych, pomagając mu wykrywać każdy związek, przypisać go do właściwego nagłówka i uchwycić warunki takie jak temperatura, czas i rozpuszczalnik. System idzie dalej, wydobywając złożone dane pomiarowe, jak widma NMR czy spektrometrię mas, na których chemicy polegają, by potwierdzić otrzymanie właściwej cząsteczki. Tam, gdzie uniwersalne narzędzia AI często się potykają — na przykład przekształcanie długich nazw chemicznych w dokładne struktury — ReactionSeek weryfikuje informacje względem publicznych baz chemicznych i dedykowanych programów nazwa→struktura, używając modelu językowego głównie jako inteligentnego dopasowującego, a nie jedynego decydenta.
Od jednego czasopisma do stulecia trendów chemicznych
Aby przetestować podejście, autorzy uruchomili ReactionSeek na 100 tomach Organic Syntheses, obejmujących reakcje opublikowane w latach 1921–2021. System przetworzył ponad trzy tysiące artykułów w minutach na artykuł, zamiast wielu godzin potrzebnych ludzkiemu kuratorowi. Zarejestrował składniki reakcji, warunki i wyniki z ponad 95% precyzją i czułością dla kluczowych pól. Nowo zorganizowany zestaw danych zawiera niemal cztery tysiące odrębnych reakcji i tysiące unikalnych związków, wszystkie na rzetelnej skali gramowej i zweryfikowane przez społeczność. Na bazie tego badacze zbudowali interaktywnego asystenta o nazwie SynChat, który pozwala chemikom zadawać pytania w języku naturalnym — opcjonalnie dołączając narysowane cząsteczki — i otrzymywać odpowiedzi oparte na wydobytej literaturze, wraz z odnośnikami do oryginalnych procedur.
Pozwolenie AI odkrywać wzorce w stuleciu eksperymentów
Gdy dane reakcyjne zostały uporządkowane, zespół użył innego zaawansowanego modelu językowego do wyszukania szerokich trendów w czasie. Nie podając mu z góry, czego się spodziewać, AI odkryło na nowo dobrze znane zmiany w dziedzinie: wzrost znaczenia katalizy asymetrycznej po około 1980 roku, przejście od prostych reagentów grup głównych ku wyrafinowanym katalizatorom metali przejściowych, oraz stopniowy spadek użycia wysoce toksycznych metali. Wyłapało również zmiany preferencji względem partnerów reakcji i metali katalitycznych, odzwierciedlając ewolucję narzędzi chemików na przestrzeni dekad. Wyniki te sugerują, że dostarczone bogatemu i godnemu zaufania zestawowi danych, AI może dostarczać historycznych i strategicznych wglądów zgodnych z wiedzą ekspertów.
Co to oznacza dla przyszłych odkryć chemicznych
Mówiąc prosto, ReactionSeek to most między zakurzonymi archiwami chemii a narzędziami AI, które obiecują przyspieszyć przyszłe odkrycia. Automatyzując żmudną pracę czytania, wydobywania i oczyszczania szczegółów reakcji, dostarcza wysokiej jakości, gotowe do użycia przez maszyny dane, które mogą zasilać lepsze modele predykcyjne, inteligentniejsze planowanie laboratoriów i bardziej intuicyjne narzędzia przeszukiwania dla naukowców. Chociaż system wciąż zmaga się z rzadkimi nazwami chemicznymi, złożonymi tabelami i nieidealnym rozpoznawaniem struktur, już pokazuje, że staranne projektowanie promptów i mądre połączenie AI z narzędziami opartymi na regułach mogą przekształcić nieustrukturyzowaną literaturę naukową w żywą bazę wiedzy. Zarówno dla chemików, jak i osób spoza specjalności, wskazuje to na przyszłość, w której dekady pracy eksperymentalnej można badać, kwestionować i rozwijać przy pomocy inteligentnych maszyn.
Cytowanie: Li, J., Li, M., Yang, Q. et al. ReactionSeek: LLM-powered literature data mining and knowledge discovery in organic synthesis. Nat Commun 17, 3356 (2026). https://doi.org/10.1038/s41467-026-70180-1
Słowa kluczowe: wydobywanie danych chemicznych, duże modele językowe, synteza organiczna, ekstrakcja tekstu naukowego, Sztuczna inteligencja w chemii