Clear Sky Science · ru
ReactionSeek: извлечение данных из литературы и открытие знаний в органическом синтезе с помощью больших языковых моделей
Почему важно превращать старые химические статьи в данные
Современные прорывы в медицине, материаловедении и «зеленых» технологиях всё чаще опираются на вычисления, которые выявляют закономерности и предлагают новые молекулы. Однако большая часть химических знаний по-прежнему скрыта в столетней массе научных публикаций, написанных для людей, а не для машин. В этой статье представлен ReactionSeek — система, которая обучает искусственный интеллект читать такие статьи, извлекать важные экспериментальные детали и преобразовывать их в организованные данные. Для всех, кто интересуется тем, как ИИ меняет науку — от поиска лекарств до более чистого производства — эта работа показывает, как мы наконец можем открыть огромный «скрытый архив» химии.
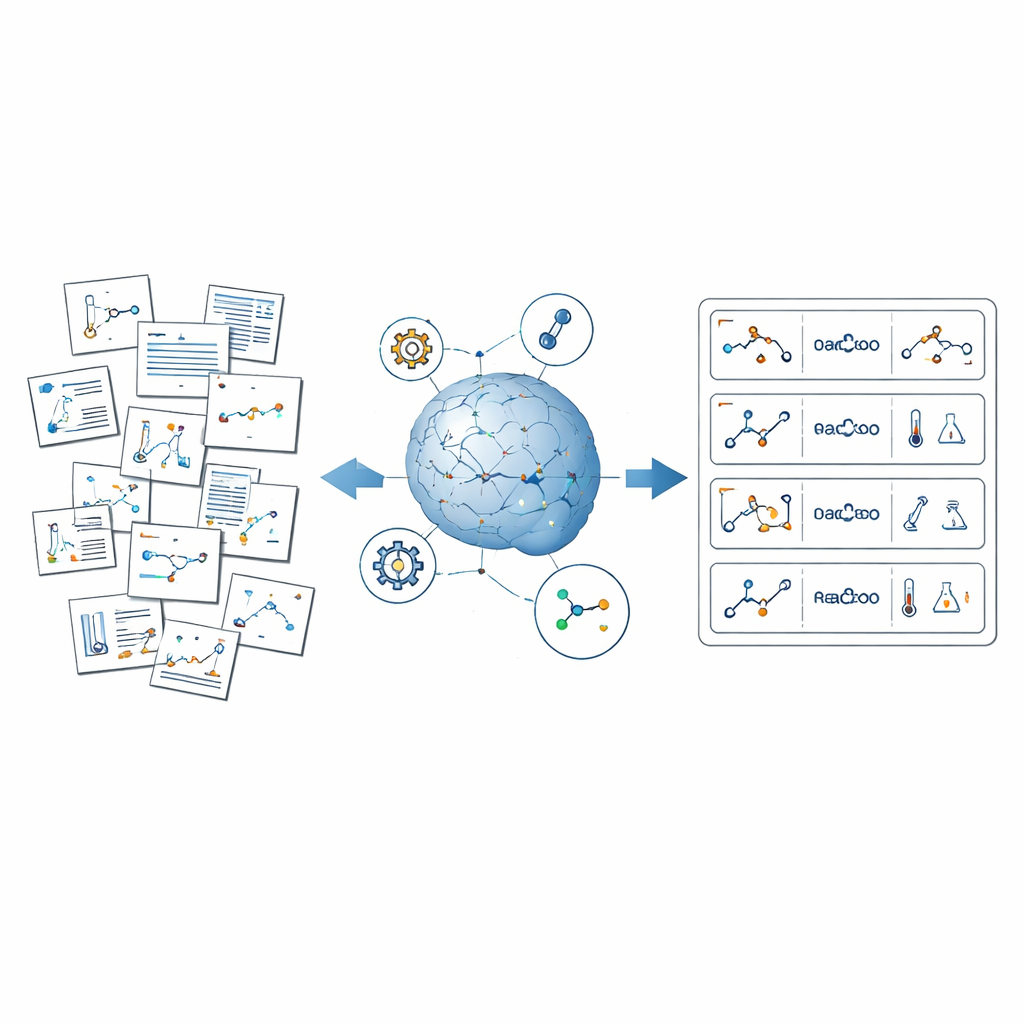
Проблема скрытых химических знаний
Органический синтез, ремесло по созданию сложных молекул из простых, лежит в основе химии. Исследователи опубликовали десятки тысяч детализированных рецептов, в которых указаны использованные компоненты, их количества, температуры и успешность реакций. Тем не менее эта информация разбросана по абзацам текста, схемам, таблицам и дополнительным материалам. Существующие базы данных охватывают лишь часть этого пространства, часто являются проприетарными и иногда пропускают редкие реакции. Автоматизированные лабораторные эксперименты могут генерировать аккуратные наборы данных, но они дороги и исследуют лишь узкий фрагмент химии. В результате большинство ИИ-инструментов обучаются на упрощённых, очищенных данных и не способны полностью отразить беспорядочное богатство реальной лабораторной работы.
Новый способ научить ИИ читать химические статьи
ReactionSeek решает эту задачу, сочетая большие языковые модели — ИИ, обученные понимать и генерировать текст и изображения — со специализированным химическим ПО. Фреймворк работает как автоматический читатель, пролистывающий статьи из многолетней коллекции Organic Syntheses. Сначала он анализирует схемы реакций и рисунки структур, связывая каждую набросанную молекулу с её ролью в реакции, например, исходным материалом или продуктом. Затем он читает письменные процедуры, чтобы извлечь такие детали, как использованные соединения, их количества, продолжительность реакций и полученные выходы. Наконец, всё стандартизируется — названия, единицы и форматы — так что тысячи статей можно объединить в единый согласованный и подлежащий поиску набор данных.
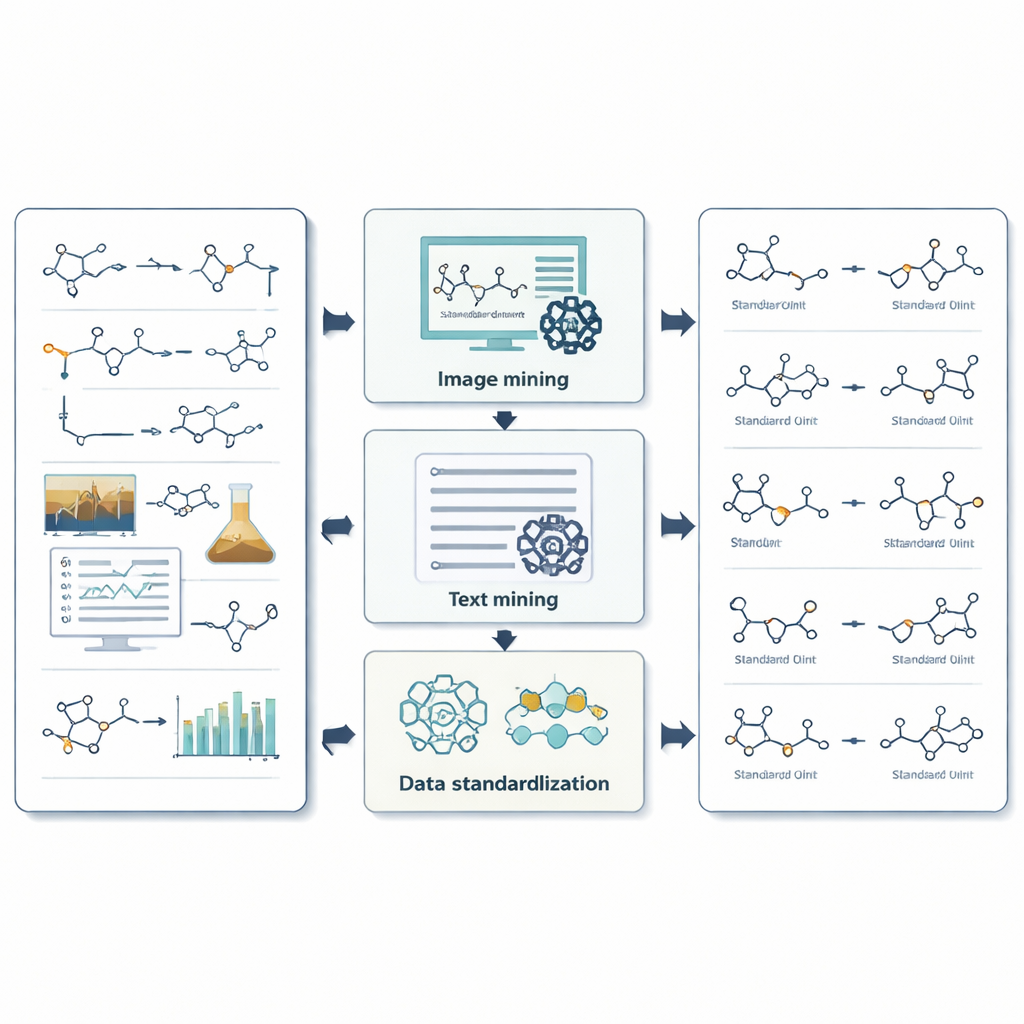
Как система обрабатывает изображения, текст и числа
Для изображений ReactionSeek использует языковую модель с возможностями зрения, чтобы определить, какие нарисованные структуры соответствуют каким меткам и выступают ли они в роли реагентов или продуктов. Отдельный распознаватель химических рисунков затем преобразует эти изображения в цифровые молекулярные форматы, с которыми может работать компьютер. Для текста тщательно оформленные подсказки направляют языковую модель через сложный стиль экспериментальных описаний, помогая ей обнаруживать каждое соединение, сопоставлять его с заголовком и фиксировать условия, такие как температура, время и растворитель. Система идёт дальше и извлекает сложные данные измерений — например, спектры ЯМР и масс-спектрометрию — которые химики используют для подтверждения правильности синтеза. Там, где универсальные ИИ-инструменты часто ошибаются — например, при переводе длинных химических названий в точные структуры — ReactionSeek сверяется с публичными химическими базами данных и специализированными программами «имя→структура», используя языковую модель главным образом как умного сопоставителя, а не единоличного решающего агента.
От одного журнала к столетию химических тенденций
Для проверки подхода авторы запустили ReactionSeek на 100 томах Organic Syntheses, охватывающих реакции, опубликованные с 1921 по 2021 год. Система обработала более трёх тысяч статей за минуты на статью вместо многих часов, которые потребовались бы человеческому куратору. Она извлекла ингредиенты реакций, условия и результаты с точностью и полнотой выше 95% для ключевых полей. Этот недавно структурированный набор данных содержит почти четыре тысячи различных реакций и тысячи уникальных соединений, все на надёжном граммовом масштабе и проверенные сообществом. Вдобавок исследователи создали интерактивного помощника SynChat, который позволяет химикам задавать вопросы на естественном языке — при желании включая нарисованные молекулы — и получать ответы, основанные на добытой литературе, с ссылками на исходные процедуры.
Позволяя ИИ обнаруживать закономерности в столетии экспериментов
Когда данные о реакциях были организованы, команда использовала другую продвинутую языковую модель для поиска общих трендов во времени. Не получив явных указаний, чего ожидать, ИИ вновь обнаружил известные сдвиги в области: рост асимметрического катализа после примерно 1980 года, переход от простых реагентов главной группы к сложным переходно-металлическим катализаторам и постепенное снижение использования высокотоксичных металлов. Он также выделил меняющиеся предпочтения в партнёрах по реакции и каталитических металлах, что отражает эволюцию инструментов химиков за десятилетия. Эти результаты показывают, что при наличии богатого и надёжного набора данных ИИ может давать исторические и стратегические инсайты, согласующиеся с экспертным пониманием.
Что это значит для будущих химических открытий
Проще говоря, ReactionSeek — это мост между пыльными архивами химии и ИИ-инструментами, которые обещают ускорить будущие открытия. Автоматизируя кропотливую работу по чтению, извлечению и очистке деталей реакций, система поставляет высококачественные данные, готовые для машинной обработки, которые могут питать лучшие предиктивные модели, более разумное планирование экспериментов и более интуитивный поиск для учёных. Хотя система всё ещё сталкивается с трудностями при редких химических названиях, сложных таблицах и несовершенном распознавании структур, она уже демонстрирует, что тщательная разработка подсказок и продуманный микс ИИ и правил может превратить неструктурированную научную литературу в живую базу знаний. Для химиков и неспециалистов это указывает на будущее, в котором десятилетия экспериментальной работы можно исследовать, ставить под вопрос и развивать при помощи интеллектуальных машин.
Цитирование: Li, J., Li, M., Yang, Q. et al. ReactionSeek: LLM-powered literature data mining and knowledge discovery in organic synthesis. Nat Commun 17, 3356 (2026). https://doi.org/10.1038/s41467-026-70180-1
Ключевые слова: добыча химических данных, большие языковые модели, органический синтез, извлечение научного текста, ИИ в химии