Clear Sky Science · it
ReactionSeek: estrazione di dati letterari e scoperta di conoscenza assistite da LLM nella sintesi organica
Perché trasformare vecchi articoli di chimica in dati è importante
I progressi moderni in medicina, materiali e tecnologie verdi si affidano sempre più ai computer per individuare schemi e suggerire nuove molecole. Ma la maggior parte del know-how chimico è ancora sepolta in un secolo di articoli di ricerca, scritti per esseri umani e non per macchine. Questo articolo presenta ReactionSeek, un sistema che insegna all’intelligenza artificiale a leggere questi articoli, estrarre i dettagli sperimentali rilevanti e trasformarli in dati organizzati. Per chiunque sia interessato a come l’IA stia cambiando la scienza — dalla scoperta di farmaci a processi produttivi più puliti — questo lavoro mostra come potremmo finalmente sbloccare il vasto “archivio nascosto” della chimica.
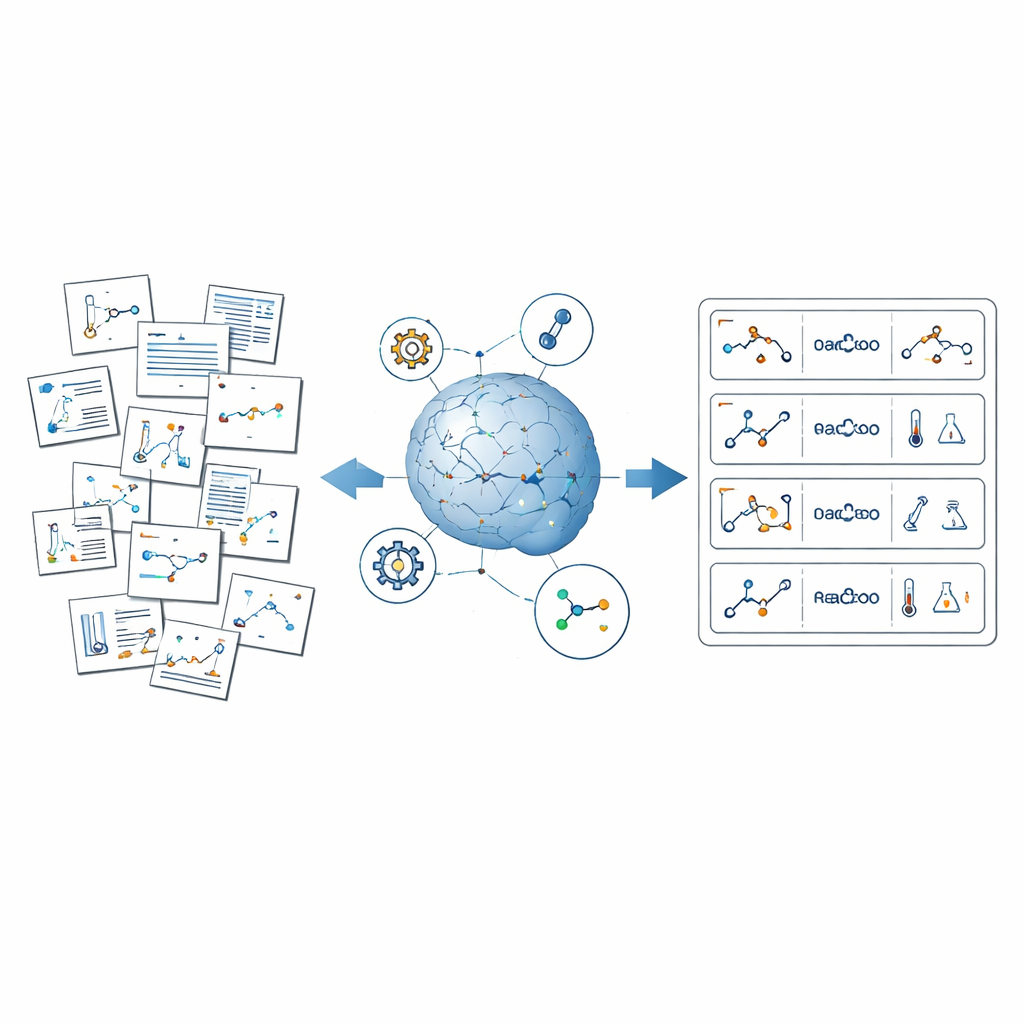
Il problema della conoscenza chimica nascosta
La sintesi organica, l’arte di costruire molecole complesse a partire da semplici precursori, è al cuore della chimica. I ricercatori hanno pubblicato decine di migliaia di ricette dettagliate che descrivono quali ingredienti sono stati usati, in quali quantità, a quale temperatura e con quale successo. Eppure queste informazioni sono disperse in paragrafi di testo, diagrammi, tabelle e file supplementari. I database esistenti coprono solo una frazione di questo panorama, sono spesso proprietari e talvolta trascurano reazioni inusuali. Gli esperimenti automatizzati in laboratorio possono generare dataset ordinati, ma sono costosi e esplorano solo un ambito ristretto della chimica. Di conseguenza, la maggior parte degli strumenti di IA viene addestrata su dati semplificati e ripuliti e non può riflettere pienamente la complessa ricchezza del lavoro sperimentale reale.
Un nuovo modo per insegnare all’IA a leggere gli articoli di chimica
ReactionSeek affronta questa sfida combinando large language model — sistemi di IA addestrati a comprendere e generare testo e immagini — con software chimici specializzati. Il framework funziona come un lettore automatico che passa in rassegna articoli della storica raccolta Organic Syntheses. Prima analizza i diagrammi di reazione e i disegni strutturali, collegando ogni molecola rappresentata al suo ruolo nella reazione, come materiale di partenza o prodotto. Poi legge le procedure scritte per estrarre dettagli quali i composti impiegati, le quantità, la durata delle reazioni e le rese ottenute. Infine, standardizza tutto — nomi, unità e formati — in modo che migliaia di articoli differenti possano essere aggregati in un unico dataset coerente e ricercabile.
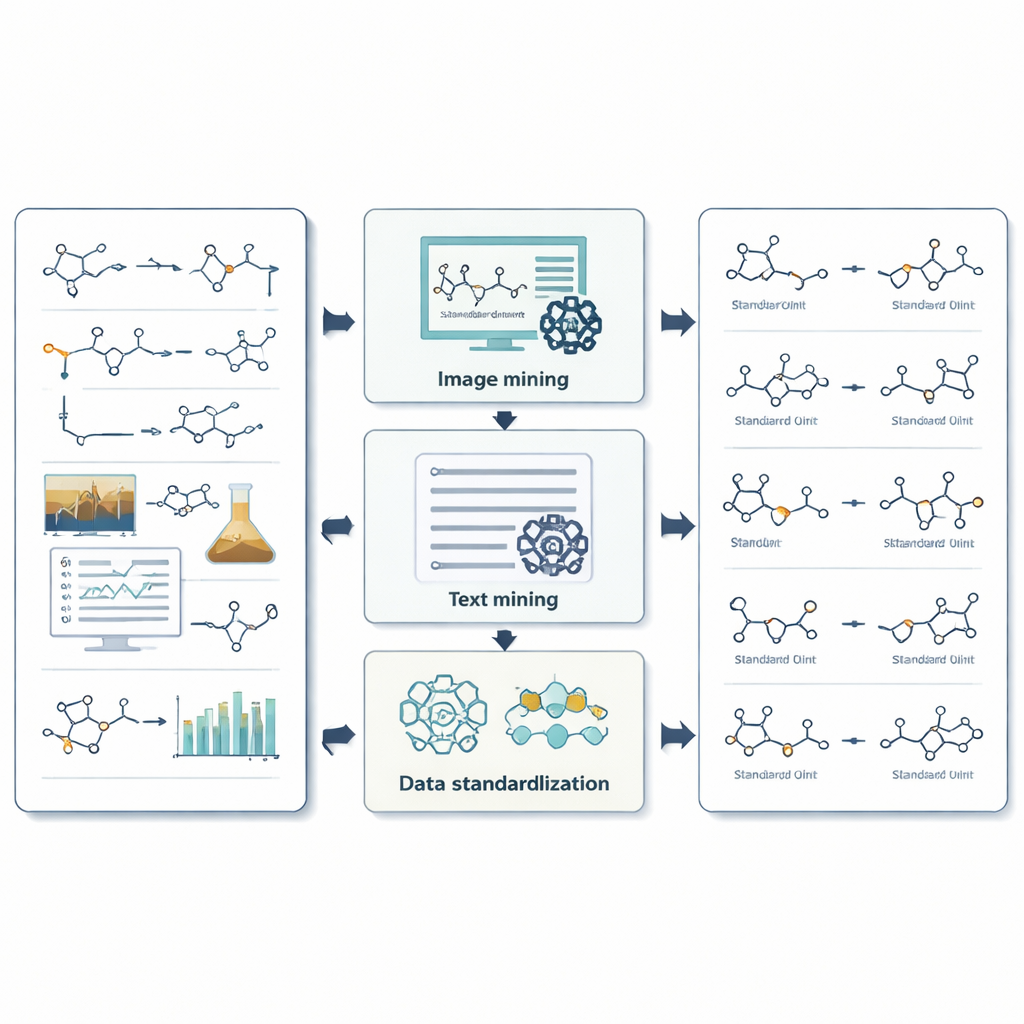
Come il sistema estrae immagini, testo e numeri
Per le immagini, ReactionSeek utilizza un modello linguistico con capacità visive per identificare quali strutture disegnate corrispondono a quali etichette e se agiscono da reagenti o prodotti. Un riconoscitore di disegni chimici separato converte poi queste rappresentazioni in formati molecolari digitali utilizzabili dai computer. Per il testo, prompt accuratamente progettati guidano il modello linguistico attraverso lo stile intricato delle descrizioni sperimentali, aiutandolo a rilevare ogni composto, abbinarlo all’intestazione corretta e registrare condizioni come temperatura, tempo e solvente. Il sistema va oltre estraendo dati di misurazione complessi, come spettri di risonanza magnetica nucleare e spettrometria di massa, su cui i chimici fanno affidamento per confermare la corretta identità delle molecole. Dove gli strumenti generici di IA spesso inciampano — ad esempio nella traduzione di nomi chimici lunghi in strutture esatte — ReactionSeek effettua controlli incrociati con database chimici pubblici e programmi dedicati da nome a struttura, usando il modello linguistico principalmente come un abbinatore intelligente piuttosto che come unico decisore.
Da una rivista a un secolo di tendenze chimiche
Per testare l’approccio, gli autori hanno applicato ReactionSeek a 100 volumi di Organic Syntheses, coprendo reazioni pubblicate dal 1921 al 2021. Il sistema ha processato oltre tremila articoli in minuti per articolo invece delle molte ore necessarie a un curatore umano. Ha catturato ingredienti, condizioni e risultati delle reazioni con oltre il 95% di precisione e richiamo per i campi chiave. Questo dataset strutturato contiene quasi quattromila reazioni distinte e migliaia di composti unici, tutti a scala di grammi affidabile e validati dalla comunità. Inoltre, i ricercatori hanno costruito un assistente interattivo chiamato SynChat, che permette ai chimici di porre domande in linguaggio naturale — includendo opzionalmente molecole disegnate — e ricevere risposte basate sulla letteratura estratta, complete di link alle procedure originali.
Lasciare che l’IA scopra schemi in un secolo di esperimenti
Una volta organizzati i dati di reazione, il team ha usato un altro modello linguistico avanzato per cercare tendenze di ampio respiro nel tempo. Senza essere esplicitamente istruito su cosa aspettarsi, l’IA ha riscoperto cambiamenti ben noti nel campo: l’ascesa della catalisi asimmetrica dopo circa il 1980, il passaggio da reagenti semplici di elementi principali verso catalizzatori sofisticati a base di metalli di transizione e il graduale declino di metalli altamente tossici. Ha anche individuato preferenze mutate nei partner di reazione e nei metalli catalitici, rispecchiando l’evoluzione degli strumenti dei chimici nel corso dei decenni. Questi risultati suggeriscono che, fornendo un dataset ricco e affidabile, l’IA può offrire intuizioni storiche e strategiche in linea con la comprensione degli esperti.
Cosa significa questo per la scoperta chimica futura
In termini semplici, ReactionSeek è un ponte tra archivi chimici impolverati e gli strumenti di IA che promettono di accelerare le scoperte future. Automatizzando il lavoro tedioso di lettura, estrazione e pulizia dei dettagli di reazione, fornisce dati di alta qualità e pronti per le macchine che possono alimentare modelli predittivi migliori, una pianificazione di laboratorio più intelligente e strumenti di ricerca più intuitivi per gli scienziati. Pur rimanendo sfide su nomi chimici rari, tabelle complesse e riconoscimento imperfetto delle strutture, il sistema dimostra già che una progettazione attenta dei prompt e una combinazione intelligente di IA e strumenti basati su regole possono trasformare la letteratura scientifica non strutturata in una base di conoscenza vivente. Per chimici e non specialisti, questo indica un futuro in cui decenni di lavoro sperimentale possono essere esplorati, interrogati e ampliati con l’aiuto di macchine intelligenti.
Citazione: Li, J., Li, M., Yang, Q. et al. ReactionSeek: LLM-powered literature data mining and knowledge discovery in organic synthesis. Nat Commun 17, 3356 (2026). https://doi.org/10.1038/s41467-026-70180-1
Parole chiave: estrazione di dati chimici, large language models, sintesi organica, estrazione di testi scientifici, IA in chimica