Clear Sky Science · ru
Масштабируемый конфликт‑свободный алгоритм bandit на основе квантовой оптической схемы
Свет, который помогает нам делить ресурсы без столкновений
Многие современные технологии, от сетей Wi‑Fi до онлайн‑рекламы, вынуждены одновременно обслуживать нескольких пользователей, каждый из которых стремится выбрать наилучший вариант. Когда два человека или устройства незаметно делают один и тот же выбор, они мешают друг другу, и всем становится хуже. В этой статье показано, как тщательно сконструированный пучок квантового света может выступать в роли беспристрастного арбитра, незаметно направляя двух независимых принимающих решения к хорошим вариантам и предотвращая выбор одинаковой опции — без какой‑либо прямой связи между ними.
Выборы, вознаграждения и проблема концентрации
Инженеры часто моделируют повторяющееся принятие решений с помощью модели «многорукого бандита», вдохновлённой рядом игровых автоматов. Каждая опция даёт вознаграждение с некоторой скрытой вероятностью, поэтому игроку нужно балансировать между исследованием разных вариантов, чтобы узнать о них, и эксплуатацией тех, которые кажутся лучшими. Задача становится значительно труднее, когда несколько игроков сталкиваются с одними и теми же опциями и каждый хочет получить высокооплачиваемые. Если они выбирают одну и ту же опцию одновременно, им приходится делить вознаграждение. Эта ситуация, называемая конкурентной задачей многоруких бандитов, отражает реальные задачи, такие как распределение радиочастот между беспроводными устройствами или выделение серверов для трафика — когда слишком много пользователей сосредоточиваются на одном канале, это вредит всем.
Использование закрученного света как общего механизма принятия решений
Авторы строят решение на одних фотонах — частицах света — чьи волновые структуры закручены, подобно маленьким штопорам, свойство, известное как орбитальный угловой момент. Поскольку эти закрученные световые режимы можно различать и, в принципе, поддерживать множество различных «режимов», они предоставляют большой набор меток, которые могут соответствовать разным вариантам. В предлагаемой схеме источник генерирует пару связанных фотонов, которые направляются к двум отдельным игрокам через систему зеркал и полупрозрачных пластин. Каждый игрок пропускает свой фотон через программируемое устройство, формирующее его закрученную структуру так, чтобы яркость каждого режима отражала, насколько сильно в данный момент этот игрок предпочитает ту или иную опцию, на основании своих прошлых выигрышей и проигрышей.
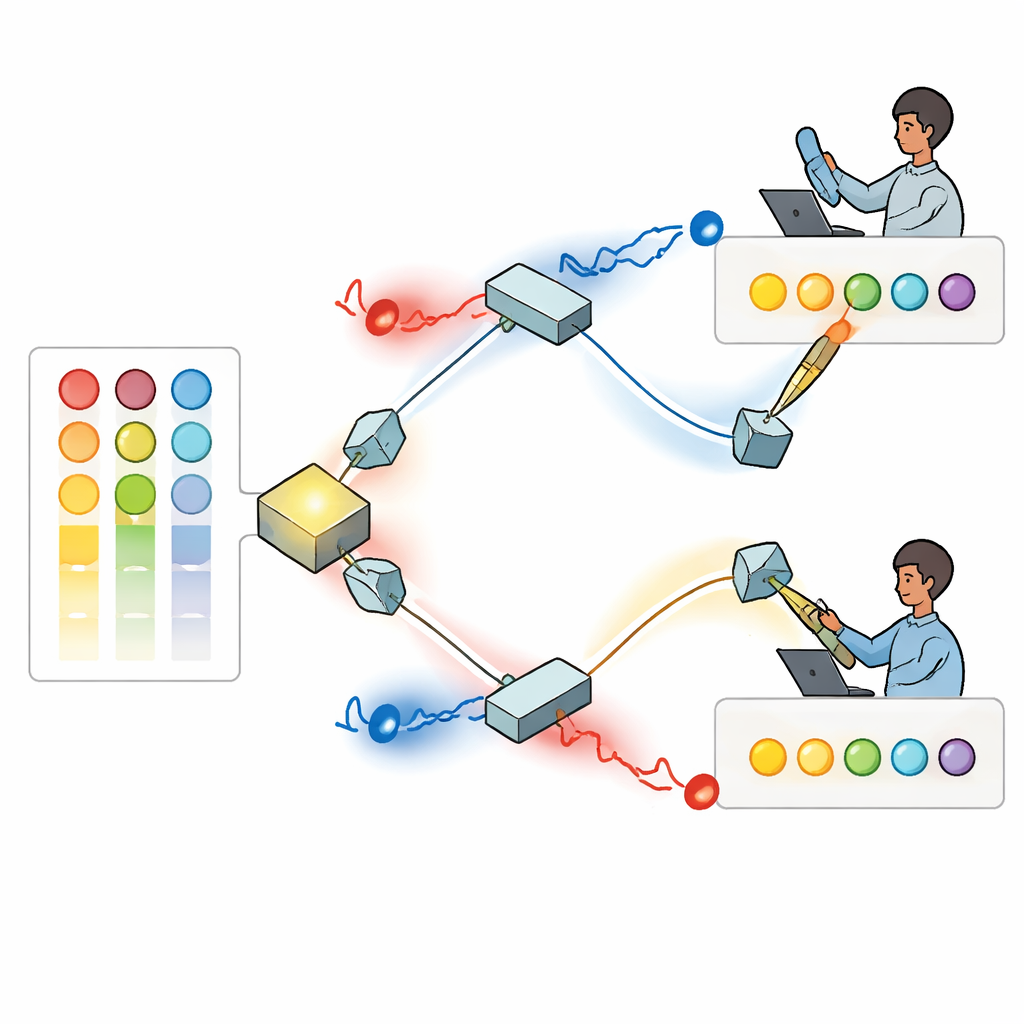
Квантовая интерференция для предотвращения коллизий
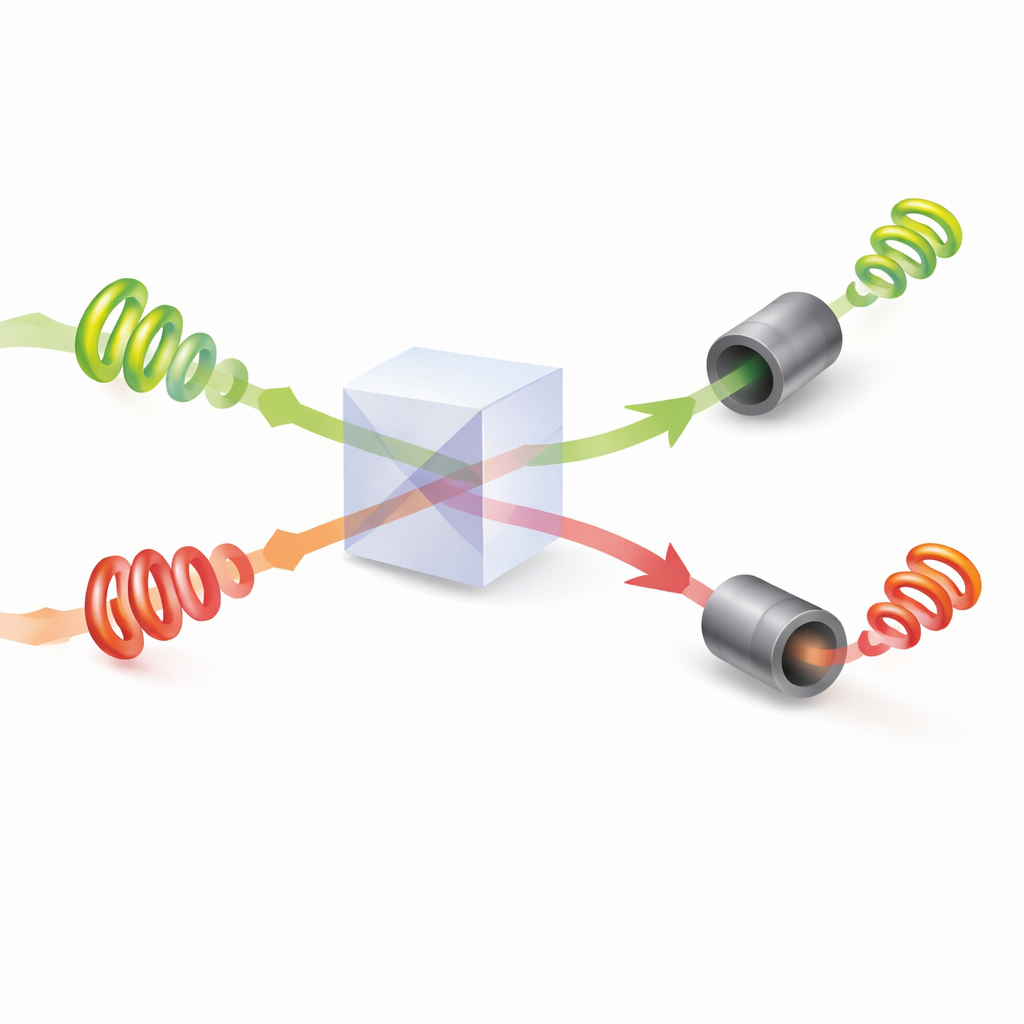
После того как их структуры заданы, пара фотонов встречается на разделителе пучка, где происходит квантовая интерференция: комбинированные световые волны могут усиливать или гасить друг друга в зависимости от относительных закруток и фаз. Исследователи показывают, как настроить скрытые углы фаз света так, чтобы всякий раз, когда два фотона выходят по разным выходным путям, они гарантированно имели разные значения закрутки. Затем каждый игрок измеряет абсолютную величину закрутки своего фотона и интерпретирует это значение как конкретную опцию для выбора. Благодаря интерференции они никогда не получают одинаковой инструкции при успешном обнаружении обоих фотонов. Фактически физика света сама по себе обеспечивает правило «без коллизий», чего невозможно добиться с помощью обычного, классического света.
Обучение при масштабировании на многие опции
Оптическая система связана с простым правилом обучения, которое постепенно переводит каждого игрока от широкого исследования в сторону предпочтения более выгодных опций в течение многих раундов. Существенно, что в отличие от ранних оптических схем, которые кодировали предпочтения затемнением света — тратя всё больше фотонов по мере увеличения числа опций — эта конструкция встраивает предпочтения непосредственно в закрученную структуру каждого фотона. Авторы анализируют, как часто фотоны выходят по разным путям, насколько выборы, полученные в результате, соответствуют намеренным профилям предпочтений игроков, и сколько «сожаления» накапливается, то есть потерянного вознаграждения по сравнению с идеальной стратегией. В больших компьютерных симуляциях с пятью и десятью опциями их метод стабильно приносил больше вознаграждений, адаптировался быстрее и был менее чувствителен к настройкам, чем предыдущие подходы.
Что это значит для реальных систем
Помимо математической эффективности, подход намечает новый стиль аппаратного обеспечения, где свет выполняет часть вычислительной работы. Поскольку координация происходит физически через интерференцию, а не через цифровые сообщения, два устройства могут избегать помех друг другу, не раскрывая своих внутренних приоритетов. Авторы утверждают, что такой конфликт‑свободный, пропускная способность и сохраняющий приватность движок принятия решений однажды может быть встроен в оптические каналы дата‑центров или в радиосистемы, которые должны быстро захватывать свободные каналы с минимальным обменом сообщениями. Хотя в настоящей работе демонстрация проведена в симуляции для двух игроков, она показывает, как особенности квантовой оптики можно использовать для решения сложных задач обучения и координации способами, которые обычная электроника повторить не может.
Цитирование: Konaka, K., Röhm, A., Mihana, T. et al. Scalable conflict-free bandit algorithm using a quantum optical setup. npj Quantum Inf 12, 44 (2026). https://doi.org/10.1038/s41534-026-01201-6
Ключевые слова: квантовая оптика, обучение с подкреплением, многорукий бандит, орбитальный угловой момент, фотонное принятие решений