Clear Sky Science · es
Algoritmo escalable de bandido sin conflictos usando un montaje óptico cuántico
La luz nos ayuda a compartir sin chocar
Muchas tecnologías modernas, desde redes Wi‑Fi hasta la publicidad en línea, deben atender a múltiples usuarios que a la vez buscan la mejor opción. Cuando dos personas o dispositivos eligen sin saberlo la misma alternativa, se interfieren mutuamente y el rendimiento de todos empeora. Este artículo muestra cómo un haz de luz cuántica diseñado con cuidado puede actuar como un árbitro imparcial, orientando discretamente a dos tomadores de decisiones independientes hacia buenas elecciones y evitando que seleccionen la misma opción, sin comunicación directa entre ellos.
Opciones, recompensas y el problema de la congestión
Los ingenieros suelen modelar la toma de decisiones repetida con el marco del “bandido multi‑armado”, inspirado en filas de máquinas tragamonedas. Cada opción entrega una recompensa con cierta probabilidad oculta, por lo que un jugador debe equilibrar probar alternativas para aprender sobre ellas frente a explotar las que parecen mejores. El desafío se complica mucho cuando varios jugadores enfrentan las mismas opciones y cada uno persigue las de mayor rendimiento. Si coinciden en elegir la misma opción al mismo tiempo, deben compartir la recompensa. Esta situación, llamada problema competitivo del bandido multi‑armado, captura tareas del mundo real como asignar frecuencias de radio a dispositivos inalámbricos o distribuir servidores entre flujos de datos, donde demasiados usuarios concentrados en un mismo canal perjudican a todos.
Usar luz retorcida como motor de decisiones compartido
Los autores construyen una solución usando fotones individuales —partículas de luz— cuyos patrones de onda giran como pequeños sacacorchos, una propiedad conocida como momento angular orbital. Debido a que estos patrones de luz retorcida pueden distinguirse y, en principio, admitir muchos “modos” distintos, proporcionan un amplio catálogo de etiquetas que pueden representar diferentes opciones. En el montaje propuesto, una fuente genera un par de fotones entrelazados que se dirigen a dos jugadores separados mediante una disposición de espejos y divisores de haz. Cada jugador hace pasar su fotón por un dispositivo programable que moldea su patrón retorcido de modo que la intensidad de cada modo refleje la preferencia actual de ese jugador por cada opción, basada en sus victorias y pérdidas previas.
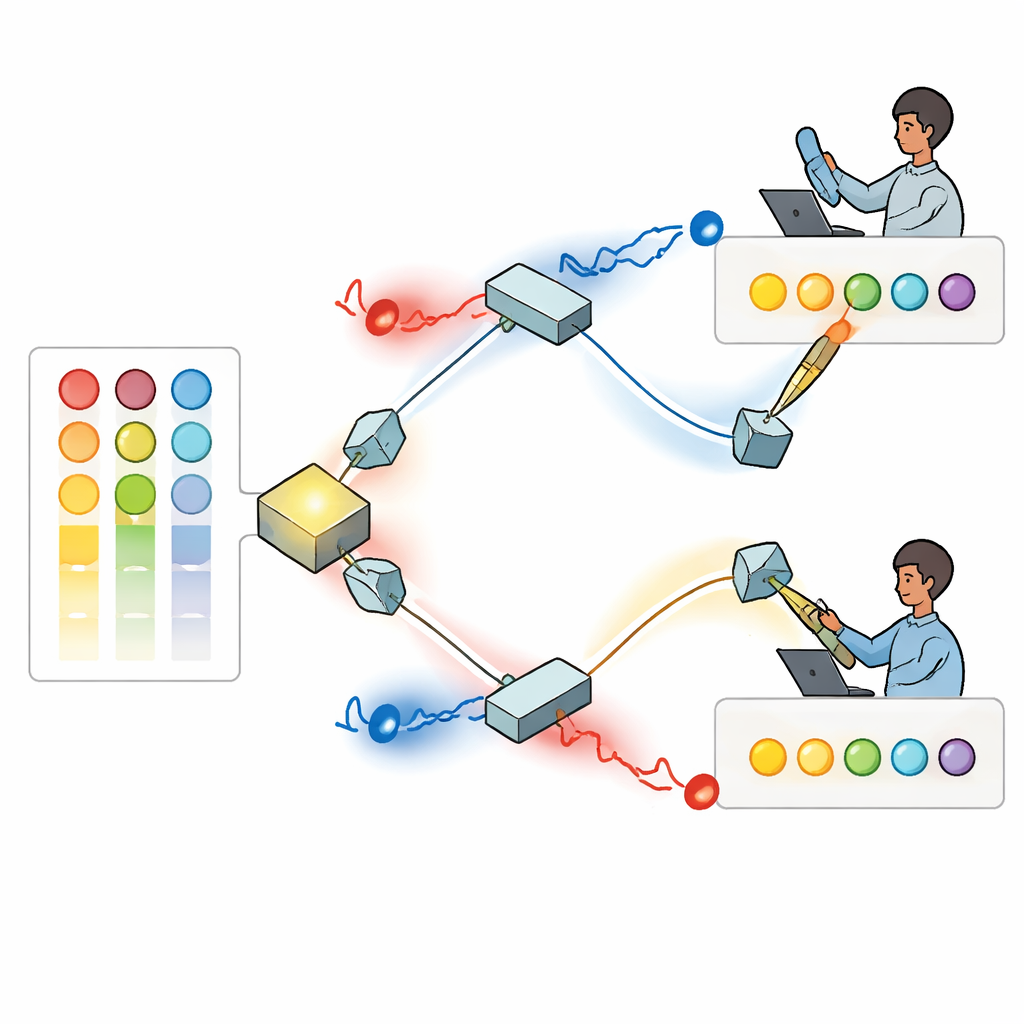
Interferencia cuántica para evitar colisiones
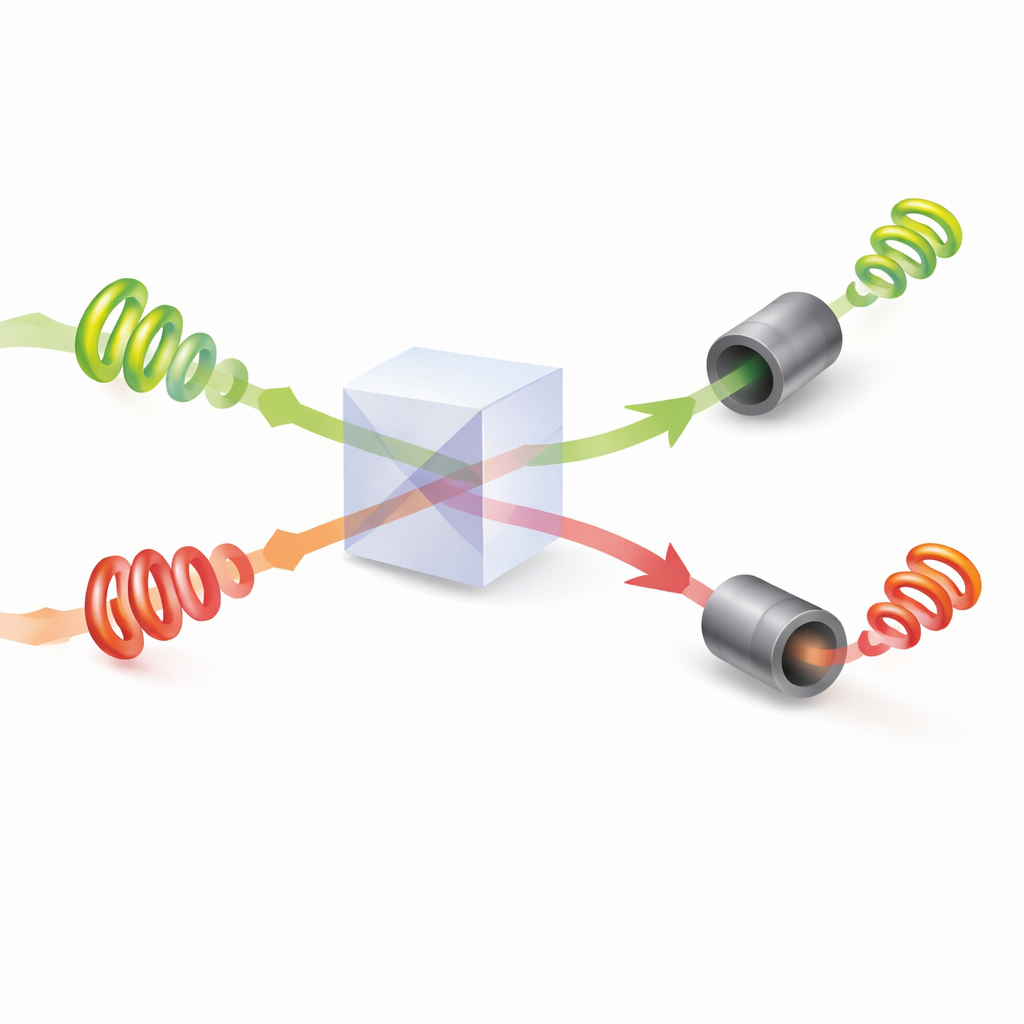
Tras ajustar sus patrones, el par de fotones se encuentra en un divisor de haz donde ocurre interferencia cuántica: las ondas combinadas pueden reforzarse o cancelarse según sus torsiones y fases relativas. Los investigadores muestran cómo ajustar los ángulos de fase ocultos de la luz de modo que, siempre que los dos fotones emergen por salidas distintas, se garantice que llevan valores de torsión diferentes. Cada jugador entonces mide la magnitud absoluta de torsión de su fotón e interpreta ese valor como la opción concreta a elegir. Debido a la interferencia, nunca reciben la misma instrucción cuando ambos fotones se detectan con éxito. En efecto, la propia física de la luz impone una regla de no‑colisión, algo que es imposible reproducir con luz ordinaria clásica.
Aprender escalando a muchas opciones
El sistema óptico se acopla a una regla de aprendizaje simple que va desplazando gradualmente a cada jugador desde una exploración amplia hacia favorecer opciones de mayor recompensa a lo largo de muchas rondas. Crucialmente, a diferencia de esquemas ópticos anteriores que codificaban preferencias atenuando la luz —malgastando cada vez más fotones cuando aumentaba el número de opciones—, este diseño incrusta las preferencias directamente en el patrón de torsión de cada fotón. Los autores analizan con qué frecuencia los fotones salen por caminos separados, cuánto se ajustan las elecciones resultantes a los patrones de preferencia previstos por los jugadores y cuánta “remordimiento” se acumula, es decir, recompensa perdida en comparación con una estrategia ideal. En grandes simulaciones por ordenador con cinco y diez opciones, su método consiguió de forma consistente mayores recompensas, se adaptó más rápido y fue menos sensible a los ajustes que el enfoque anterior.
Qué implica esto para sistemas del mundo real
Más allá de su rendimiento matemático, el enfoque apunta a un nuevo estilo de hardware en el que la luz realiza parte del procesamiento. Como la coordinación ocurre físicamente mediante interferencia en lugar de mediante mensajes digitales, dos dispositivos pueden evitar pisarse mutuamente sin revelar sus prioridades internas. Los autores sostienen que un motor de decisiones sin conflictos, de alto rendimiento y respetuoso con la privacidad podría algún día incorporarse en enlaces ópticos de centros de datos o en sistemas de radio que necesiten capturar rápidamente canales libres con mínima comunicación. Aunque el trabajo actual se demuestra en simulación para dos jugadores, muestra cómo las particularidades de la óptica cuántica pueden aprovecharse para abordar tareas complejas de aprendizaje y coordinación de formas que la electrónica estándar no puede igualar fácilmente.
Cita: Konaka, K., Röhm, A., Mihana, T. et al. Scalable conflict-free bandit algorithm using a quantum optical setup. npj Quantum Inf 12, 44 (2026). https://doi.org/10.1038/s41534-026-01201-6
Palabras clave: óptica cuántica, aprendizaje por refuerzo, bandido multiarmado, momento angular orbital, toma de decisiones fotónica