Clear Sky Science · nl
Schaalbaar botsingsvrij bandietalgoritme met behulp van een kwantumoptische opstelling
Licht dat ons helpt delen zonder te botsen
Veel moderne technologieën, van Wi‑Fi-netwerken tot online reclame, moeten meerdere gebruikers tegelijk bedienen die allemaal de beste optie willen. Wanneer twee mensen of apparaten onbedoeld dezelfde keuze maken, staan ze elkaar in de weg en presteren iedereen slechter. Dit artikel laat zien hoe een zorgvuldig ontworpen bundel kwantumlicht als een onpartijdige scheidsrechter kan optreden: stilletjes twee onafhankelijke beslissers naar goede keuzes sturen en voorkomen dat ze dezelfde optie kiezen — zonder direkte communicatie tussen hen.
Keuzes, beloningen en het probleem van drukte
Ingenieurs modelleren herhaald beslissen vaak met het “multi‑armed bandit”-kader, geïnspireerd door rijen gokautomaten. Elke optie geeft een beloning met een verborgen kans, dus een speler moet afwegen tussen het uitproberen van verschillende opties om erover te leren en het vasthouden aan diegene die goed lijken. De uitdaging wordt veel groter als meerdere spelers voor dezelfde opties staan en iedereen de hoogst renderende wil. Als ze tegelijk dezelfde optie kiezen, moeten ze de beloning delen. Deze situatie, het competitieve multi‑armed bandit‑probleem genoemd, weerspiegelt praktijkproblemen zoals het toewijzen van radiokanalen aan draadloze apparaten of het toekennen van servers aan dataverkeer, waar te veel gebruikers op hetzelfde kanaal iedereen schaadt.
Gedraaid licht gebruiken als gedeelde besluitvormingsmotor
De auteurs bouwen een oplossing met enkele fotonen — lichtdeeltjes — waarvan de golfpatronen ronddraaien als kleine kurkentrekkers, een eigenschap die bekendstaat als orbital angular momentum. Omdat deze gedraaide lichtpatronen te onderscheiden zijn en in principe veel verschillende “modi” kunnen ondersteunen, bieden ze een groot aanbod aan labels die als verschillende keuzes kunnen dienen. In de voorgestelde opstelling genereert een bron een paar gekoppelde fotonen die via spiegels en beam splitters naar twee afzonderlijke spelers worden geleid. Elke speler laat zijn foton door een programmeerbaar apparaat gaan dat het gedraaide patroon vormt, zodat de helderheid van elke modus aangeeft hoe sterk die speler op dat moment een optie verkiest, op basis van zijn eigen eerdere overwinningen en verliezen.
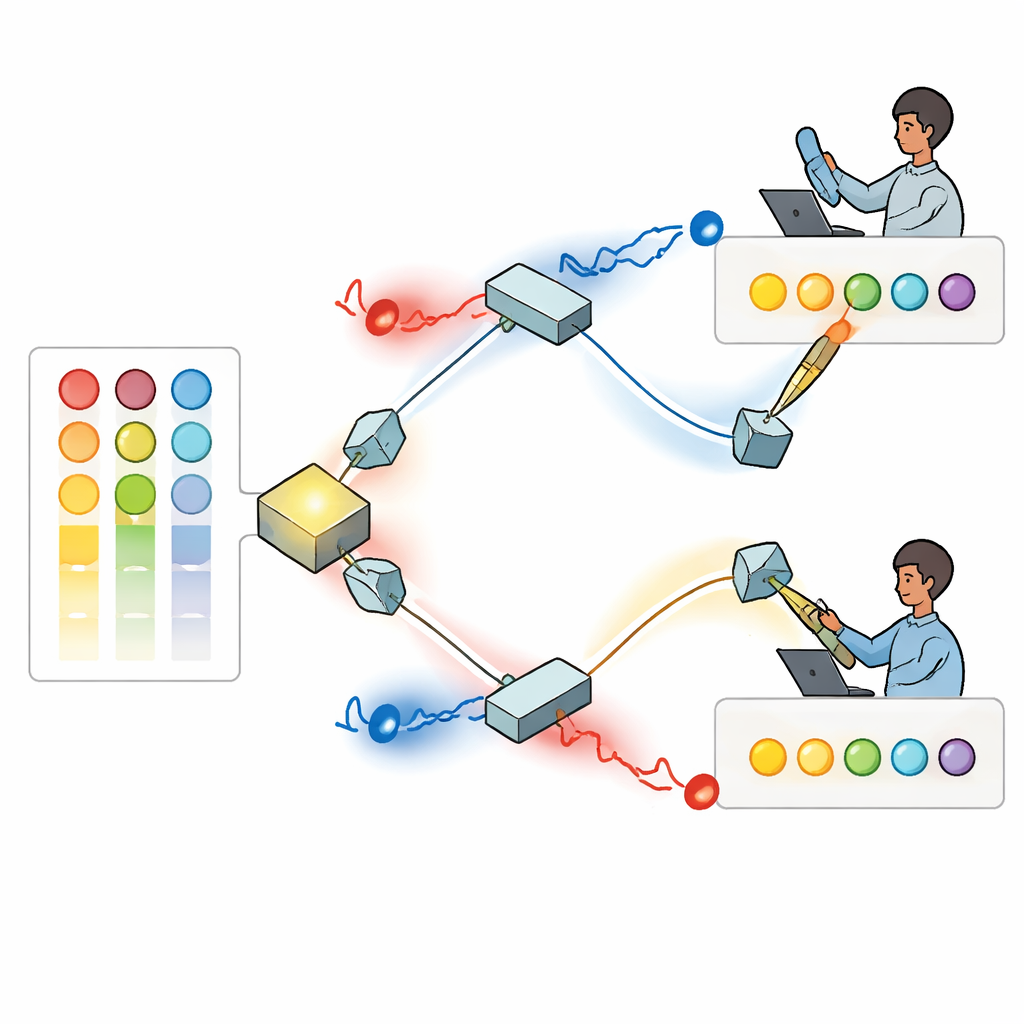
Kwantuminterferentie om botsingen te voorkomen
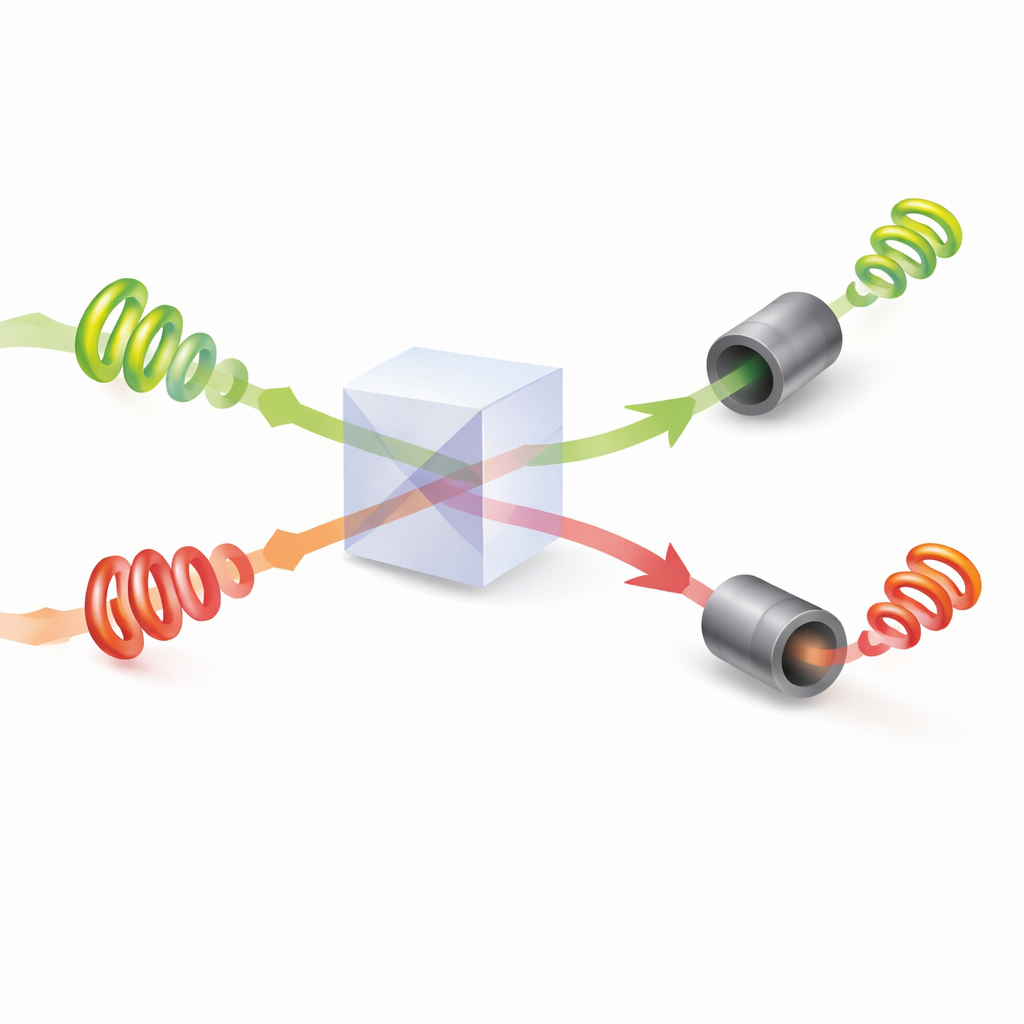
Nadat de patronen zijn ingesteld, ontmoeten de twee fotonen elkaar bij een beam splitter waar kwantuminterferentie optreedt: de gecombineerde lichtgolven kunnen elkaar versterken of uitwissen afhankelijk van hun relatieve draaiingen en fasen. De onderzoekers tonen aan hoe de verborgen fasehoeken van het licht kunnen worden afgesteld zodat, telkens wanneer de twee fotonen uit verschillende uitgangen komen, ze gegarandeerd verschillende draaisnelheden dragen. Elke speler meet vervolgens de absolute hoeveelheid draaiing op zijn foton en interpreteert die waarde als een specifieke optie om te kiezen. Door de interferentie ontvangen ze nooit dezelfde aanwijzing wanneer beide fotonen succesvol worden gedetecteerd. In feite dwingt de fysica van het licht zelf een botsingsvrije regel af — iets wat met gewoon, klassiek licht niet na te bootsen is.
Leren terwijl het opschaalt naar veel opties
Het optische systeem is gekoppeld aan een eenvoudige leerregel die elke speler geleidelijk verschuift van brede exploratie naar het bevoordelen van beter renderende opties over vele ronden. Cruciaal is dat, anders dan eerdere optische schema’s die afhankelijk waren van het dimmen van licht om voorkeuren te coderen — waardoor steeds meer fotonen werden verspild naarmate het aantal opties groeide — dit ontwerp de voorkeuren direct in het draaipatroon van elk foton inbouwt. De auteurs analyseren hoe vaak de fotonen in gescheiden paden uitkomen, hoe goed de resulterende keuzes overeenkomen met de bedoelde voorkeurspatronen van de spelers, en hoeveel “spijt” zich ophoopt, dat wil zeggen gemiste beloning vergeleken met een ideale strategie. In grote computersimulaties met vijf en tien opties behaalde hun methode consequent hogere beloningen, paste zich sneller aan en was minder gevoelig voor afstellingen dan de eerdere benadering.
Wat dit betekent voor systemen in de praktijk
Buiten de wiskundige prestaties suggereert de aanpak een nieuwe soort hardware waarin licht een deel van het denkwerk doet. Omdat de coördinatie fysiek via interferentie plaatsvindt in plaats van via digitale berichten, kunnen twee apparaten elkaar ontwijken zonder hun interne prioriteiten prijs te geven. De auteurs bepleiten dat zo’n botsingsvrije, hoge‑doorvoerende en privacy‑behoudende besluitvormingsmotor op termijn ingebouwd kan worden in optische verbindingen in datacenters of in radiosystemen die snel vrijgekomen kanalen moeten grijpen met minimale communicatie. Hoewel het huidige werk in simulatie voor twee spelers wordt gedemonstreerd, laat het zien hoe de eigenaardigheden van kwantumoptica kunnen worden benut om complexe leer‑ en coördinatietaken aan te pakken op manieren die standaard elektronica niet gemakkelijk kan evenaren.
Bronvermelding: Konaka, K., Röhm, A., Mihana, T. et al. Scalable conflict-free bandit algorithm using a quantum optical setup. npj Quantum Inf 12, 44 (2026). https://doi.org/10.1038/s41534-026-01201-6
Trefwoorden: kwantumoptica, versterkend leren, multi-armed bandit, orbitaal bewegingsmoment, fotonsche besluitvorming