Clear Sky Science · de
Skalierbarer konfliktfreier Bandit‑Algorithmus mit einem quantenoptischen Aufbau
Licht, das uns beim Teilen ohne Zusammenstöße hilft
Viele moderne Technologien, von Wi‑Fi‑Netzen bis zur Online‑Werbung, müssen mehrere Nutzer koordinieren, die gleichzeitig die beste Option wollen. Wenn zwei Personen oder Geräte unabsichtlich dieselbe Wahl treffen, behindern sie sich gegenseitig und alle schneiden schlechter ab. Diese Arbeit zeigt, wie ein sorgfältig gestalteter Strahl quantenmechanischen Lichts als unparteiischer Schiedsrichter wirken kann, der zwei unabhängige Entscheidungsträger leise zu guten Entscheidungen lenkt und zugleich verhindert, dass sie dieselbe Option wählen — ganz ohne direkte Kommunikation zwischen ihnen.
Auswahl, Belohnungen und das Problem der Überfüllung
Ingenieure modellieren wiederholte Entscheidungsprozesse oft mit dem „Multi‑Armed‑Bandit“‑Rahmen, inspiriert von Reihen von Spielautomaten. Jede Option liefert mit einer verborgenen Wahrscheinlichkeit eine Belohnung, sodass ein Spieler ausprobieren muss, um zu lernen, welche Optionen gut sind, und zugleich jene bevorzugen sollte, die sich bewährt haben. Die Aufgabe wird deutlich schwieriger, wenn mehrere Spieler vor denselben Optionen stehen und alle die ertragsstarken wollen. Treffen sie gleichzeitig dieselbe Wahl, müssen sie die Belohnung teilen. Diese Situation, das konkurrierende Multi‑Armed‑Bandit‑Problem, beschreibt reale Aufgaben wie das Zuweisen von Funkfrequenzen an drahtlose Geräte oder das Zuteilen von Serverressourcen für Datenverkehr: Wenn zu viele Nutzer auf denselben Kanal drängen, leidet die Leistung aller.
Verdrehtes Licht als gemeinsame Entscheidungsmaschine
Die Autoren entwickeln eine Lösung mit Einzelphotonen — Lichtteilchen — deren Wellenmuster wie kleine Korkenzieher wirbeln, eine Eigenschaft, die als Bahndrehimpuls (orbital angular momentum) bekannt ist. Da sich diese verdrehten Lichtmuster unterscheiden lassen und prinzipiell viele verschiedene Modi unterstützen können, bieten sie eine große Auswahl an Kennzeichnungen, die für unterschiedliche Entscheidungen stehen können. Im vorgeschlagenen Aufbau erzeugt eine Quelle ein Paar verschränkter Photonen, die über ein System aus Spiegeln und Strahlteilern zu zwei getrennten Spielern geleitet werden. Jeder Spieler lässt sein Photon durch ein programmierbares Bauteil laufen, das dessen verdrehtes Muster formt, sodass die Helligkeit jedes Modus widerspiegelt, wie stark der Spieler aktuell jede Option bevorzugt — basierend auf seinen bisherigen Erfolgen und Misserfolgen.
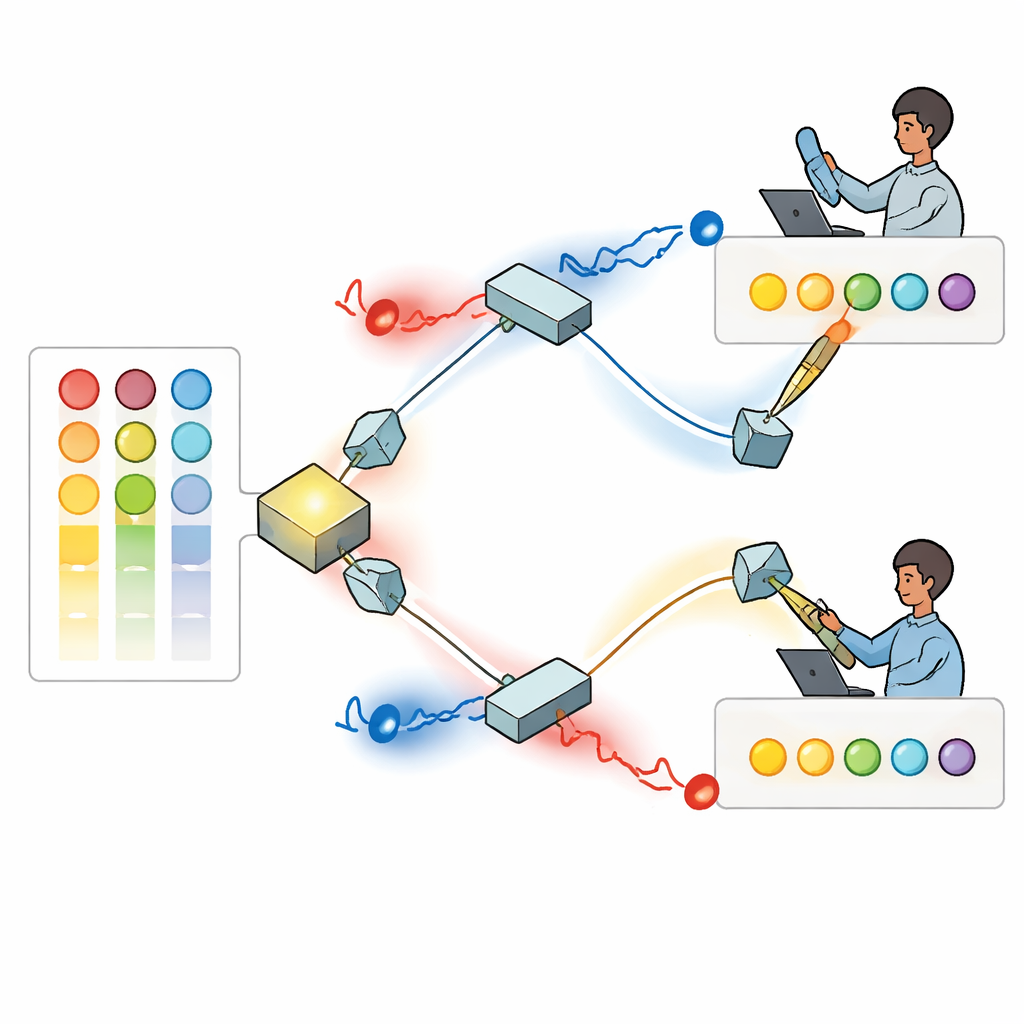
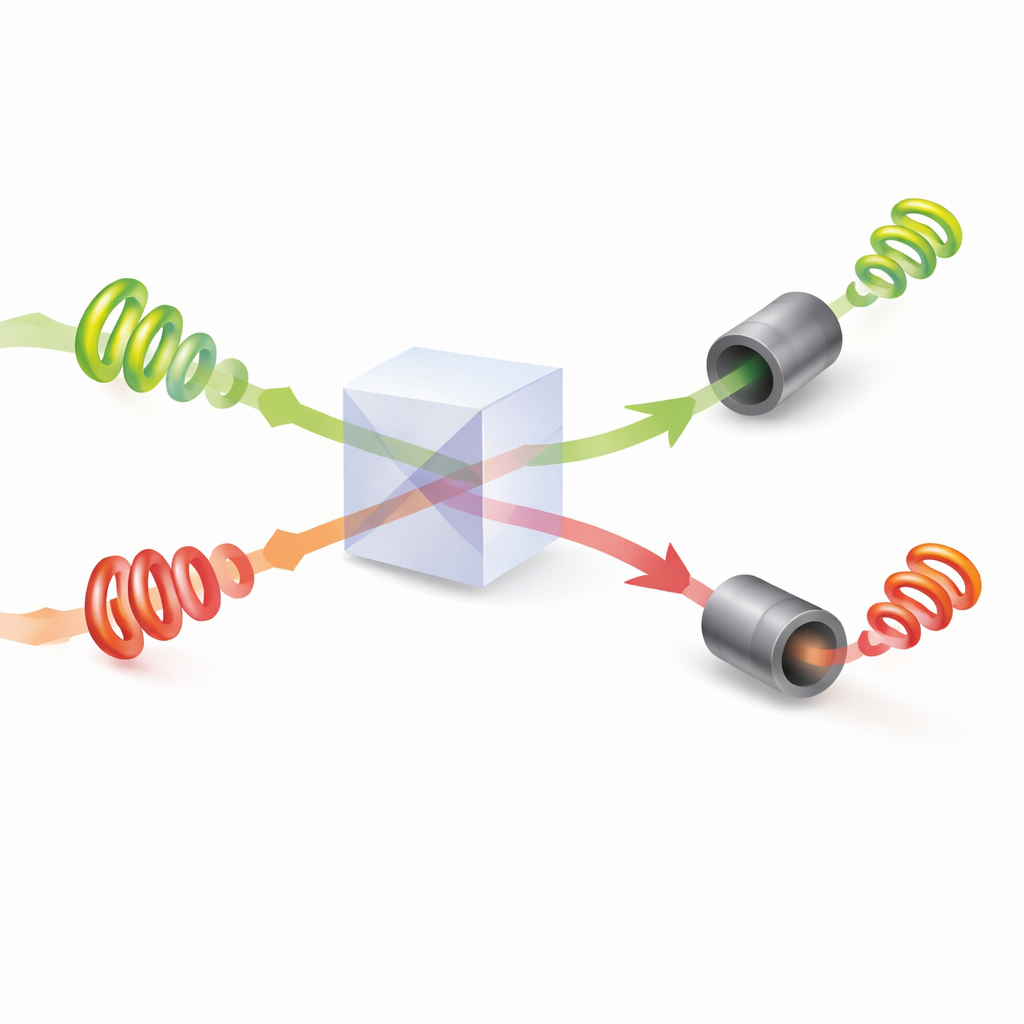
Quanteninterferenz zur Vermeidung von Kollisionen
Nachdem die Muster eingestellt sind, treffen die Photonenpaare an einem Strahlteiler aufeinander, wo Quanteninterferenz auftritt: Die kombinierten Lichtwellen können sich je nach relativer Verdrehung und Phase gegenseitig verstärken oder auslöschen. Die Forschenden zeigen, wie man die verborgenen Phasenwinkel des Lichts so anpasst, dass immer dann, wenn die beiden Photonen unterschiedliche Ausgangspfade verlassen, sie garantiert unterschiedliche Verdrehungswerte tragen. Jeder Spieler misst dann die absolute Höhe der Verdrehung seines Photons und interpretiert diesen Wert als eine bestimmte Option. Aufgrund der Interferenz erhalten sie nie dieselbe Anweisung, wenn beide Photonen erfolgreich detektiert werden. Effektiv erzwingt die Physik des Lichts selbst die Kollisionsfreiheit — etwas, das sich mit gewöhnlichem, klassischem Licht nicht nachbilden lässt.
Lernen bei Skalierung auf viele Optionen
Das optische System ist an eine einfache Lernregel gekoppelt, die jeden Spieler über viele Runden von breiter Exploration hin zu stärkerer Bevorzugung ertragsreicher Optionen führt. Entscheidender Vorteil gegenüber früheren optischen Konzepten, die Präferenzen durch Absenken der Lichtintensität kodierten — und dabei mit wachsender Optionszahl mehr Photonen verschwendeten — ist, dass dieses Design die Präferenzen direkt im Verdrehungsmuster jedes Photons einbettet. Die Autoren analysieren, wie häufig die Photonen auf getrennten Pfaden austreten, wie gut die resultierenden Entscheidungen den beabsichtigten Präferenzmustern der Spieler entsprechen und wie viel „Reue“ sich ansammelt, also entgangene Belohnung im Vergleich zur idealen Strategie. In umfangreichen Computersimulationen mit fünf und zehn Optionen erzielte ihre Methode durchweg höhere Erträge, passte sich schneller an und war weniger empfindlich gegenüber Einstellungsparametern als der vorherige Ansatz.
Folgen für reale Systeme
Über die mathematische Leistung hinaus deutet der Ansatz auf eine neue Hardware‑Philosophie hin, in der Licht einen Teil der Entscheidungsarbeit übernimmt. Da die Koordination physikalisch durch Interferenz und nicht durch digitale Nachrichten erfolgt, können zwei Geräte einander aus dem Weg gehen, ohne ihre internen Prioritäten offenzulegen. Die Autoren argumentieren, dass eine solche konfliktfreie, hochdurchsatzfähige und datenschutzfreundliche Entscheidungsmaschine eines Tages in optische Verbindungen von Rechenzentren oder in Funksysteme eingebaut werden könnte, die schnell freie Kanäle ergreifen müssen und wenig Funkverkehr erzeugen dürfen. Obwohl die aktuelle Arbeit in Simulationen für zwei Spieler demonstriert wird, zeigt sie, wie sich die Besonderheiten der Quantenoptik nutzen lassen, um komplexe Lern‑ und Koordinationsaufgaben auf Weisen anzugehen, die mit Standard‑Elektronik schwer zu erreichen sind.
Zitation: Konaka, K., Röhm, A., Mihana, T. et al. Scalable conflict-free bandit algorithm using a quantum optical setup. npj Quantum Inf 12, 44 (2026). https://doi.org/10.1038/s41534-026-01201-6
Schlüsselwörter: Quantenoptik, Verstärkungslernen, Multi‑Armed Bandit, Bahndrehimpuls, photonische Entscheidungsfindung