Clear Sky Science · it
Algoritmo bandito senza conflitti scalabile usando un apparato ottico quantistico
La luce che ci aiuta a condividere senza scontrarci
Molte tecnologie moderne, dalle reti Wi‑Fi alla pubblicità online, devono gestire più utenti che contemporaneamente desiderano l’opzione migliore. Quando due persone o dispositivi scelgono inconsapevolmente la stessa alternativa, si intralciano a vicenda e tutti ne risentono. Questo articolo mostra come un fascio di luce quantistica progettato con cura possa agire da arbitro imparziale, guidando silenziosamente due decisori indipendenti verso scelte vantaggiose ed evitando che selezionino la stessa opzione—senza alcuna comunicazione diretta tra di loro.
Scelte, ricompense e il problema dell’affollamento
Gli ingegneri spesso modellano decisioni ripetute con il quadro del “multi‑armed bandit”, ispirato alle file di slot machine. Ogni opzione fornisce una ricompensa con una certa probabilità nascosta, quindi un giocatore deve bilanciare l’esplorazione di alternative per apprenderne i profili e lo sfruttamento di quelle che sembrano migliori. La sfida diventa molto più difficile quando diversi giocatori affrontano le stesse opzioni e ciascuno punta alle alternative ad alto rendimento. Se scelgono la stessa opzione contemporaneamente, devono dividere la ricompensa. Questa situazione, chiamata problema competitivo dei multi‑armed bandit, rappresenta compiti reali come l’assegnazione di frequenze radio a dispositivi wireless o la distribuzione di server al traffico dati, dove troppi utenti su uno stesso canale danneggiano tutti.
Usare la luce attorcigliata come motore decisionale condiviso
Gli autori costruiscono una soluzione usando fotoni singoli—particelle di luce—i cui profili d’onda girano come minuscole viti, una proprietà nota come momento angolare orbitale. Poiché questi motivi di luce attorcigliata possono essere distinti e, in linea di principio, supportare molte “modalità” differenti, offrono un ampio ventaglio di etichette che possono rappresentare scelte diverse. Nella configurazione proposta, una sorgente genera una coppia di fotoni correlati che vengono instradati verso due giocatori separati tramite una disposizione di specchi e divisori di fascio. Ogni giocatore fa passare il proprio fotone attraverso un dispositivo programmabile che modella il suo profilo attorcigliato in modo che l’intensità di ciascuna modalità rifletta quanto quel giocatore preferisca attualmente ogni opzione, sulla base delle proprie vittorie e perdite passate.
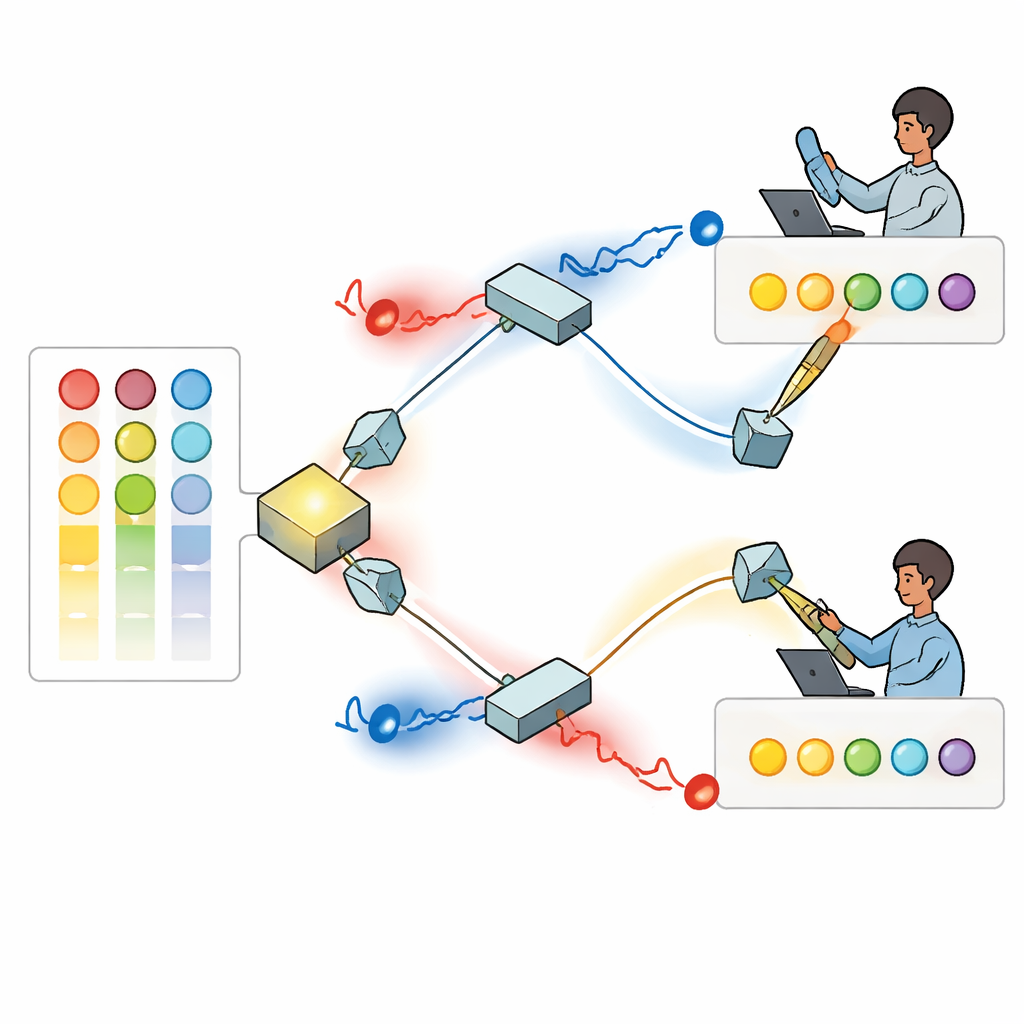
Interferenza quantistica per prevenire collisioni
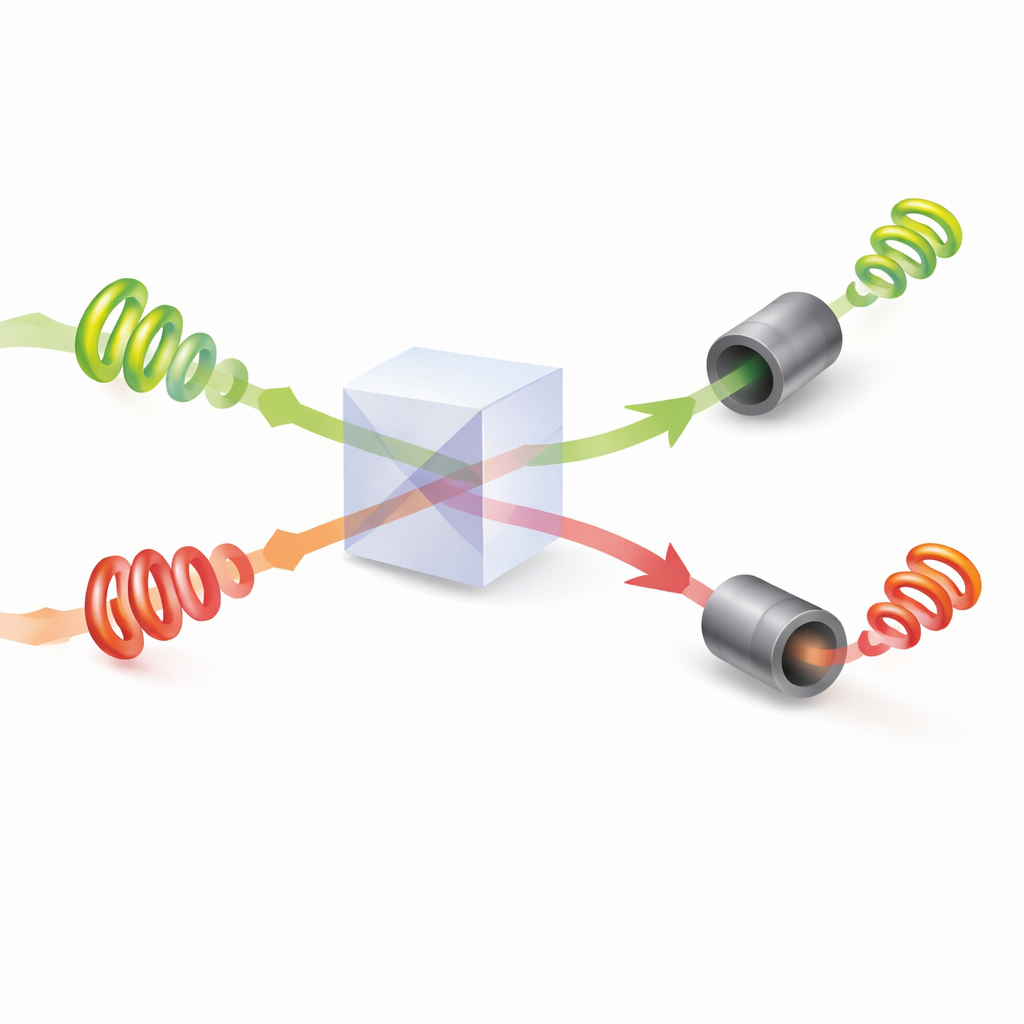
Dopo che i loro profili sono stati impostati, la coppia di fotoni si incontra a un divisore di fascio dove avviene l’interferenza quantistica: le onde luminose combinate possono rinforzarsi o cancellarsi a vicenda a seconda delle torsioni relative e delle fasi. I ricercatori mostrano come regolare gli angoli di fase nascosti della luce in modo che, ogni volta che i due fotoni emergono da percorsi di uscita diversi, sia garantito che portino valori di torsione differenti. Ogni giocatore misura quindi la quantità assoluta di torsione sul proprio fotone e interpreta quel valore come una specifica opzione da scegliere. Grazie all’interferenza, non ricevono mai la stessa istruzione quando entrambi i fotoni sono rilevati con successo. In pratica, la fisica stessa della luce impone una regola di “no‑collisione”, qualcosa di impossibile da riprodurre con luce ordinaria, classica.
Imparare scalando a molte opzioni
Il sistema ottico è accoppiato a una semplice regola di apprendimento che sposta gradualmente ogni giocatore da un’ampia esplorazione verso la preferenza per le opzioni più remunerative nel corso di molte ripetizioni. Crucialmente, a differenza di schemi ottici precedenti che si basavano sull’attenuazione della luce per codificare le preferenze—sprechiando sempre più fotoni all’aumentare del numero di opzioni—questo progetto incorpora le preferenze direttamente nel profilo attorcigliato di ciascun fotone. Gli autori analizzano quanto spesso i fotoni escono su percorsi separati, quanto le scelte risultanti corrispondono ai modelli di preferenza voluti dai giocatori e quanta “rimpianto” si accumula, cioè ricompensa persa rispetto a una strategia ideale. In grandi simulazioni al computer con cinque e dieci opzioni, il loro metodo ha ottenuto costantemente ricompense più alte, si è adattato più in fretta ed è stato meno sensibile all’assetto dei parametri rispetto all’approccio precedente.
Cosa significa per i sistemi reali
Oltre alle prestazioni matematiche, l’approccio suggerisce un nuovo stile di hardware in cui la luce svolge parte del lavoro decisionale. Poiché il coordinamento avviene fisicamente tramite interferenza piuttosto che con messaggi digitali, due dispositivi possono evitare di intralciarsi l’un l’altro senza rivelare le proprie priorità interne. Gli autori sostengono che un motore decisionale senza conflitti, ad alta produttività e rispettoso della privacy potrebbe un giorno essere integrato nei collegamenti ottici dei data center o nei sistemi radio che devono rapidamente occupare canali liberi con un minimo di scambio. Sebbene il lavoro attuale sia dimostrato in simulazione per due giocatori, mette in mostra come gli aspetti peculiari dell’ottica quantistica possano essere sfruttati per affrontare compiti complessi di apprendimento e coordinamento in modi che l’elettronica standard difficilmente eguaglierà.
Citazione: Konaka, K., Röhm, A., Mihana, T. et al. Scalable conflict-free bandit algorithm using a quantum optical setup. npj Quantum Inf 12, 44 (2026). https://doi.org/10.1038/s41534-026-01201-6
Parole chiave: ottica quantistica, apprendimento per rinforzo, multi-armed bandit, momento angolare orbitale, decisione fotonica