Clear Sky Science · fr
Algorithme de bandit évolutif sans conflit utilisant un dispositif optique quantique
La lumière nous aide à partager sans entrer en conflit
De nombreuses technologies modernes, des réseaux Wi‑Fi à la publicité en ligne, doivent gérer plusieurs utilisateurs qui souhaitent tous la meilleure option en même temps. Lorsque deux personnes ou appareils font le même choix sans le savoir, ils se gênent mutuellement et la performance globale s’en trouve dégradée. Cet article montre comment un faisceau de lumière quantique conçu avec soin peut jouer le rôle d’un arbitre impartial, orientant discrètement deux décideurs indépendants vers de bonnes options tout en les empêchant de choisir la même option — sans aucune communication directe entre eux.
Choix, récompenses et le problème de la congestion
Les ingénieurs modélisent souvent la prise de décision répétée avec le cadre du « multi‑armed bandit », inspiré des rangées de machines à sous. Chaque option donne une récompense avec une probabilité cachée, de sorte qu’un joueur doit équilibrer l’exploration d’options pour en apprendre davantage et l’exploitation de celles qui semblent les meilleures. Le défi devient beaucoup plus difficile lorsque plusieurs joueurs font face aux mêmes options et cherchent chacun les gains élevés. S’ils choisissent la même option en même temps, ils doivent partager la récompense. Cette situation, appelée problème compétitif du multi‑armed bandit, reflète des tâches du monde réel telles que l’attribution de fréquences radio à des appareils sans fil ou l’allocation de serveurs au trafic de données, où trop d’utilisateurs se concentrant sur le même canal nuisent à tout le monde.
Utiliser la lumière torsadée comme moteur de décision partagé
Les auteurs proposent une solution utilisant des photons uniques — particules de lumière — dont les motifs d’onde tourbillonnent comme de minuscules tire‑bouchons, une propriété connue sous le nom de moment angulaire orbital. Parce que ces motifs de lumière torsadée peuvent être distingués et, en principe, supporter de nombreux « modes » distincts, ils offrent un large éventail d’étiquettes pouvant représenter différentes options. Dans la configuration proposée, une source génère une paire de photons corrélés qui sont acheminés vers deux joueurs séparés via un agencement de miroirs et de séparateurs de faisceau. Chaque joueur fait passer son photon à travers un dispositif programmable qui façonne son motif torsadé de sorte que l’intensité de chaque mode reflète la préférence actuelle de ce joueur pour chaque option, en fonction de ses victoires et défaites passées.
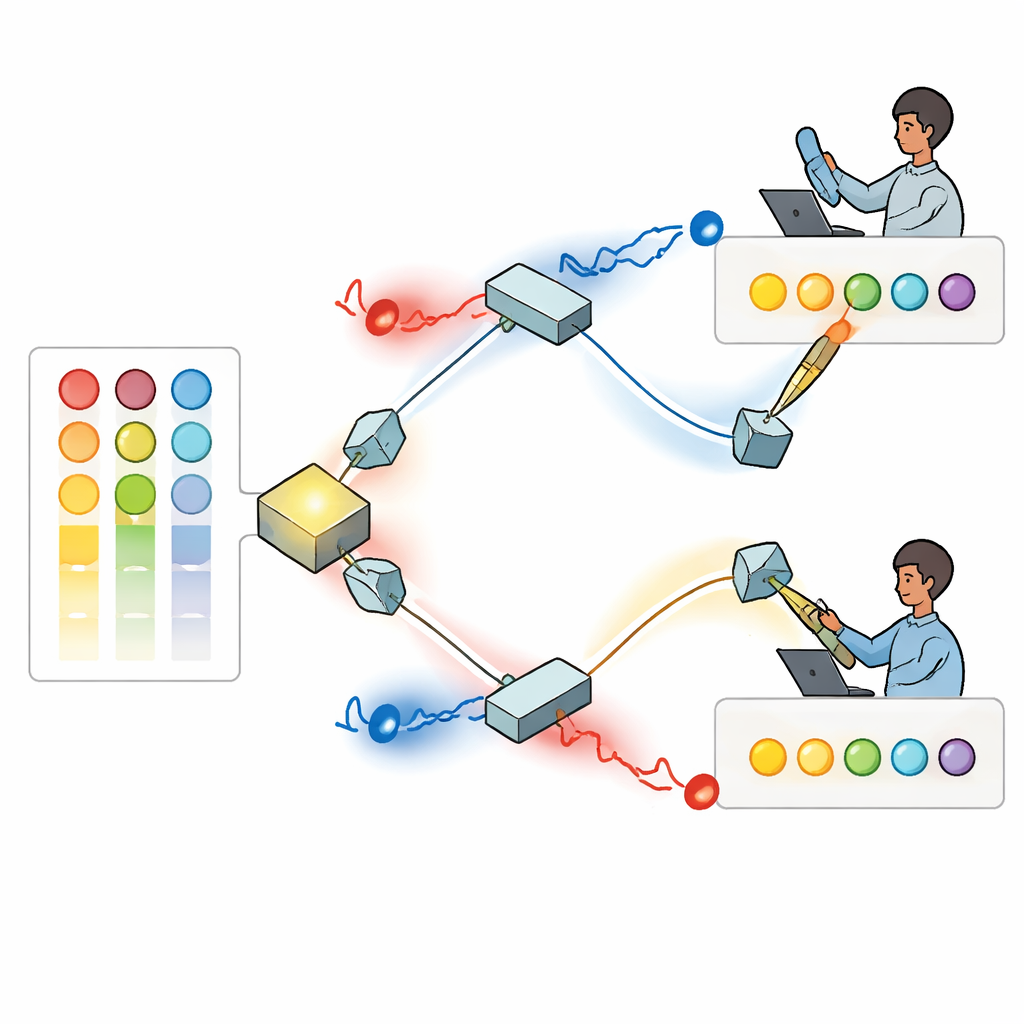
Interférence quantique pour prévenir les collisions
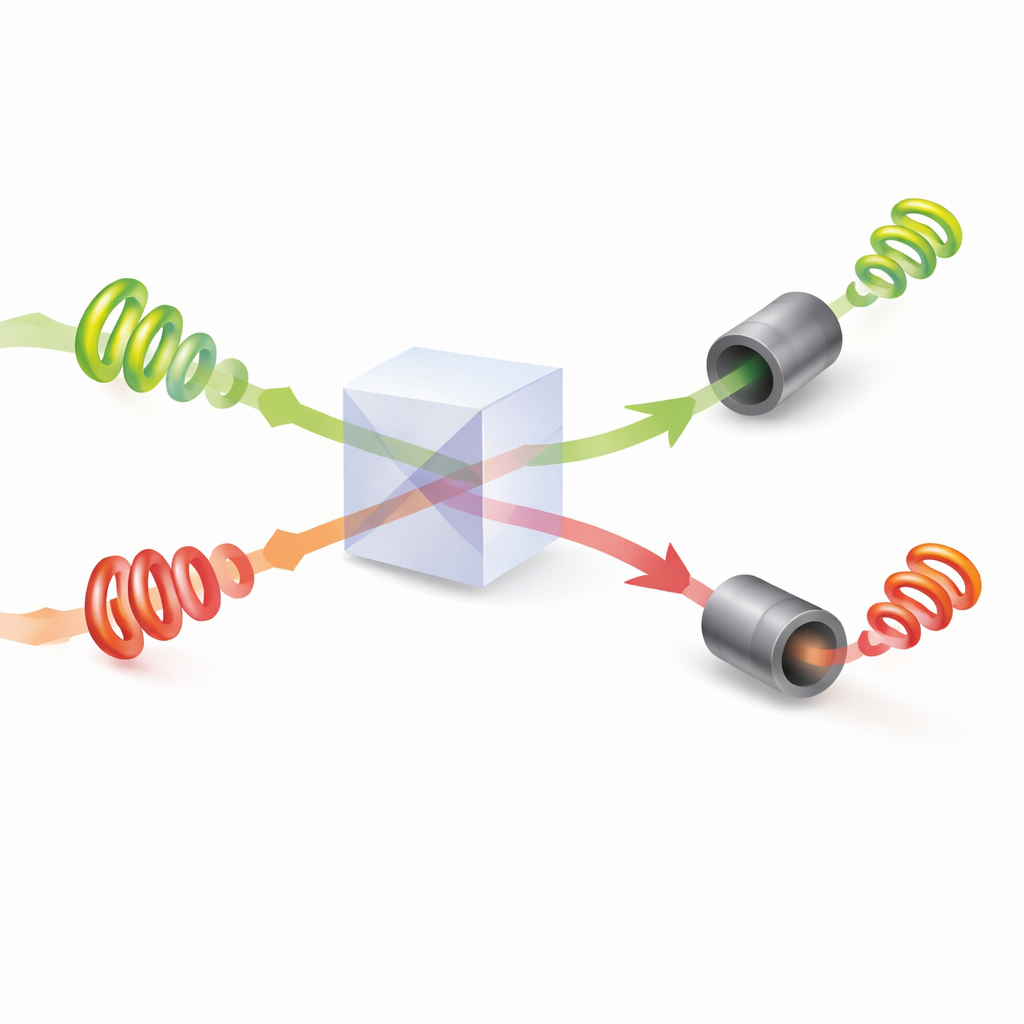
Une fois leurs motifs réglés, la paire de photons se rencontre dans un séparateur de faisceau où se produit une interférence quantique : les ondes lumineuses combinées peuvent se renforcer ou s’annuler selon leurs torsions et phases relatives. Les chercheurs montrent comment ajuster les angles de phase cachés de la lumière de sorte que, chaque fois que les deux photons émergent par des sorties différentes, ils portent nécessairement des valeurs de torsion distinctes. Chaque joueur mesure alors la quantité absolue de torsion de son photon et interprète cette valeur comme une option spécifique à choisir. En raison de l’interférence, ils ne reçoivent jamais la même instruction lorsque les deux photons sont détectés avec succès. En pratique, la physique de la lumière elle‑même impose une règle de non‑collision, chose impossible à reproduire avec la lumière ordinaire classique.
Apprendre tout en s’étendant à de nombreuses options
Le système optique est couplé à une règle d’apprentissage simple qui fait progressivement passer chaque joueur d’une large exploration vers une préférence pour les options les plus rémunératrices au fil des manches. De façon cruciale, contrairement aux schémas optiques antérieurs qui s’appuyaient sur l’atténuation de la lumière pour encoder les préférences — gaspillant de plus en plus de photons à mesure que le nombre d’options augmentait — ce dispositif intègre les préférences directement dans le motif de torsion de chaque photon. Les auteurs analysent la fréquence à laquelle les photons sortent par des chemins séparés, la corrélation entre les choix obtenus et les schémas de préférence souhaités par les joueurs, ainsi que le « regret » accumulé, c’est‑à‑dire la perte de récompense comparée à une stratégie idéale. Dans de vastes simulations informatiques avec cinq et dix options, leur méthode a systématiquement obtenu des récompenses plus élevées, s’est adaptée plus rapidement et s’est montrée moins sensible aux réglages que l’approche précédente.
Ce que cela signifie pour les systèmes du monde réel
Au‑delà de ses performances mathématiques, l’approche suggère un nouveau style de matériel où la lumière effectue une partie du raisonnement. Parce que la coordination se produit physiquement par interférence plutôt que par messages numériques, deux dispositifs peuvent éviter de se gêner sans révéler leurs priorités internes. Les auteurs soutiennent qu’un tel moteur de décision sans conflit, à haut débit et préservant la vie privée pourrait un jour être intégré aux liaisons optiques des centres de données ou aux systèmes radio qui doivent saisir rapidement des canaux inoccupés avec un minimum d’échanges. Bien que le travail actuel soit démontré en simulation pour deux joueurs, il illustre comment les particularités de l’optique quantique peuvent être exploitées pour traiter des tâches complexes d’apprentissage et de coordination d’une manière que l’électronique classique ne peut pas facilement égaler.
Citation: Konaka, K., Röhm, A., Mihana, T. et al. Scalable conflict-free bandit algorithm using a quantum optical setup. npj Quantum Inf 12, 44 (2026). https://doi.org/10.1038/s41534-026-01201-6
Mots-clés: optique quantique, apprentissage par renforcement, multi-armed bandit, moment angulaire orbital, prise de décision photonique