Clear Sky Science · pt
Algoritmo escalável de bandit sem conflitos usando um dispositivo óptico quântico
A luz nos ajudando a compartilhar sem conflitar
Muitas tecnologias modernas, desde redes Wi‑Fi até publicidade online, precisam conciliar vários usuários que desejam simultaneamente a melhor opção. Quando duas pessoas ou dispositivos escolhem sem saber a mesma alternativa, interferem um no outro e todos se saem pior. Este artigo mostra como um feixe cuidadosamente projetado de luz quântica pode atuar como um árbitro imparcial, orientando discretamente dois tomadores de decisão independentes em direção a boas escolhas enquanto evita que escolham a mesma opção — sem qualquer comunicação direta entre eles.
Escolhas, recompensas e o problema da superlotação
Engenheiros frequentemente modelam decisões repetidas com a estrutura do “multi‑armed bandit”, inspirada em fileiras de máquinas caça‑níqueis. Cada opção entrega uma recompensa com alguma probabilidade oculta, então um jogador precisa equilibrar experimentar opções para aprendê‑las e explorar as que parecem melhores. O desafio se torna muito mais difícil quando vários jogadores enfrentam as mesmas opções e cada um quer as de maior retorno. Se eles escolhem a mesma opção ao mesmo tempo, precisam dividir a recompensa. Essa situação, chamada de problema competitivo de multi‑armed bandit, descreve tarefas do mundo real como atribuir frequências de rádio a dispositivos sem fio ou alocar servidores ao tráfego de dados, onde muitos usuários concentrados no mesmo canal prejudicam todos.
Usando luz torcida como um motor de decisão compartilhado
Os autores constroem uma solução usando fótons únicos — partículas de luz — cujos padrões de onda giram como pequenos parafusos, uma propriedade conhecida como momento angular orbital. Como esses padrões de luz torcida podem ser distinguidos e, em princípio, suportar muitos “modos” distintos, eles fornecem um amplo menu de rótulos que podem representar diferentes escolhas. No dispositivo proposto, uma fonte gera um par de fótons entrelaçados que são direcionados a dois jogadores separados através de um arranjo de espelhos e divisores de feixe. Cada jogador passa seu fóton por um dispositivo programável que modela seu padrão torcido de modo que o brilho de cada modo reflita o quanto aquele jogador atualmente prefere cada opção, com base em suas vitórias e perdas anteriores.
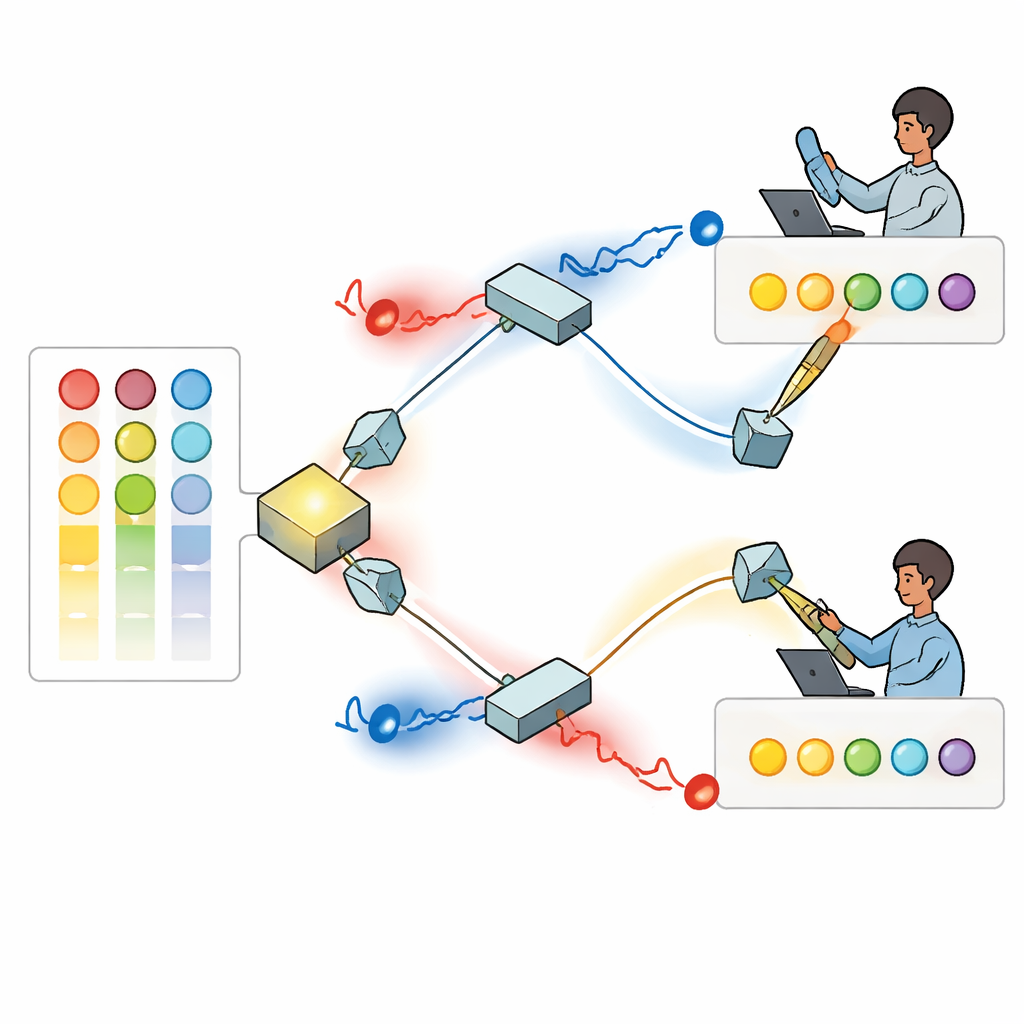
Interferência quântica para prevenir colisões
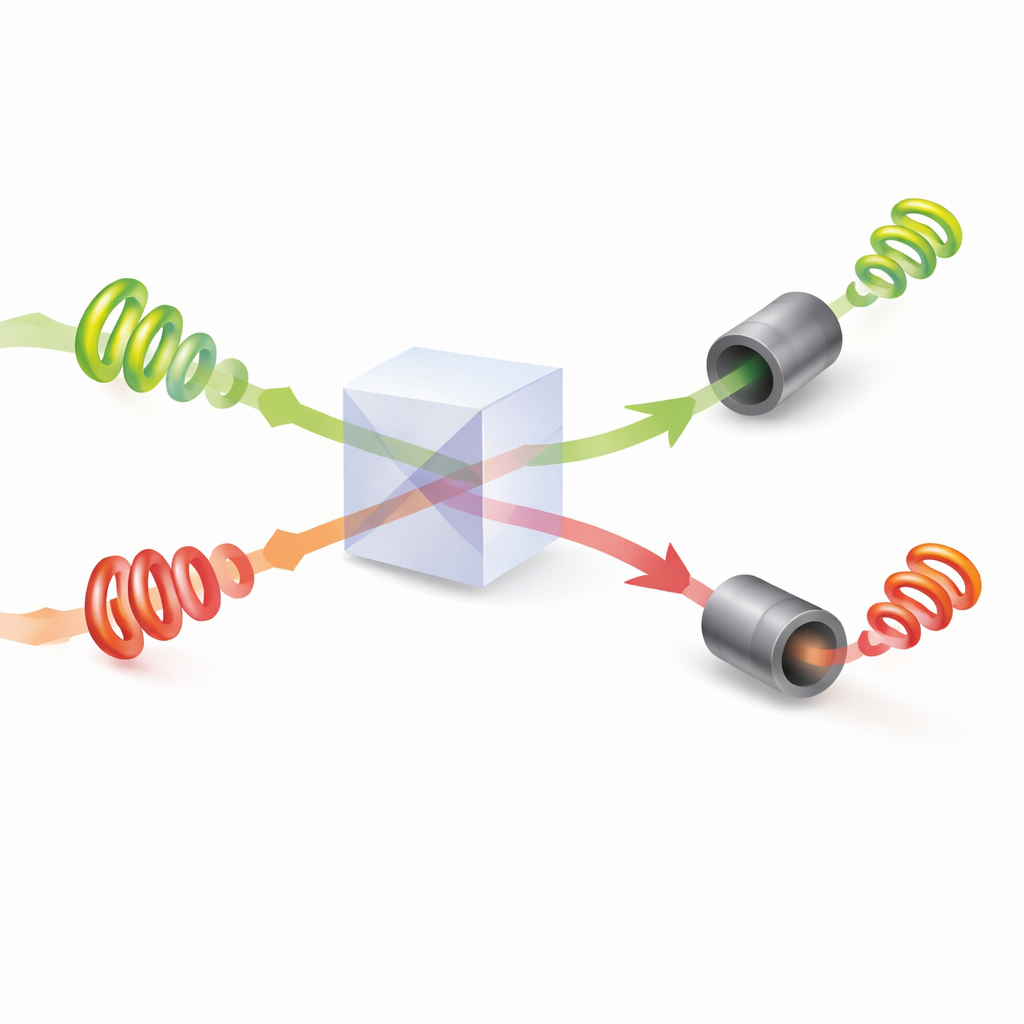
Depois que seus padrões são ajustados, o par de fótons se encontra em um divisor de feixe onde ocorre interferência quântica: as ondas de luz combinadas podem se reforçar ou se cancelar dependendo de suas torções relativas e fases. Os pesquisadores mostram como ajustar os ângulos de fase ocultos da luz de modo que, sempre que os dois fótons saem por caminhos de saída diferentes, eles tenham garantidamente valores de torção distintos. Cada jogador então mede a quantidade absoluta de torção em seu fóton e interpreta esse valor como uma opção específica a escolher. Devido à interferência, eles nunca recebem a mesma instrução quando ambos os fótons são detectados com sucesso. Em efeito, a própria física da luz impõe uma regra de não‑colisão, algo impossível de reproduzir com luz clássica comum.
Aprender enquanto escala para muitas opções
O sistema óptico é acoplado a uma regra simples de aprendizado que gradualmente desloca cada jogador de uma exploração ampla para favorecer opções de maior retorno ao longo de muitas rodadas. Crucialmente, ao contrário de esquemas ópticos anteriores que dependiam de apagar a luz para codificar preferências — desperdiçando cada vez mais fótons conforme o número de opções crescia — este projeto incorpora as preferências diretamente no padrão de torção de cada fóton. Os autores analisam com que frequência os fótons saem por caminhos separados, quão bem as escolhas resultantes correspondem aos padrões de preferência pretendidos pelos jogadores e quanta “arrependimento” se acumula, ou seja, recompensa perdida em comparação com uma estratégia ideal. Em grandes simulações de computador com cinco e dez opções, seu método consistentemente alcançou recompensas maiores, adaptou‑se mais rapidamente e foi menos sensível a ajustes do que a abordagem anterior.
O que isso significa para sistemas do mundo real
Além do desempenho matemático, a abordagem sugere um novo estilo de hardware em que a luz realiza parte do processamento. Como a coordenação acontece fisicamente por meio da interferência em vez de mensagens digitais, dois dispositivos podem evitar pisar nos mesmos recursos sem revelar suas prioridades internas. Os autores argumentam que esse mecanismo de decisão sem conflitos, de alto rendimento e preservador de privacidade poderia um dia ser integrado a enlaces ópticos em centros de dados ou a sistemas de rádio que precisam rapidamente ocupar canais ociosos com o mínimo de comunicação. Embora o trabalho atual seja demonstrado em simulação para dois jogadores, ele mostra como as particularidades da óptica quântica podem ser aproveitadas para enfrentar tarefas complexas de aprendizado e coordenação de formas que a eletrônica convencional não iguala facilmente.
Citação: Konaka, K., Röhm, A., Mihana, T. et al. Scalable conflict-free bandit algorithm using a quantum optical setup. npj Quantum Inf 12, 44 (2026). https://doi.org/10.1038/s41534-026-01201-6
Palavras-chave: óptica quântica, aprendizado por reforço, multi-armed bandit, momento angular orbital, tomada de decisão fotônica