Clear Sky Science · pt
Um método de segmentação semântica de imagens de sensoriamento remoto em alta resolução com poucos exemplos
Por que fotos aéreas mais inteligentes importam
Do monitoramento de inundações ao mapeamento de novos bairros, muitas decisões modernas dependem de imagens detalhadas feitas por pequenos drones. Transformar essas imagens em mapas claros de estradas, campos, edificações e corpos d’água normalmente exige milhares de rótulos desenhados à mão por especialistas. Este estudo mostra como computadores podem aprender a gerar mapas precisos a partir de imagens de drones usando muito menos exemplos rotulados por humanos, o que pode reduzir custos e acelerar trabalhos ambientais e urbanos essenciais. 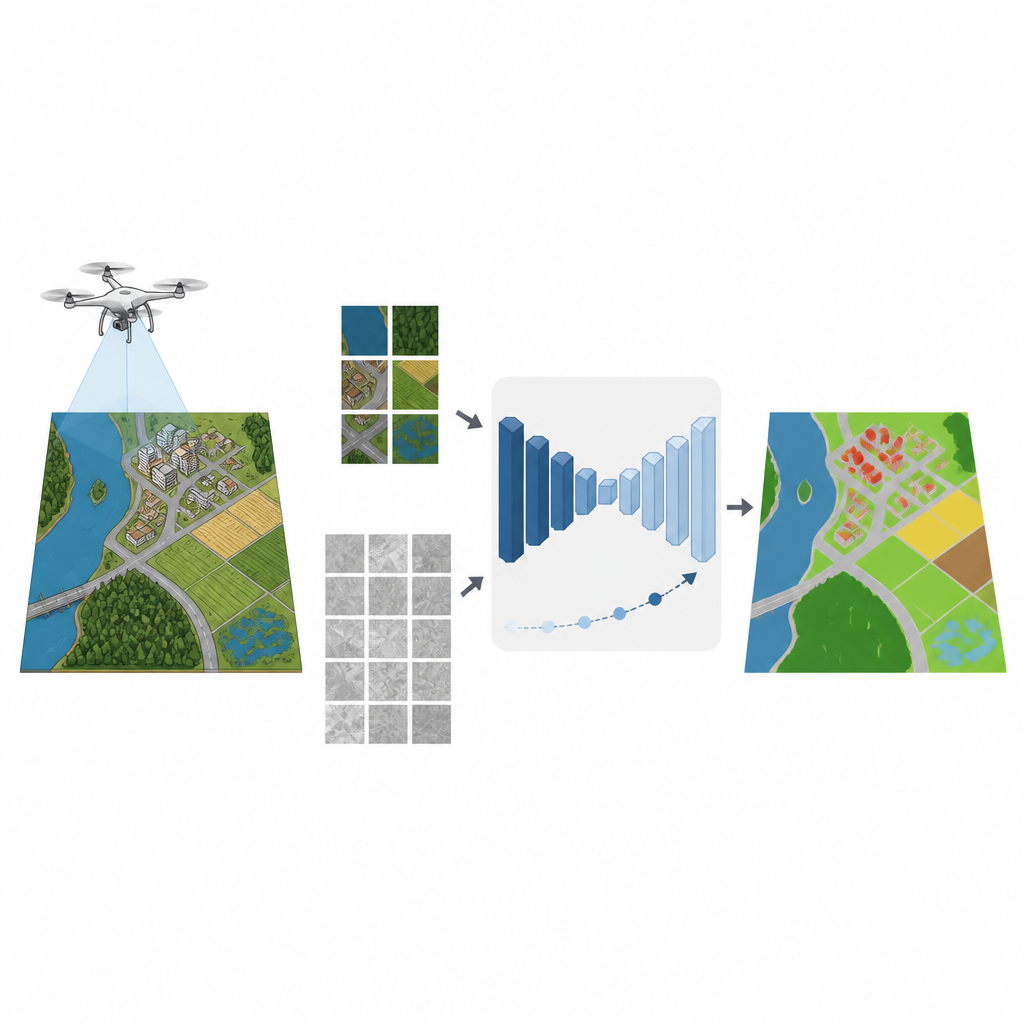
Ensinando computadores a ler a paisagem
As imagens de drones são incrivelmente nítidas, revelando telhados, copas de árvores, caminhos estreitos e linhas de costa. Embora esse nível de detalhe seja valioso, ele também torna o mapeamento automático mais difícil. Métodos clássicos dependiam de regras manuais sobre textura e cor, que têm dificuldade em cenas tão complexas. O aprendizado profundo elevou muito a precisão ao permitir que redes neurais aprendam padrões diretamente dos dados. Mas esse poder tem um preço: para funcionar bem, essas redes normalmente exigem grandes conjuntos de dados rotulados, e traçar contornos pixel a pixel para cada objeto em cada imagem é lento e caro.
Reaproveitando conhecimento de outras imagens
Um atalho comum é partir de modelos treinados em grandes coleções de fotos como o ImageNet e então ajustá-los para imagens de drones. Outro é a destilação de conhecimento, onde um modelo “professor” forte orienta um modelo “aluno” menor compartilhando seus padrões de saída. No entanto, fotos cotidianas diferem muito de imagens aéreas, tanto em ponto de vista quanto em conteúdo. Quando há apenas um pequeno número de imagens de drone rotuladas, um professor que viu apenas fotos naturais pode não fornecer a orientação mais útil, e o aluno pode não atingir seu potencial.
Construindo uma ponte de aprendizado e usando dados não rotulados
Os autores propõem uma estrutura que enfrenta os dois problemas ao mesmo tempo: a falta de rótulos e a discrepância entre fotos naturais e imagens de drones. Primeiro, eles aprimoram uma rede de mapeamento popular, o DeepLabV3+, substituindo o backbone por um projetado para preservar detalhes finos e adicionando um módulo de atenção que realça características importantes. Em seguida, introduzem uma etapa intermediária entre imagens naturais e o conjunto final de drones. O modelo é primeiro ajustado em um conjunto remoto de sensoriamento de porte médio, depois seu conhecimento é transferido em etapas para novos modelos alunos que se adaptam gradualmente à coleção final de drones. Ao longo desse processo, perdas especiais ajudam o aluno a copiar o comportamento do professor sem esquecer lições úteis anteriores. 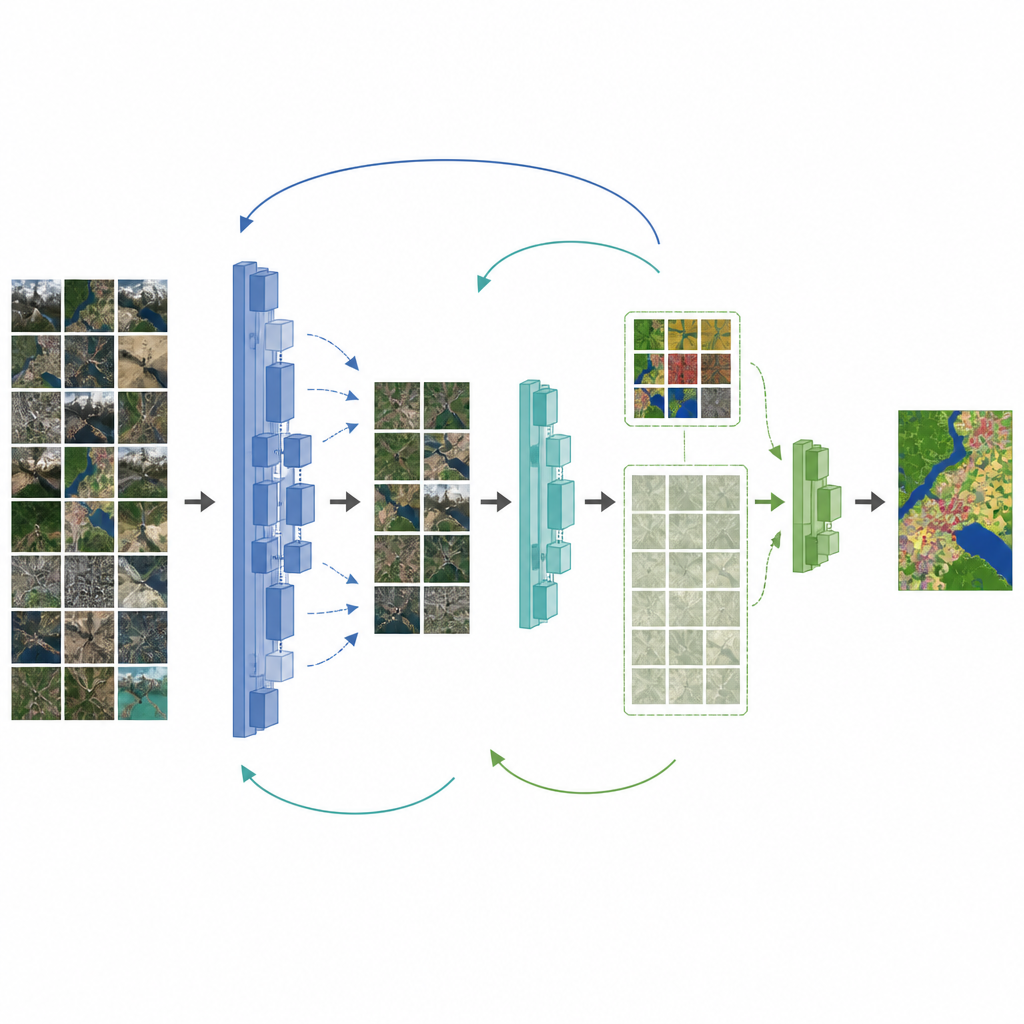
Deixando o modelo aprender com o que não está rotulado
Para aproveitar melhor as muitas imagens de drone não rotuladas, a estrutura acrescenta uma fase semi-supervisionada. Aqui, um modelo professor atualizado rotula por conta própria imagens não rotuladas e mantém apenas as previsões em que tem maior confiança. Essas “pseudo-etiquetas”, combinadas com o pequeno conjunto de rótulos humanos, são usadas para treinar um modelo aluno que deve manter consistência com o professor tanto em dados reais quanto em dados com pseudo-etiquetas. Os pesos do professor são atualizados lentamente a partir do progresso do aluno, criando um ciclo em que ambos melhoram juntos. Testes em um conjunto detalhado de drones sobre a região de Erhai, na China, mostram que essa estratégia aumenta significativamente a precisão do mapeamento, especialmente para estradas e áreas agrícolas, mesmo quando apenas uma fração das imagens está rotulada.
Quão bem o método funciona em diferentes lugares
Além do conjunto Erhai, os pesquisadores aplicam seu método a um benchmark amplamente usado de cenas de rua. Inserindo um conjunto intermediário apropriado cujas cenas se assemelham a ruas da cidade, eles novamente observam desempenho superior a outros métodos líderes, particularmente quando imagens rotuladas são escassas. Experimentos também revelam que escolher o conjunto intermediário certo é crucial: quando as cenas dessa etapa do meio são muito diferentes do alvo final, o desempenho pode cair em vez de subir. De modo geral, a combinação de ensino em etapas, arquitetura que preserva detalhes e uso inteligente de dados não rotulados oferece uma receita flexível que se adapta a diferentes tarefas de mapeamento.
O que isso significa para o mapeamento do mundo real
Para não especialistas, a mensagem principal é que mapas de alta qualidade a partir de imagens de drones não exigem mais quantidades massivas de traçados humanos. Reutilizando cuidadosamente conhecimento de grandes coleções de imagens, adicionando um conjunto ponte bem escolhido e deixando o modelo aprender sozinho a partir de imagens não rotuladas, o método proposto gera mapas de cobertura do solo mais precisos com muito menos trabalho manual. Isso pode facilitar que planejadores locais, agricultores e equipes de resposta a desastres mantenham visões detalhadas e atualizadas do território, controlando tempo e custos.
Citação: Jiang, HL., Wang, N., Geng, B. et al. A few-shot high-resolution remote sensing image semantic segmentation method. Sci Rep 16, 15262 (2026). https://doi.org/10.1038/s41598-026-46887-y
Palavras-chave: sensoriamento remoto, imagens de VANT, segmentação semântica, aprendizado semi-supervisionado, destilação de conhecimento