Clear Sky Science · de
Ein Few‑Shot‑Verfahren für semantische Segmentierung hochaufgelöster Fernerkundungsbilder
Warum klügere Luftaufnahmen wichtig sind
Von der Überwachung von Überschwemmungen bis zur Kartierung neuer Vororte: Viele moderne Entscheidungen beruhen auf hochdetaillierten Bildern, die kleine Drohnen aufnehmen. Aus diesen Bildern eindeutige Karten von Straßen, Feldern, Gebäuden und Gewässern zu erzeugen, erfordert normalerweise Tausende expertengezeichneter Labels. Die vorliegende Studie zeigt, wie Computer lernen können, aus Drohnenbildern mit deutlich weniger menschlich annotierten Beispielen genaue Karten zu erstellen — das könnte Kosten senken und wichtige Umwelt‑ und Stadtaufgaben beschleunigen. 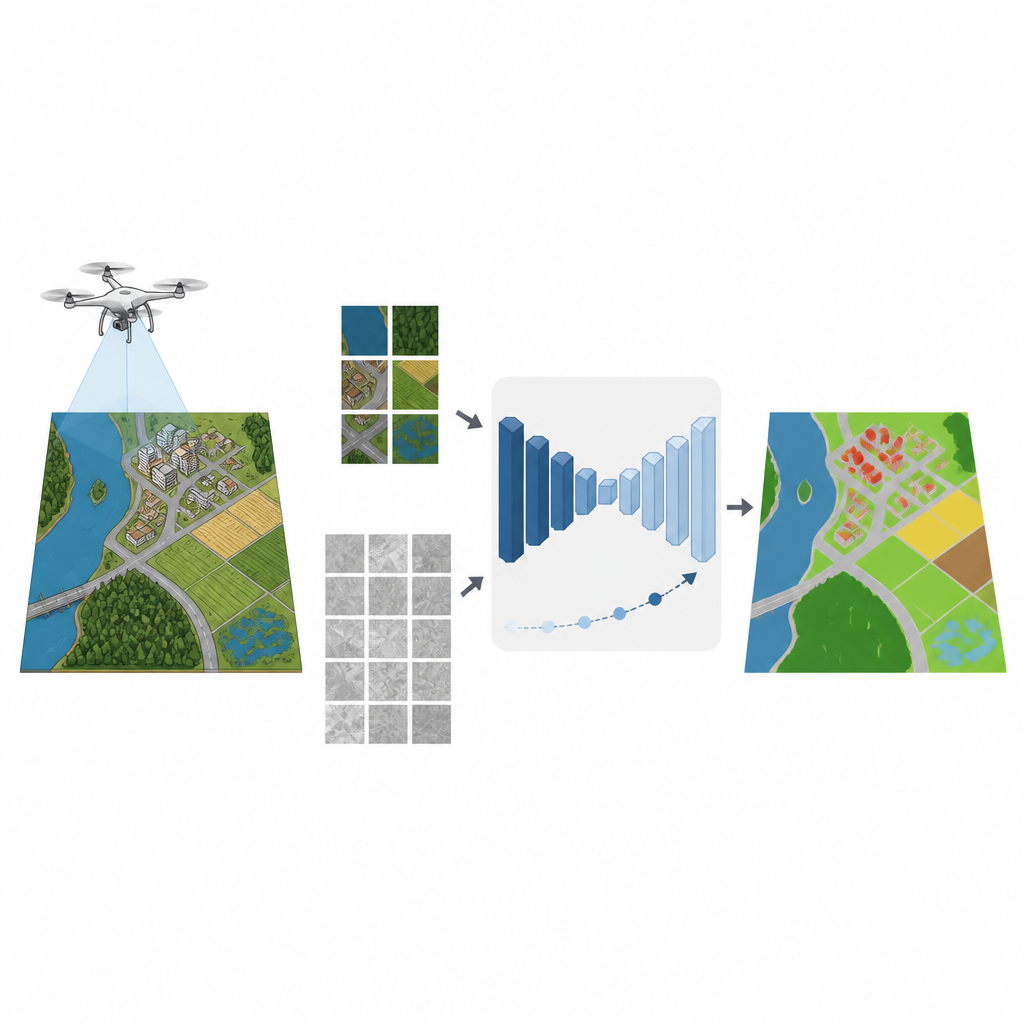
Computern das Lesen der Landschaft beibringen
Drohnenbilder sind außerordentlich scharf und zeigen Dachflächen, Baumkronen, schmale Pfade und Uferkanten. Obwohl diese Details wertvoll sind, erschweren sie auch die automatische Kartierung. Klassische Methoden setzten auf handgefertigte Regeln zu Textur und Farbe, die in solch komplexen Szenen an ihre Grenzen stoßen. Deep Learning hat die Genauigkeit deutlich verbessert, indem Netzwerke Muster direkt aus Daten lernen. Dieser Vorteil hat jedoch seinen Preis: Damit diese Netze gut funktionieren, benötigen sie in der Regel sehr große, gelabelte Datensätze, und pixelgenaues Nachzeichnen jedes Objekts in jedem Bild ist zeitaufwendig und teuer.
Wissen aus anderen Bildern wiederverwenden
Eine verbreitete Abkürzung ist, Modelle zu verwenden, die auf riesigen Fotosammlungen wie ImageNet vortrainiert wurden, und sie anschließend auf Drohnenbilder zu fine‑tunen. Eine andere ist Knowledge Distillation, bei der ein starkes „Lehrer“-Modell ein kleineres „Schüler“-Modell durch Weitergabe seiner Ausgabe‑Muster anleitet. Alltagsszenen unterscheiden sich jedoch stark von Luftaufnahmen — sowohl in Blickwinkel als auch im Inhalt. Wenn nur wenige gelabelte Drohnenbilder verfügbar sind, kann ein Lehrer, der nur natürliche Fotos gesehen hat, weniger nützliche Hinweise liefern, sodass der Schüler sein Potenzial nicht ausschöpft.
Eine Lernbrücke bauen und unlabeled Daten nutzen
Die Autoren schlagen ein Framework vor, das beide Probleme gleichzeitig angeht: den Mangel an Labels und die Diskrepanz zwischen Alltagsfotos und Drohnenbildern. Zunächst rüsten sie ein verbreitetes Kartierungsnetzwerk, DeepLabV3+, auf, indem sie ein Backbone einsetzen, das feine Details bewahrt, und ein Aufmerksamkeitsmodul hinzufügen, das wichtige Merkmale hervorhebt. Dann führen sie einen Zwischenschritt zwischen natürlichen Bildern und dem finalen Drohnen‑Datensatz ein. Das Modell wird zunächst auf einem mittelgroßen Fernerkundungsdatensatz feingetunt, danach wird sein Wissen gestuft an neue Schüler‑Modelle weitergegeben, die sich schrittweise an die endgültige Drohnenkollektion anpassen. Während dieses Prozesses helfen spezielle Verlustfunktionen dem Schüler, das Verhalten des Lehrers zu übernehmen, ohne nützliche frühere Erkenntnisse zu vergessen. 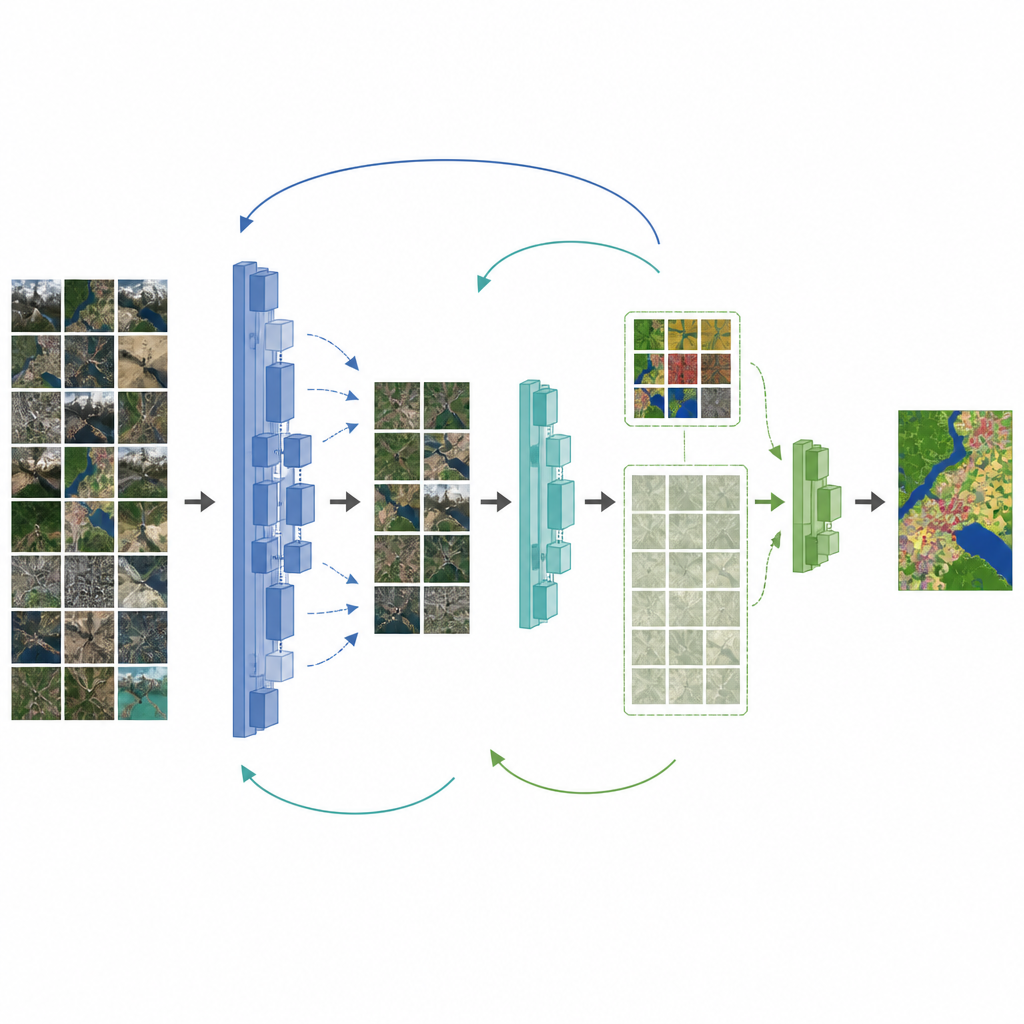
Das Modell aus unlabeled Daten lernen lassen
Um die Vielzahl unlabeled Drohnenbilder besser zu nutzen, ergänzt das Framework eine halbüberwachte Phase. Hier annotiert ein aktuelles Lehrer‑Modell unlabeled Bilder selbst und behält nur die Vorhersagen, bei denen es sich am sichersten ist. Diese „Pseudo‑Labels“ werden zusammen mit dem kleinen Satz menschlicher Labels verwendet, um ein Schüler‑Modell zu trainieren, das sowohl bei echten als auch bei pseudo‑gelabelten Daten konsistent mit dem Lehrer bleiben muss. Die Gewichte des Lehrers werden langsam aus den Fortschritten des Schülers aktualisiert, wodurch eine Schleife entsteht, in der sich beide Modelle gemeinsam verbessern. Tests auf einem detaillierten Drohnendatensatz über der Erhai‑Region in China zeigen, dass diese Strategie die Kartierungsgenauigkeit deutlich erhöht, insbesondere für Straßen und Agrarflächen — selbst wenn nur ein Bruchteil der Bilder beschriftet ist.
Wie gut der Ansatz an verschiedenen Orten funktioniert
Über den Erhai‑Datensatz hinaus wenden die Forscher ihre Methode auf ein häufig genutztes Straßen‑Szenen‑Benchmark an. Durch Einschieben eines passenden Zwischendatensatzes, dessen Szenen Stadtstraßen ähneln, erzielen sie erneut bessere Leistungen als andere führende Methoden — insbesondere wenn gelabelte Bilder knapp sind. Experimente zeigen auch, dass die Wahl des richtigen Zwischendatensatzes entscheidend ist: Stimmen die Szenen dieses Mittelschritts zu wenig mit dem Ziel überein, kann die Leistung sinken statt zu steigen. Insgesamt liefert die Kombination aus gestuftem Lehren, detailerhaltender Architektur und sinnvoller Nutzung unlabeled Daten ein flexibles Rezept, das sich an unterschiedliche Kartierungsaufgaben anpassen lässt.
Was das für die praktische Kartierung bedeutet
Für Nicht‑Spezialisten lautet die Kernbotschaft: Hochwertige Karten aus Drohnenaufnahmen benötigen nicht mehr zwangsläufig riesige Mengen manueller Nachzeichnungen. Durch gezielte Wiederverwendung von Wissen aus großen Bildsammlungen, das Einfügen eines sorgfältig gewählten Brückendatensatzes und das Selbstlehren an unlabeled Bildern liefert die vorgeschlagene Methode genauere Landbedeckungskarten bei deutlich geringerem manuellen Aufwand. Dadurch fällt es lokalen Planern, Landwirten und Katastrophenschutzteams leichter, stets aktuelle, detaillierte Ansichten der Landschaft zu erhalten und gleichzeitig Zeit und Kosten zu reduzieren.
Zitation: Jiang, HL., Wang, N., Geng, B. et al. A few-shot high-resolution remote sensing image semantic segmentation method. Sci Rep 16, 15262 (2026). https://doi.org/10.1038/s41598-026-46887-y
Schlüsselwörter: Fernerkundung, UAV‑Bilddaten, semantische Segmentierung, halbüberwachtes Lernen, Knowledge Distillation