Clear Sky Science · fr
Méthode de segmentation sémantique d’images de télédétection haute résolution à partir de quelques exemples
Pourquoi de meilleures photos du ciel comptent
Qu’il s’agisse de surveiller des inondations ou de cartographier de nouveaux lotissements, de nombreuses décisions modernes reposent sur des images détaillées prises par de petits drones. Transformer ces images en cartes claires des routes, champs, bâtiments et zones d’eau exige généralement des milliers d’étiquettes dessinées à la main par des experts. Cette étude montre comment les ordinateurs peuvent apprendre à produire des cartes précises à partir d’images de drones en utilisant beaucoup moins d’exemples étiquetés par des humains, ce qui pourrait réduire les coûts et accélérer des travaux environnementaux et urbains essentiels. 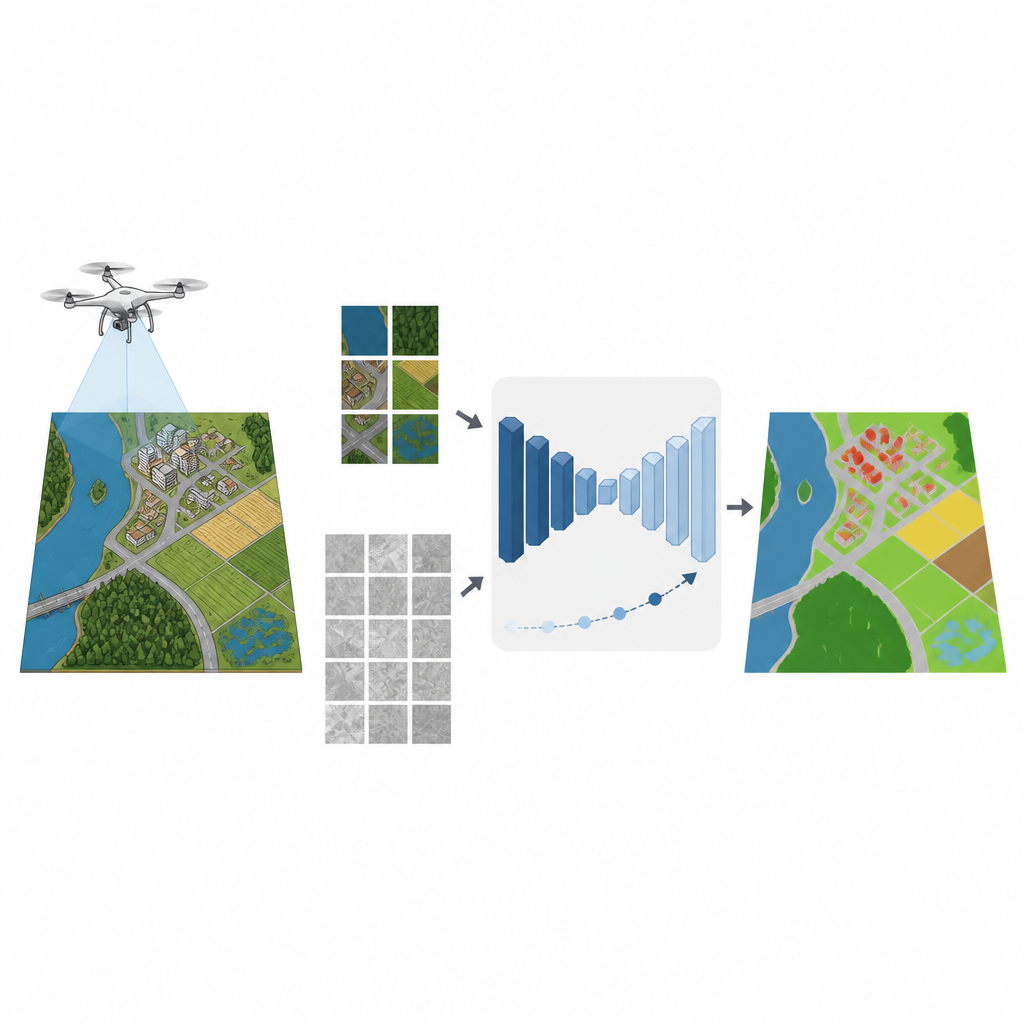
Apprendre aux ordinateurs à lire le paysage
Les images de drones sont d’une grande netteté, révélant toitures, canopées, sentiers étroits et contours de rivage. Si ce niveau de détail est précieux, il complique aussi la cartographie automatique. Les méthodes classiques reposaient sur des règles manuelles concernant la texture et la couleur, qui peinent dans des scènes aussi complexes. L’apprentissage profond a considérablement amélioré la précision en permettant aux réseaux neuronaux d’apprendre les motifs directement depuis les données. Mais cette puissance a un coût : pour bien fonctionner, ces réseaux exigent en général d’énormes jeux de données étiquetés, et tracer des contours pixel par pixel pour chaque objet de chaque image est long et coûteux.
Réutiliser des connaissances d’autres images
Un raccourci courant consiste à partir de modèles entraînés sur de vastes collections de photos comme ImageNet, puis à les adapter aux images de drone. Une autre approche est la distillation des connaissances, où un fort modèle « enseignant » guide un modèle « étudiant » plus petit en lui transmettant ses schémas de sortie. Cependant, les photos du quotidien diffèrent beaucoup des images aériennes, tant par le point de vue que par le contenu. Lorsqu’on ne dispose que d’un petit nombre d’images de drone étiquetées, un enseignant qui n’a vu que des photos naturelles peut ne pas fournir l’aide la plus pertinente, et l’étudiant peut échouer à atteindre son potentiel.
Construire un pont d’apprentissage et utiliser des données non étiquetées
Les auteurs proposent un cadre qui traite simultanément les deux problèmes : le manque d’étiquettes et le décalage entre photos naturelles et images de drone. D’abord, ils améliorent un réseau de cartographie populaire, DeepLabV3+, en remplaçant la colonne vertébrale par une architecture conçue pour préserver les détails fins et en ajoutant un module d’attention qui met en valeur les caractéristiques importantes. Ensuite, ils introduisent une étape intermédiaire entre les images naturelles et le jeu final de drones. Le modèle est d’abord ajusté sur un jeu de données de télédétection de taille moyenne, puis ses connaissances sont transmises par étapes à de nouveaux modèles étudiants qui s’adaptent progressivement à la collection finale de drones. Tout au long de ce processus, des fonctions de perte spéciales aident l’étudiant à copier le comportement de l’enseignant sans oublier les leçons utiles apprises précédemment. 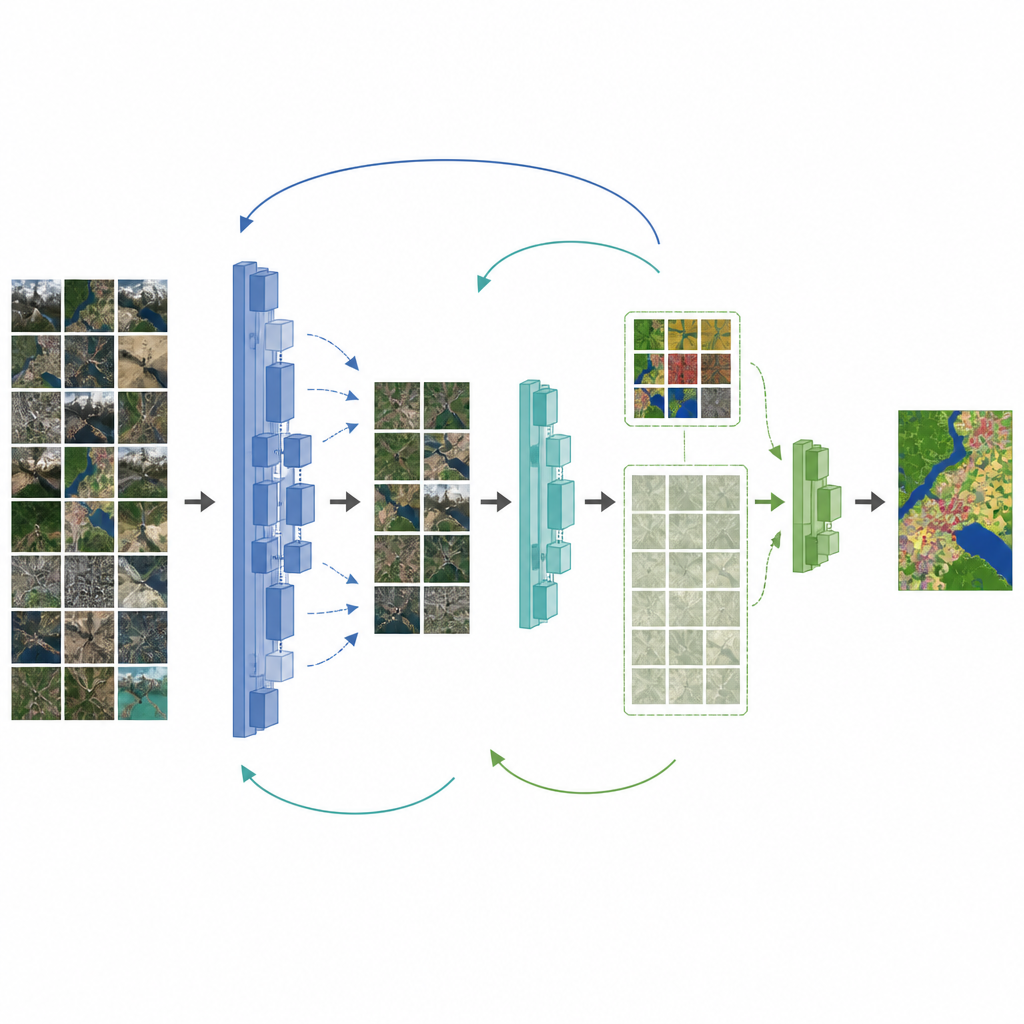
Permettre au modèle d’apprendre à partir de ce qui n’est pas étiqueté
Pour mieux exploiter les nombreuses images de drone non étiquetées, le cadre ajoute une étape semi-supervisée. Ici, un enseignant à jour étiquette lui-même les images non étiquetées et ne conserve que les prédictions dont il est le plus confiant. Ces « pseudo-étiquettes », combinées au petit ensemble d’étiquettes humaines, sont utilisées pour entraîner un modèle étudiant qui doit rester cohérent avec l’enseignant sur les données réelles et pseudo-étiquetées. Les poids de l’enseignant sont mis à jour lentement à partir des progrès de l’étudiant, créant une boucle où les deux s’améliorent ensemble. Des tests sur un jeu de données de drone détaillé dans la région d’Erhai en Chine montrent que cette stratégie augmente significativement la précision de cartographie, notamment pour les routes et les terres agricoles, même lorsque seule une fraction des images est étiquetée.
Quelle est l’efficacité de l’approche selon les lieux
Au-delà du jeu de données Erhai, les chercheurs appliquent leur méthode à une référence largement utilisée pour les scènes de rue. En insérant un jeu de données intermédiaire adapté dont les scènes ressemblent aux rues urbaines, ils constatent de nouveau de meilleures performances que d’autres méthodes de pointe, en particulier lorsque les images étiquetées sont rares. Les expériences montrent aussi que le choix du jeu intermédiaire est crucial : lorsque les scènes de cette étape intermédiaire sont trop différentes de la cible finale, les performances peuvent baisser au lieu d’augmenter. Globalement, la combinaison d’un enseignement par étapes, d’une architecture préservant les détails et d’une utilisation intelligente des données non étiquetées fournit une recette flexible qui s’adapte à différentes tâches de cartographie.
Ce que cela signifie pour la cartographie opérationnelle
Pour les non-spécialistes, le message principal est que des cartes de haute qualité à partir d’images de drones ne nécessitent plus des quantités massives de tracés manuels. En réutilisant soigneusement les connaissances issues de grandes collections d’images, en ajoutant un jeu de données pont bien choisi et en laissant le modèle s’auto-former à partir d’images non étiquetées, la méthode proposée produit des cartes d’occupation du sol plus précises avec beaucoup moins de travail manuel. Cela pourrait faciliter pour les urbanistes locaux, les agriculteurs et les équipes de gestion des catastrophes la mise à jour d’une vision détaillée du territoire tout en maîtrisant le temps et les coûts.
Citation: Jiang, HL., Wang, N., Geng, B. et al. A few-shot high-resolution remote sensing image semantic segmentation method. Sci Rep 16, 15262 (2026). https://doi.org/10.1038/s41598-026-46887-y
Mots-clés: télédétection, imagerie UAV, segmentation sémantique, apprentissage semi-supervisé, distillation des connaissances