Clear Sky Science · en
A few-shot high-resolution remote sensing image semantic segmentation method
Why smarter sky photos matter
From tracking floods to mapping new suburbs, many modern decisions rely on detailed pictures taken from small drones. Turning those pictures into clear maps of roads, fields, buildings, and water usually demands thousands of hand-drawn labels from experts. This study shows how computers can learn to make accurate maps from drone images while using far fewer human-labeled examples, which could lower costs and speed up vital environmental and urban work. 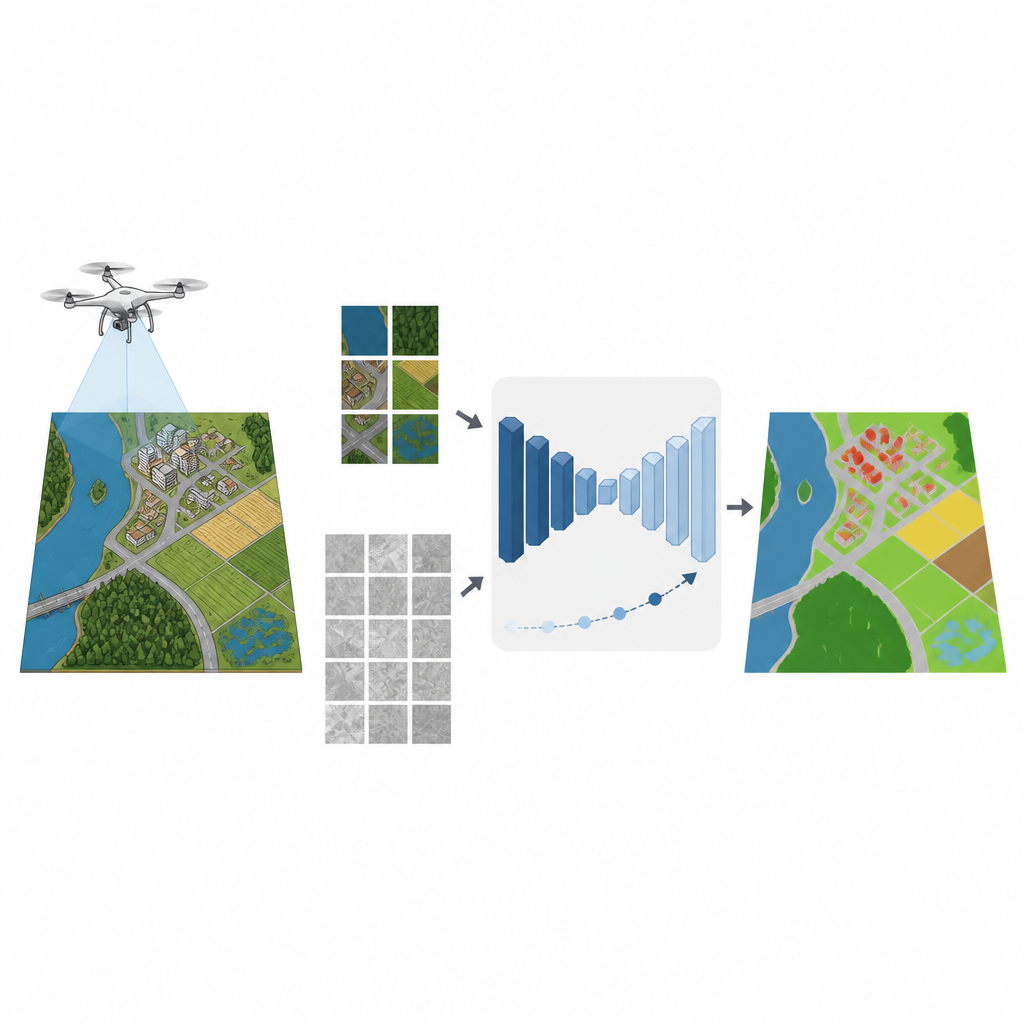
Teaching computers to read the landscape
Drone images are incredibly sharp, revealing rooftops, tree canopies, narrow paths, and shoreline edges. While this detail is valuable, it also makes automatic mapping hard. Classic methods relied on hand-designed rules about texture and color, which struggle in such complex scenes. Deep learning has pushed accuracy much higher by letting neural networks learn patterns directly from data. But this power comes with a price: to work well, these networks typically require huge labeled datasets, and drawing pixel-perfect outlines for every object in each image is slow and expensive.
Reusing knowledge from other pictures
One common shortcut is to start from models trained on massive photo collections like ImageNet and then fine-tune them on drone imagery. Another is knowledge distillation, where a strong “teacher” model guides a smaller “student” model by sharing its output patterns. However, everyday photos differ greatly from pictures taken from the air, in both viewpoint and content. When only a small number of labeled drone images is available, a teacher that has only seen natural photos may not provide the most helpful guidance, and the student can fail to reach its potential.
Building a learning bridge and using unlabeled data
The authors propose a framework that tackles both problems at once: the lack of labels and the mismatch between natural photos and drone images. First, they upgrade a popular mapping network, DeepLabV3+, by swapping in a backbone designed to keep fine details and adding an attention module that highlights important features. Next, they introduce a middle step between natural images and the final drone dataset. The model is first tuned on a medium-sized remote sensing dataset, then its knowledge is passed in stages to new student models that gradually adapt to the final drone collection. Throughout this process, special losses help the student copy the teacher’s behavior without forgetting useful earlier lessons. 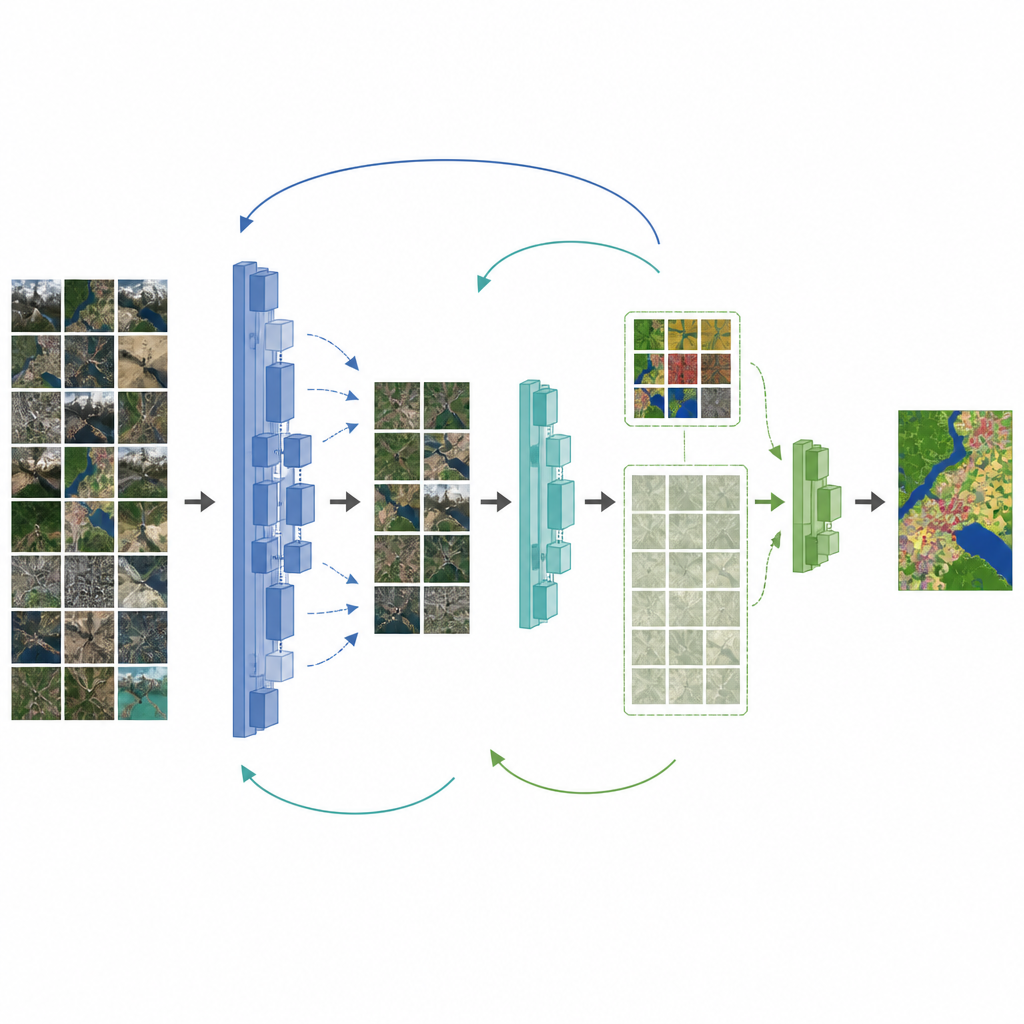
Letting the model learn from what is unlabeled
To make better use of the many unlabeled drone images, the framework adds a semi-supervised stage. Here, an up-to-date teacher model labels unlabeled images on its own and keeps only the predictions it is most confident about. These “pseudo-labels,” combined with the small set of human labels, are used to train a student model that must stay consistent with the teacher on both real and pseudo-labeled data. The teacher’s weights are slowly updated from the student’s progress, creating a loop where both improve together. Tests on a detailed drone dataset over China’s Erhai region show that this strategy significantly raises mapping accuracy, especially for roads and farmland, even when only a fraction of images are labeled.
How well the approach works in different places
Beyond the Erhai dataset, the researchers apply their method to a widely used street-scene benchmark. By inserting a suitable intermediate dataset whose scenes resemble city streets, they again see better performance than other leading methods, particularly when labeled images are scarce. Experiments also reveal that choosing the right intermediate dataset is crucial: when the scenes in this middle step are too different from the final target, performance can drop instead of rise. Overall, the combination of staged teaching, detail-preserving architecture, and smart use of unlabeled data gives a flexible recipe that adapts to different mapping tasks.
What this means for real-world mapping
For non-specialists, the main message is that high-quality maps from drone imagery no longer require massive amounts of human tracing. By carefully reusing knowledge from large image collections, adding a well-chosen bridge dataset, and letting the model teach itself from unlabeled pictures, the proposed method delivers more accurate land-cover maps with much less manual work. This could make it easier for local planners, farmers, and disaster response teams to keep up-to-date, detailed views of the land while keeping time and costs under control.
Citation: Jiang, HL., Wang, N., Geng, B. et al. A few-shot high-resolution remote sensing image semantic segmentation method. Sci Rep 16, 15262 (2026). https://doi.org/10.1038/s41598-026-46887-y
Keywords: remote sensing, UAV imagery, semantic segmentation, semi-supervised learning, knowledge distillation