Clear Sky Science · es
Un método de segmentación semántica de imágenes de teledetección de alta resolución con pocos ejemplares
Por qué importan más las fotos tomadas desde el cielo
Desde el seguimiento de inundaciones hasta el mapeo de nuevos barrios, muchas decisiones modernas dependen de imágenes detalladas tomadas con drones pequeños. Convertir esas imágenes en mapas claros de carreteras, campos, edificios y agua suele exigir miles de etiquetas dibujadas a mano por expertos. Este estudio muestra cómo los ordenadores pueden aprender a generar mapas precisos a partir de imágenes de drones usando muchas menos muestras etiquetadas por humanos, lo que podría reducir costes y acelerar trabajos ambientales y urbanos vitales. 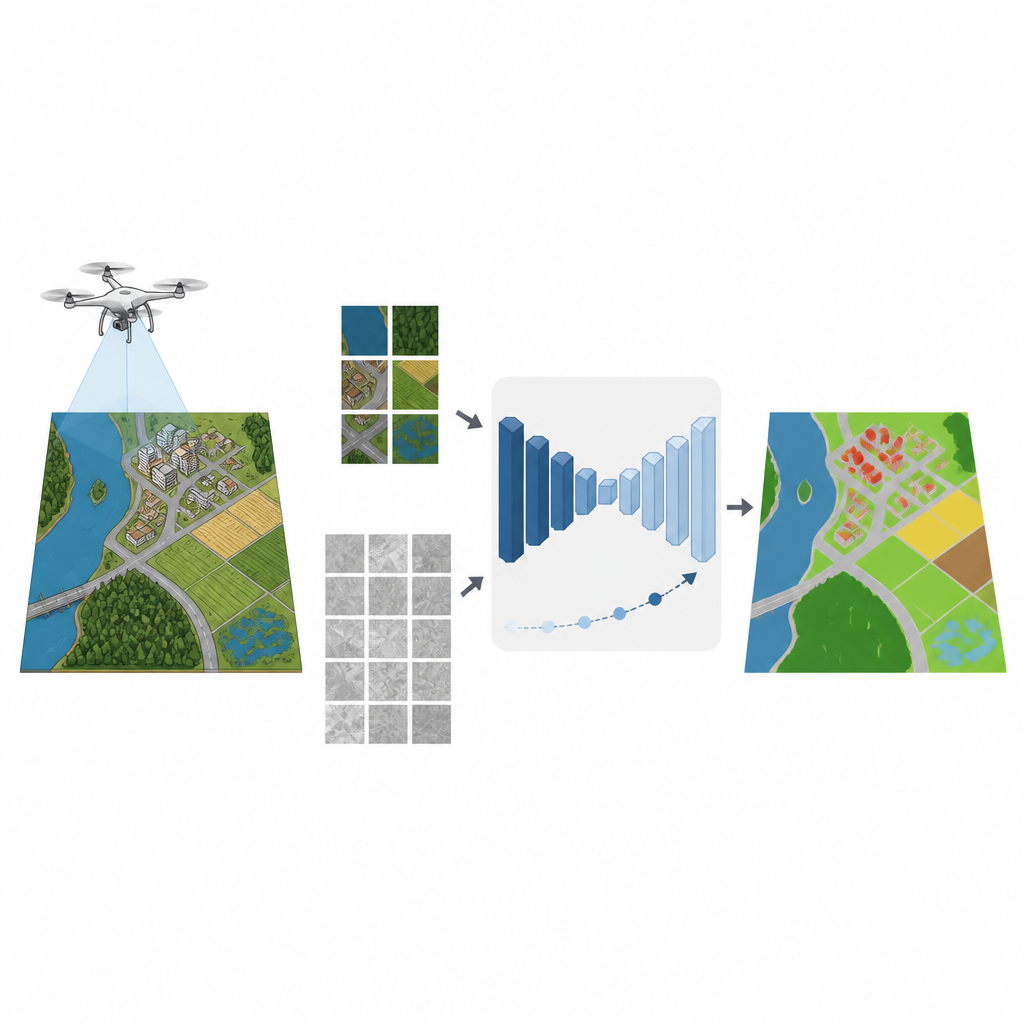
Enseñar a los ordenadores a leer el paisaje
Las imágenes de drones son increíblemente nítidas, revelando tejados, copas de árboles, senderos estrechos y líneas de costa. Aunque este detalle es valioso, también complica el mapeo automático. Los métodos clásicos se basaban en reglas diseñadas a mano sobre textura y color, que flaquean en escenas tan complejas. El aprendizaje profundo ha elevado mucho la precisión al permitir que las redes neuronales aprendan patrones directamente de los datos. Pero ese poder tiene un coste: para funcionar bien, estas redes suelen requerir enormes conjuntos de datos etiquetados, y trazar contornos pixel a pixel para cada objeto en cada imagen es lento y caro.
Reutilizar conocimiento de otras imágenes
Un atajo habitual es partir de modelos entrenados en colecciones masivas de fotos como ImageNet y luego ajustarlos (fine-tune) con imágenes de drones. Otra estrategia es la destilación de conocimiento, donde un modelo “profesor” potente guía a un modelo “estudiante” más pequeño compartiendo sus patrones de salida. Sin embargo, las fotos cotidianas difieren mucho de las tomadas desde el aire, tanto en perspectiva como en contenido. Cuando solo hay un pequeño número de imágenes de drones etiquetadas, un profesor que solo ha visto fotos naturales puede no proporcionar la guía más útil, y el estudiante puede no alcanzar su potencial.
Construir un puente de aprendizaje y usar datos no etiquetados
Los autores proponen un marco que aborda ambos problemas a la vez: la escasez de etiquetas y la discrepancia entre fotos naturales y imágenes de drones. Primero, mejoran una red de mapeo popular, DeepLabV3+, sustituyendo la columna vertebral por una diseñada para conservar detalles finos y añadiendo un módulo de atención que resalta características importantes. A continuación, introducen un paso intermedio entre las imágenes naturales y el conjunto final de drones. El modelo se ajusta primero en un conjunto de teledetección de tamaño medio, y luego su conocimiento se transmite por etapas a nuevos modelos estudiantes que se adaptan gradualmente a la colección final de drones. A lo largo de este proceso, pérdidas especiales ayudan al estudiante a copiar el comportamiento del profesor sin olvidar lecciones útiles aprendidas antes. 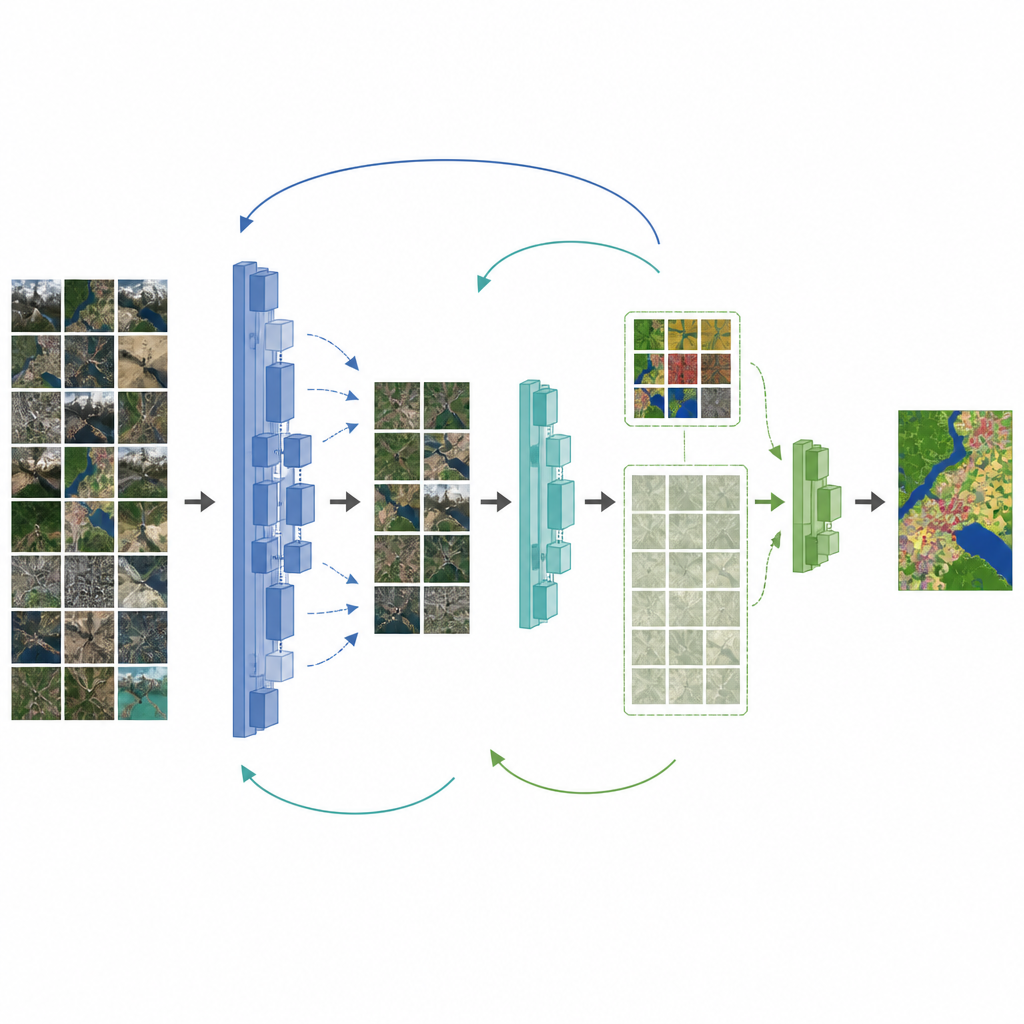
Permitir que el modelo aprenda de lo no etiquetado
Para aprovechar mejor las numerosas imágenes de drones no etiquetadas, el marco añade una etapa semi-supervisada. Aquí, un modelo profesor actualizado etiqueta automáticamente las imágenes no etiquetadas y conserva solo las predicciones en las que tiene mayor confianza. Estas “pseudoetiquetas”, combinadas con el pequeño conjunto de etiquetas humanas, se usan para entrenar a un modelo estudiante que debe mantenerse coherente con el profesor tanto en datos reales como en pseudoetiquetados. Los pesos del profesor se actualizan lentamente a partir del progreso del estudiante, creando un bucle en el que ambos mejoran de forma conjunta. Pruebas en un conjunto de datos detallado de drones sobre la región de Erhai en China muestran que esta estrategia aumenta significativamente la precisión del mapeo, especialmente para carreteras y tierras agrícolas, incluso cuando solo una fracción de imágenes está etiquetada.
Cómo funciona el enfoque en diferentes lugares
Más allá del conjunto de Erhai, los investigadores aplican su método a un banco de pruebas de escenas urbanas ampliamente usado. Al insertar un conjunto intermedio apropiado cuyas escenas se asemejan a calles de ciudad, vuelven a observar un mejor rendimiento que otros métodos punteros, particularmente cuando las imágenes etiquetadas son escasas. Los experimentos también revelan que elegir el conjunto intermedio adecuado es crucial: cuando las escenas en este paso medio son demasiado diferentes del objetivo final, el rendimiento puede bajar en lugar de mejorar. En conjunto, la combinación de enseñanza por etapas, arquitectura que preserva detalles y uso inteligente de datos no etiquetados ofrece una receta flexible que se adapta a distintas tareas de mapeo.
Qué implica esto para el mapeo en el mundo real
Para el público no especializado, el mensaje principal es que ya no se necesitan cantidades masivas de trazados manuales para obtener mapas de alta calidad a partir de imágenes de drones. Reutilizando cuidadosamente el conocimiento de grandes colecciones de imágenes, añadiendo un conjunto puente bien escogido y permitiendo que el modelo se enseñe a sí mismo a partir de imágenes no etiquetadas, el método propuesto entrega mapas de cobertura del suelo más precisos con mucho menos trabajo manual. Esto podría facilitar que urbanistas locales, agricultores y equipos de respuesta a desastres dispongan de vistas detalladas y actualizadas del territorio, manteniendo a raya tiempos y costes.
Cita: Jiang, HL., Wang, N., Geng, B. et al. A few-shot high-resolution remote sensing image semantic segmentation method. Sci Rep 16, 15262 (2026). https://doi.org/10.1038/s41598-026-46887-y
Palabras clave: teledetección, imágenes UAV, segmentación semántica, aprendizaje semi-supervisado, destilación de conocimiento