Clear Sky Science · it
Un metodo di segmentazione semantica ad alta risoluzione per immagini telerilevate con pochi esempi
Perché le foto fatte dal cielo devono essere più intelligenti
Dalla sorveglianza delle inondazioni alla mappatura di nuovi quartieri, molte decisioni moderne si basano su immagini dettagliate riprese da piccoli droni. Trasformare quelle immagini in mappe chiare di strade, campi, edifici e specchi d’acqua richiede di solito migliaia di etichette disegnate a mano da esperti. Questo studio mostra come i computer possano imparare a produrre mappe accurate dalle immagini dei droni usando molte meno istanze etichettate dall’uomo, riducendo i costi e accelerando lavori ambientali e urbani cruciali. 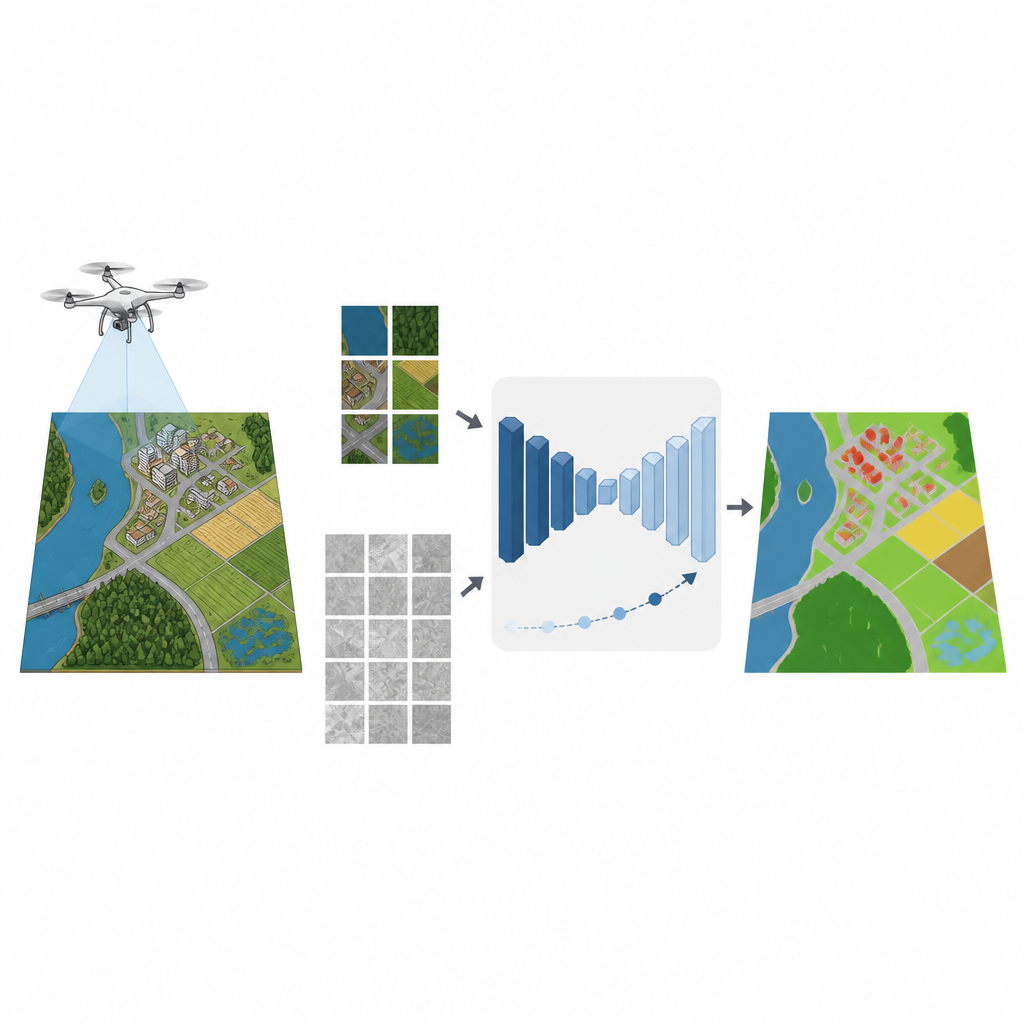
Insegnare ai computer a leggere il paesaggio
Le immagini dei droni sono estremamente nitide, rivelando tetti, coperture arboree, sentieri stretti e linee di riva. Sebbene questo livello di dettaglio sia prezioso, complica anche la mappatura automatica. I metodi classici si basavano su regole progettate a mano su texture e colore, che faticano in scene così complesse. Il deep learning ha aumentato notevolmente la precisione consentendo alle reti neurali di imparare i modelli direttamente dai dati. Ma questo vantaggio ha un costo: per funzionare bene, queste reti richiedono tipicamente grandi dataset etichettati, e tracciare contorni pixel-per-pixel per ogni oggetto in ogni immagine è lento e costoso.
Riutilizzare conoscenze da altre immagini
Una scorciatoia comune è partire da modelli addestrati su grandi raccolte fotografiche come ImageNet e poi riadattarli alle immagini da drone. Un’altra è la distillazione della conoscenza, in cui un robusto modello “insegnante” guida un modello “studente” più piccolo condividendo i propri pattern di output. Tuttavia, le foto di uso quotidiano differiscono molto dalle immagini aeree, sia per punto di vista sia per contenuto. Quando è disponibile un numero limitato di immagini da drone etichettate, un insegnante che ha visto solo foto naturali potrebbe non offrire la guida più utile e lo studente rischia di non esprimere il proprio potenziale.
Costruire un ponte di apprendimento e usare dati non etichettati
Gli autori propongono un framework che affronta insieme entrambi i problemi: la scarsità di etichette e il disallineamento tra foto naturali e immagini da drone. Innanzitutto migliorano una rete di mappatura popolare, DeepLabV3+, sostituendo il backbone con uno progettato per preservare i dettagli fini e aggiungendo un modulo di attenzione che valorizza le caratteristiche importanti. Poi introducono una fase intermedia tra le immagini naturali e il dataset finale dei droni. Il modello viene prima affinato su un dataset di telerilevamento di dimensioni medie, quindi la sua conoscenza viene trasferita per stadi a nuovi modelli studenti che si adattano gradualmente alla collezione finale di immagini da drone. Durante questo processo, perdite apposite aiutano lo studente a copiare il comportamento dell’insegnante senza dimenticare lezioni utili apprese in precedenza. 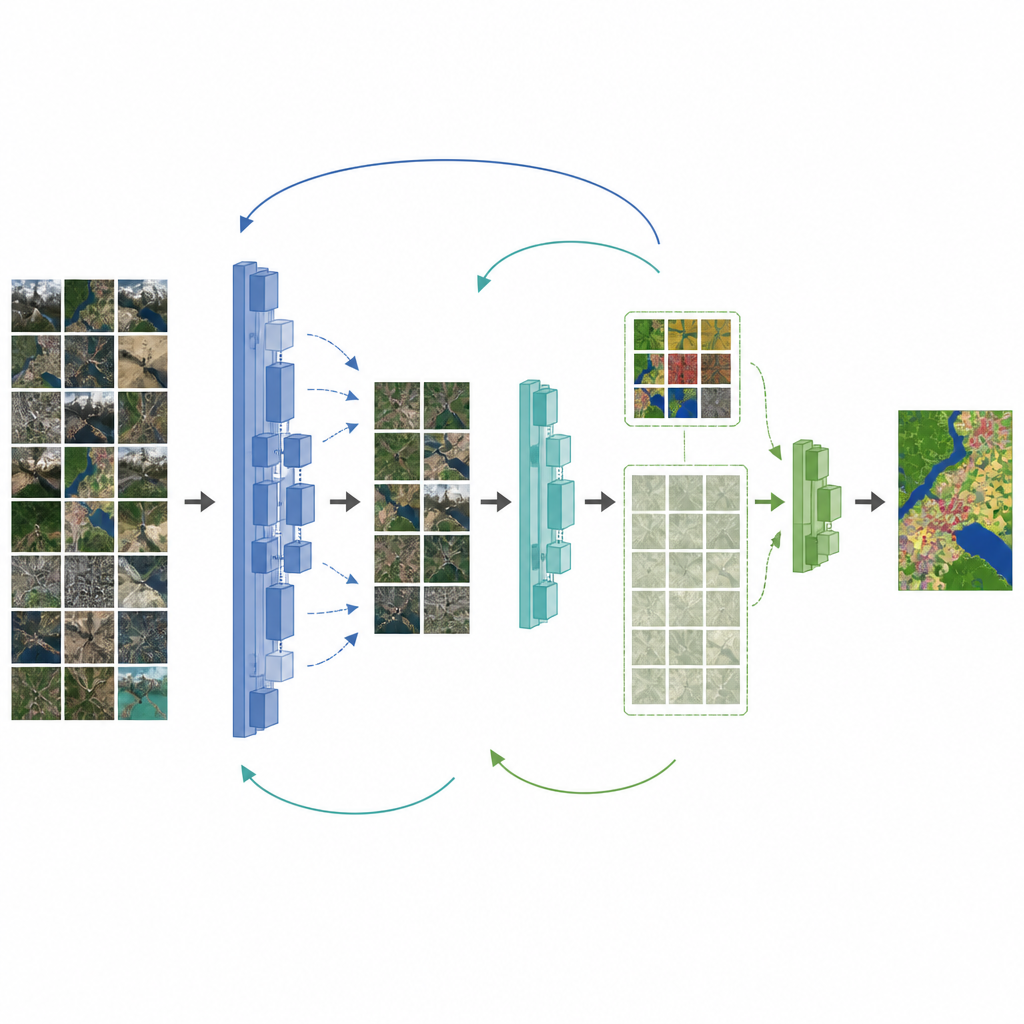
Lasciare che il modello impari da ciò che non è etichettato
Per sfruttare meglio le numerose immagini da drone non etichettate, il framework aggiunge una fase semi-supervisionata. Qui un insegnante aggiornato etichetta autonomamente le immagini non etichettate e conserva solo le predizioni di cui è più sicuro. Queste “pseudo-etichettature”, combinate con il piccolo insieme di etichette umane, sono usate per addestrare uno studente che deve mantenere coerenza con l’insegnante sia sui dati reali sia su quelli pseudo-etichettati. I pesi dell’insegnante vengono aggiornati lentamente a partire dai progressi dello studente, creando un ciclo in cui entrambi migliorano insieme. Test su un dataset dettagliato di droni nella regione di Erhai, in Cina, mostrano che questa strategia aumenta in modo significativo la precisione di mappatura, soprattutto per strade e terreni agricoli, anche quando è etichettata solo una frazione delle immagini.
Quanto bene funziona l’approccio in luoghi diversi
Oltre al dataset di Erhai, i ricercatori applicano il loro metodo a un ampio benchmark di scene stradali. Inserendo un dataset intermedio adeguato le cui scene somiglino a quelle urbane, ottengono nuovamente prestazioni migliori rispetto ad altri metodi di punta, in particolare quando le immagini etichettate sono scarse. Gli esperimenti mostrano anche che la scelta del dataset intermedio è cruciale: se le scene in questo passo intermedio sono troppo diverse dall’obiettivo finale, le prestazioni possono diminuire invece che migliorare. Nel complesso, la combinazione di insegnamento a fasi, architettura che preserva i dettagli e uso intelligente dei dati non etichettati fornisce una ricetta flessibile che si adatta a diversi compiti di mappatura.
Cosa significa questo per la mappatura nel mondo reale
Per i non specialisti, il messaggio principale è che ottenere mappe di alta qualità dalle immagini dei droni non richiede più enormi quantità di tracciatura manuale. Riutilizzando con cura conoscenze da grandi raccolte di immagini, aggiungendo un dataset ponte ben scelto e permettendo al modello di auto-insegnarsi da immagini non etichettate, il metodo proposto produce mappe di copertura del suolo più accurate con molto meno lavoro manuale. Questo potrebbe facilitare per pianificatori locali, agricoltori e squadre di risposta ai disastri il mantenimento di viste dettagliate e aggiornate del territorio, contenendo tempi e costi.
Citazione: Jiang, HL., Wang, N., Geng, B. et al. A few-shot high-resolution remote sensing image semantic segmentation method. Sci Rep 16, 15262 (2026). https://doi.org/10.1038/s41598-026-46887-y
Parole chiave: telerilevamento, immagini UAV, segmentazione semantica, apprendimento semi-supervisionato, distillazione della conoscenza