Clear Sky Science · pt
Generalização em domínio único baseada em transformada de Fourier para contagem de multidões
Por que contagens de multidão mais inteligentes importam
De festivais de música e estações de metrô a ruas da cidade em uma noite chuvosa, saber aproximadamente quantas pessoas estão em um espaço é vital para planejamento de segurança, controle de tráfego e resposta a emergências. Os sistemas de computador atuais conseguem estimar o tamanho de multidões a partir de imagens de câmera, mas frequentemente falham quando as condições mudam — por exemplo, quando a câmera é reposicionada, a iluminação passa de dia para noite, ou névoa e desfoque obscurecem detalhes. Este artigo apresenta o SinCount, uma nova abordagem que busca tornar a contagem automática de multidões muito mais confiável no mundo real desordenado e em constante mudança.
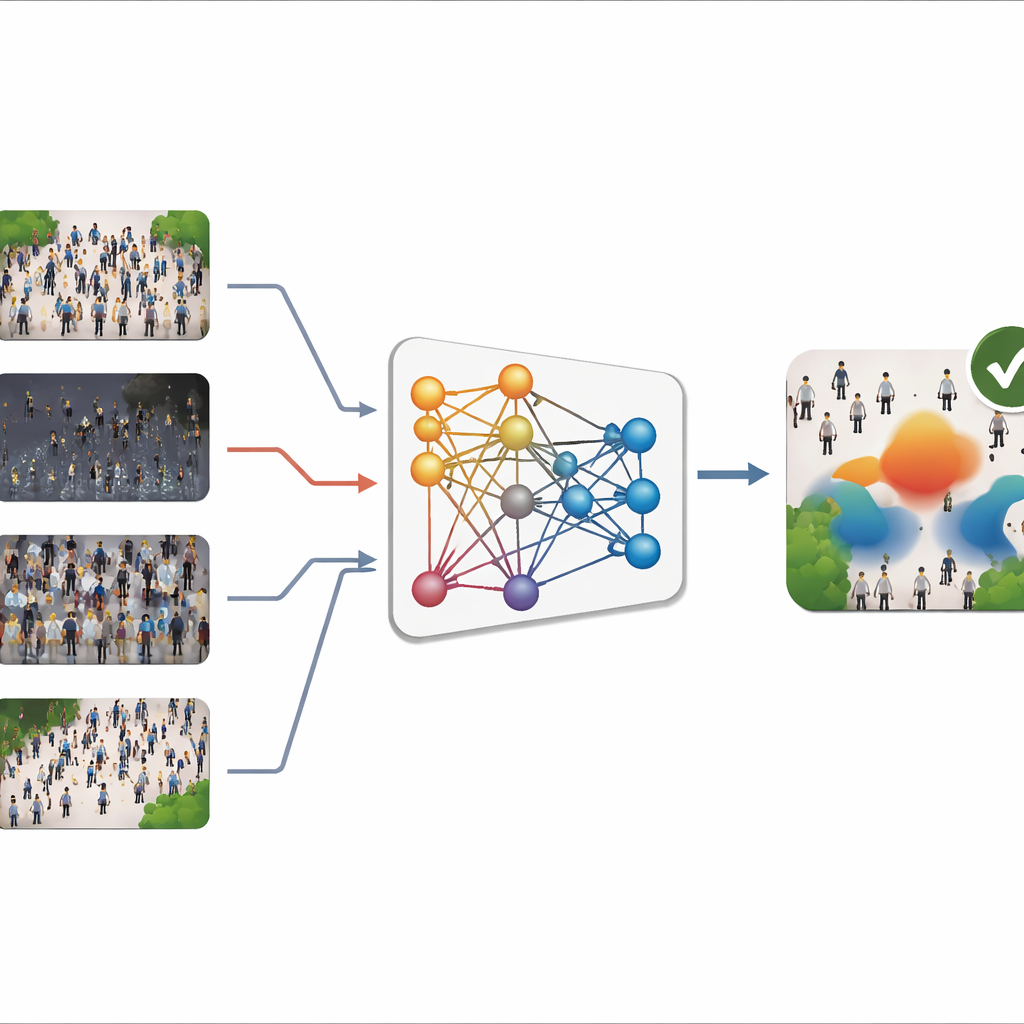
O problema das cenas em mudança
A maioria dos contadores de multidões modernos usa aprendizado profundo para transformar uma imagem em um “mapa de densidade”, um tipo de padrão térmico que mostra onde as pessoas estão e quão compactas estão. Somar esse mapa fornece a contagem total. Esses sistemas podem ser muito precisos quando as imagens que observam em operação se parecem com as usadas no treinamento. Na prática, contudo, as cenas reais variam drasticamente: câmeras apontam em ângulos diferentes, multidões vão de calçadas esparsas a estádios lotados, e clima e iluminação podem mudar de sol forte a noites com neblina. Coletar novas imagens rotuladas para cada local é lento e caro, especialmente porque cada pessoa precisa ser marcada manualmente. Como resultado, modelos treinados em um cenário muitas vezes falham quando transferidos para outro — um problema conhecido como “mudança de domínio”.
Olhando para multidões por frequências
Os autores enfrentam esse problema ao ver imagens não apenas como pixels, mas como combinações de frequências, no sentido usado na transformada de Fourier. Partes de alta frequência destacam bordas nítidas e detalhes finos, como contornos de cabeças e ombros. Partes de baixa frequência capturam a disposição ampla da cena, como onde a multidão está geralmente localizada ou quão densa é em diferentes regiões. A equipe observa que esses dois tipos de informação naturalmente servem a duas tarefas distintas: pistas de alta frequência são melhores para estimar quantas pessoas há em cada pequeno trecho, enquanto pistas mais suaves de baixa frequência são melhores para decidir quais áreas realmente contêm multidões em contraste com o fundo.
Dois componentes que compartilham a carga
Construindo sobre essa ideia, o SinCount usa um projeto de duas ramificações. Um extrator de características compartilhado primeiro processa a imagem e depois se divide em um ramo de densidade e um ramo de classificação. Um módulo especial, chamado Extração de Características Específicas por Frequência, separa versões de alta e baixa frequência da cena e aprende representações internas compactas de cada uma. O ramo de densidade recebe orientação de alta frequência por meio de um bloco de atenção espacial que destaca posições que provavelmente correspondem a pessoas, refinando o mapa de densidade final. Enquanto isso, o ramo de classificação recebe orientação de baixa frequência através de atenção baseada em canal que reforça características vinculadas às regiões de multidão e suprime o fundo irrelevante. Juntas, essas duas ramificações produzem um mapa de densidade refinado que foca nas áreas de multidão enquanto ignora regiões vazias ou confusas.
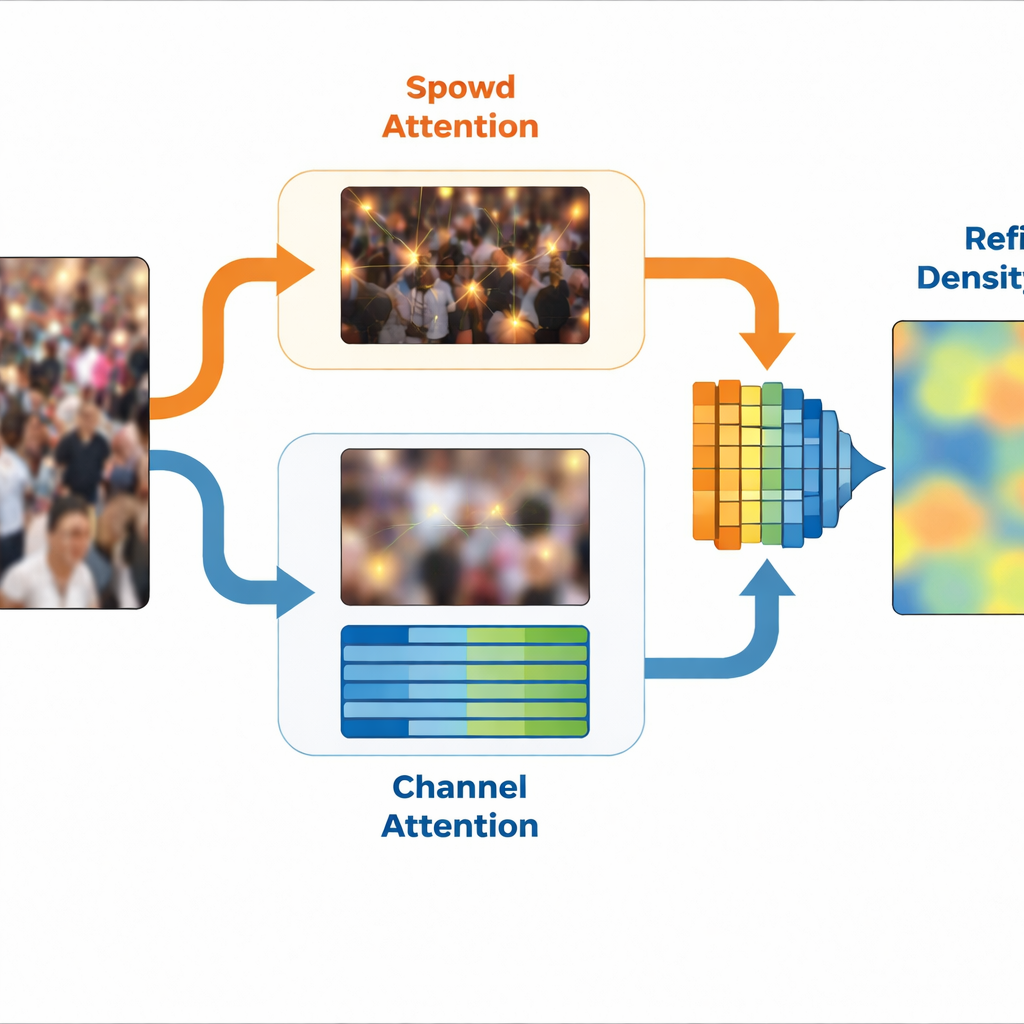
Manter o foco em um mundo ruidoso
Imagens reais também contêm distrações: reflexos, desfoque de movimento ou mudanças de iluminação podem levar o modelo a padrões enganosos. Para se proteger contra isso, o SinCount adiciona mais duas ideias. Uma máscara de normalização por instância compara como as características respondem à imagem original e a uma versão aumentada (por exemplo, com alteração de cor ou desfoque) e reduz a importância de locais que mudam demais, tratando-os como não confiáveis. Uma perda de consistência de atenção então incentiva o sistema a olhar para regiões semelhantes em ambas as versões da imagem, para que seu foco não se desvie apenas porque a aparência mudou ligeiramente. Sinais de treinamento adicionais empurram o caminho de alta frequência a corresponder melhor às densidades verdadeiras de multidão e o caminho de baixa frequência a corresponder melhor às regiões multidão-versus-fundo.
O que os resultados significam na prática
Os pesquisadores testam o SinCount em vários conjuntos de dados públicos desafiadores, incluindo estádios lotados, ruas da cidade e cenas noturnas com desfoque e pouca luz. Sem nunca ver exemplos dos cenários-alvo durante o treinamento, o SinCount iguala ou supera métodos existentes de generalização em domínio único, frequentemente com processamento mais rápido porque evita módulos de memória pesados usados por projetos anteriores. Em termos práticos, o sistema aprende a contar multidões em um ambiente e então faz um trabalho sólido quando aplicado a muitos outros que nunca viu. Para gestores urbanos, organizadores de eventos e autoridades de segurança, isso aponta para ferramentas de monitoramento de multidões mais resilientes a novas câmeras, novos locais e clima variável — ajudando a fornecer contagens confiáveis quando mais importa.
Citação: Song, L., Li, T., Cai, Z. et al. Fourier transform-based single domain generalization for crowd counting. Sci Rep 16, 11744 (2026). https://doi.org/10.1038/s41598-026-46286-3
Palavras-chave: contagem de multidões, generalização de domínio, frequência de Fourier, visão computacional, mapas de densidade