Clear Sky Science · es
Generalización de un solo dominio basada en transformada de Fourier para el recuento de multitudes
Por qué importan recuentos de multitudes más inteligentes
Desde festivales de música y estaciones de metro hasta calles de la ciudad en una noche lluviosa, conocer aproximaciones del número de personas en un espacio es vital para la planificación de la seguridad, el control del tráfico y la respuesta a emergencias. Los sistemas informáticos actuales pueden estimar el tamaño de las multitudes a partir de imágenes de cámara, pero con frecuencia fallan cuando cambian las condiciones —por ejemplo, si se mueve la cámara, la iluminación pasa de día a noche, o la niebla y el desenfoque ocultan detalles. Este artículo presenta SinCount, un enfoque novedoso que pretende hacer que el recuento automático de multitudes sea mucho más fiable en el mundo real, desordenado y en constante cambio.
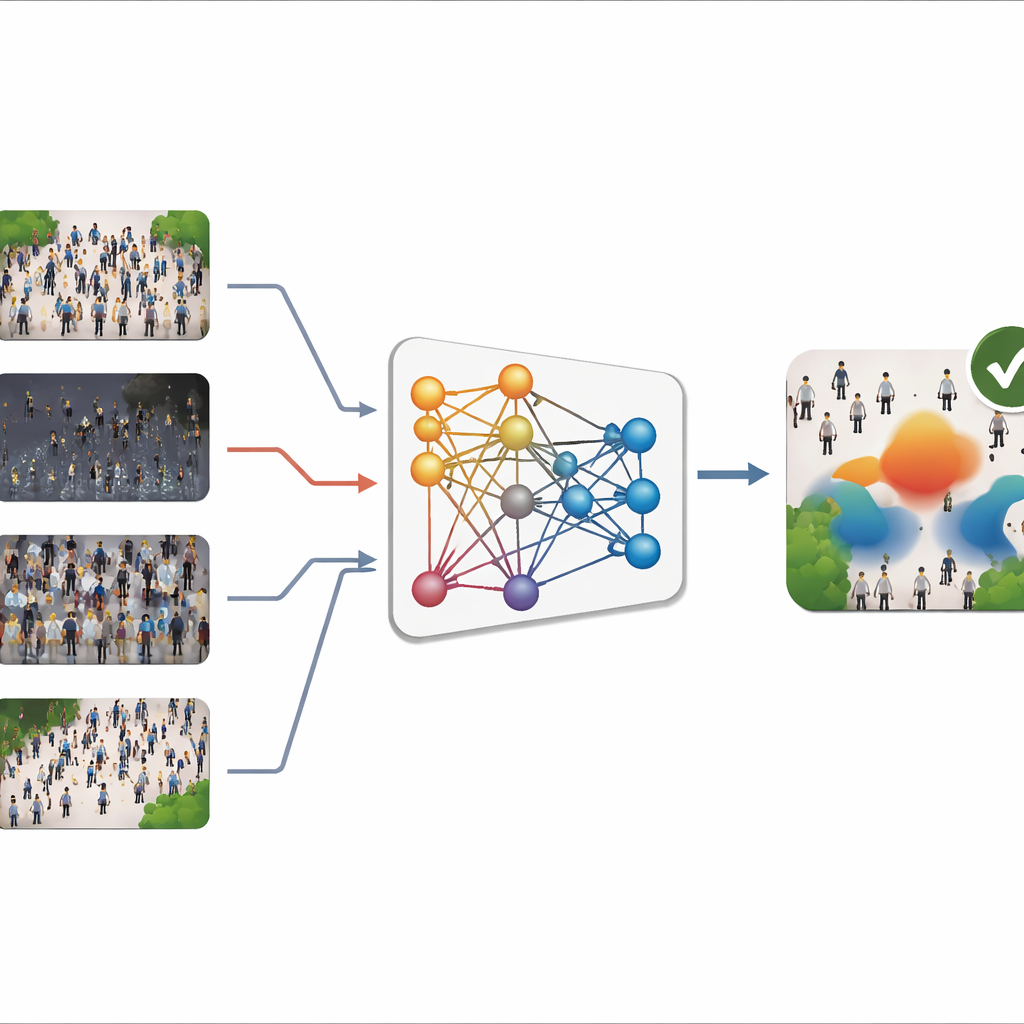
El problema de las escenas cambiantes
La mayoría de los contadores de multitudes modernos usan aprendizaje profundo para transformar una imagen en un “mapa de densidad”, una especie de patrón de calor que muestra dónde están las personas y cuán compactas están. Sumar ese mapa da el recuento total. Estos sistemas pueden ser muy precisos cuando las imágenes que ven durante su funcionamiento se parecen a las de su entrenamiento. En la práctica, sin embargo, las escenas reales varían enormemente: las cámaras apuntan desde ángulos distintos, las multitudes van desde aceras dispersas hasta estadios abarrotados, y el clima y la iluminación pueden cambiar de sol brillante a noches con niebla. Recopilar nuevas imágenes etiquetadas para cada sitio es lento y costoso, sobre todo porque cada persona debe marcarse a mano. Como resultado, los modelos entrenados en un entorno suelen fallar al trasladarlos a otro, un problema conocido como “desplazamiento de dominio”.
Mirar las multitudes a través de las frecuencias
Los autores abordan este problema viendo las imágenes no solo como píxeles, sino como combinaciones de frecuencias, en el sentido usado en la transformada de Fourier. Las partes de alta frecuencia resaltan bordes nítidos y detalles finos, como los contornos de cabezas y hombros. Las partes de baja frecuencia capturan la estructura amplia de la escena, por ejemplo dónde se sitúa la multitud en general o cómo varía la densidad en distintas regiones. El equipo observa que estos dos tipos de información encajan naturalmente con dos tareas diferentes: las señales de frecuencia detalladas son mejores para estimar cuántas personas hay en cada pequeña zona, mientras que las señales más suaves y de baja frecuencia son mejores para decidir qué áreas contienen realmente multitudes frente al fondo.
Dos partes operativas que comparten la carga
Basándose en esta idea, SinCount utiliza un diseño de doble rama. Un extractor de características compartido procesa primero la imagen y luego se divide en una rama de densidad y una rama de clasificación. Un módulo especial, llamado Extracción de Características Específicas por Frecuencia, separa versiones de alta y baja frecuencia de la escena y aprende representaciones internas compactas de cada una. La rama de densidad recibe orientación de alta frecuencia mediante un bloque de atención espacial que resalta posiciones que probablemente correspondan a personas, afinando el mapa de densidad final. Mientras tanto, la rama de clasificación recibe orientación de baja frecuencia mediante atención basada en canales que potencia las características vinculadas a regiones con multitudes y suprime el fondo irrelevante. Juntas, estas dos ramas producen un mapa de densidad refinado que se centra en las áreas de multitud mientras ignora regiones vacías o confusas.
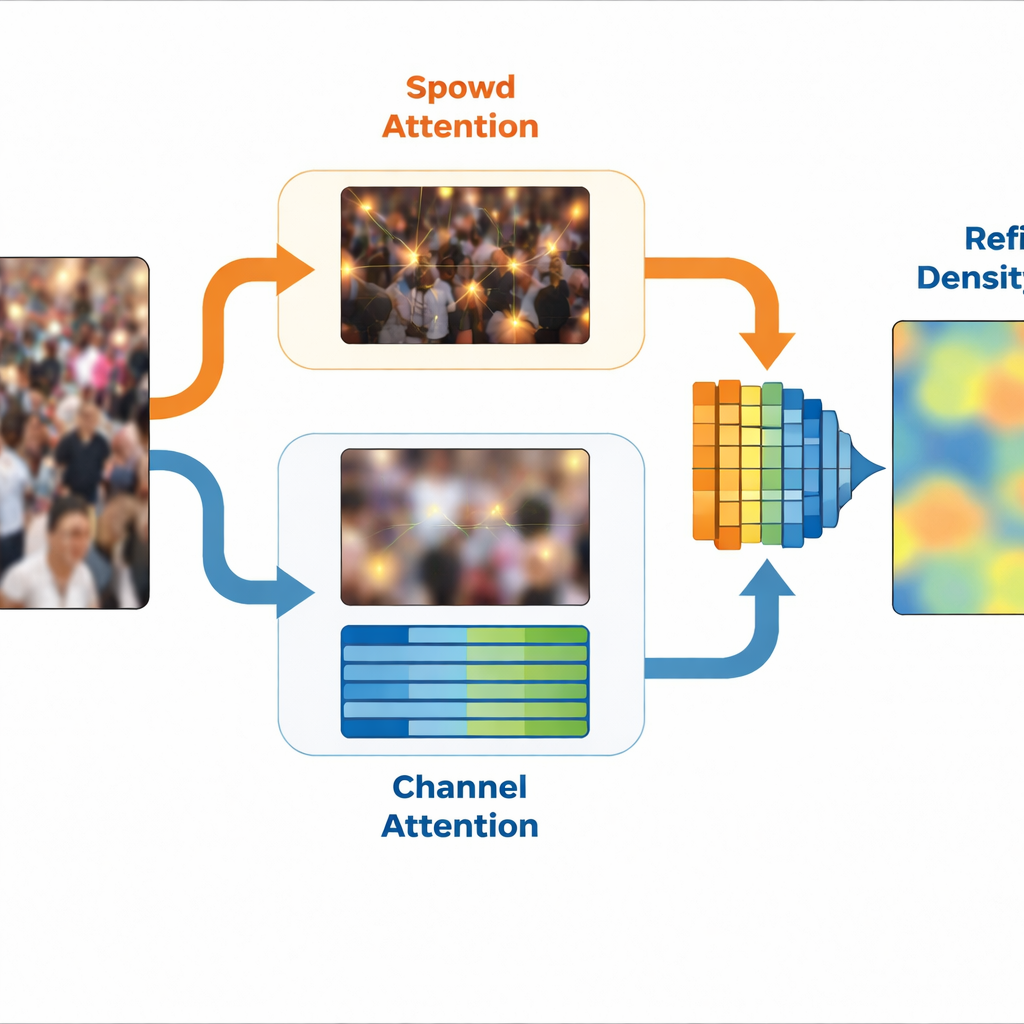
Mantener el foco en un mundo ruidoso
Las imágenes reales también contienen distracciones: el destello, el desenfoque por movimiento o los cambios de iluminación pueden inducir al modelo a patrones engañosos. Para protegerse contra esto, SinCount añade dos ideas más. Una máscara de normalización por instancia compara cómo responden las características a una imagen original y a una versión aumentada (por ejemplo, una con jitter de color o desenfocada) y atenúa las ubicaciones que cambian demasiado, tratándolas como poco fiables. Una pérdida de consistencia de atención fomenta que el sistema mire regiones similares en ambas versiones de la imagen, de modo que su foco no se desvíe solo porque la apariencia haya variado levemente. Señales de entrenamiento adicionales empujan la vía de alta frecuencia a coincidir mejor con las densidades reales de multitud y la vía de baja frecuencia a identificar con mayor precisión las regiones de multitud frente al fondo.
Qué significan los resultados en la práctica
Los investigadores prueban SinCount en varios conjuntos de datos públicos desafiantes, incluidos estadios abarrotados, calles urbanas y escenas nocturnas con desenfoque y baja iluminación. Sin ver nunca ejemplos de las escenas objetivo durante el entrenamiento, SinCount iguala o supera a los métodos existentes de generalización desde un solo dominio, a menudo con un procesamiento más rápido porque evita los módulos de memoria pesados usados por diseños anteriores. En términos sencillos, el sistema aprende a contar multitudes en un entorno y luego hace un trabajo sólido cuando se despliega en muchos otros que nunca ha visto. Para gestores urbanos, organizadores de eventos y responsables de seguridad, esto apunta a herramientas de monitorización de multitudes más resistentes a nuevas cámaras, nuevas ubicaciones y cambios meteorológicos —ayudando a ofrecer recuentos fiables cuando más importan.
Cita: Song, L., Li, T., Cai, Z. et al. Fourier transform-based single domain generalization for crowd counting. Sci Rep 16, 11744 (2026). https://doi.org/10.1038/s41598-026-46286-3
Palabras clave: recuento de multitudes, generalización de dominio, frecuencia de Fourier, visión por computador, mapas de densidad