Clear Sky Science · nl
Fourier-transformatiegerichte single-domain generalisatie voor crowd counting
Waarom slimmer tellen van mensenmassa’s belangrijk is
Van muziekfestivals en metrostations tot stadsstraten op een regenachtige avond: globaal weten hoeveel mensen zich in een ruimte bevinden is essentieel voor veiligheidsplanning, verkeersregeling en hulpdiensten. Huidige computersystemen kunnen op basis van camerabeelden schattingen van publieksgrootte geven, maar ze falen vaak wanneer de omstandigheden veranderen—bijvoorbeeld als een camera verplaatst wordt, het licht van dag naar nacht verschuift, of mist en onscherpte details verbergen. Dit artikel introduceert SinCount, een nieuwe aanpak die tot doel heeft het geautomatiseerde tellen van mensen veel betrouwbaarder te maken in de rommelige, continu veranderende echte wereld.
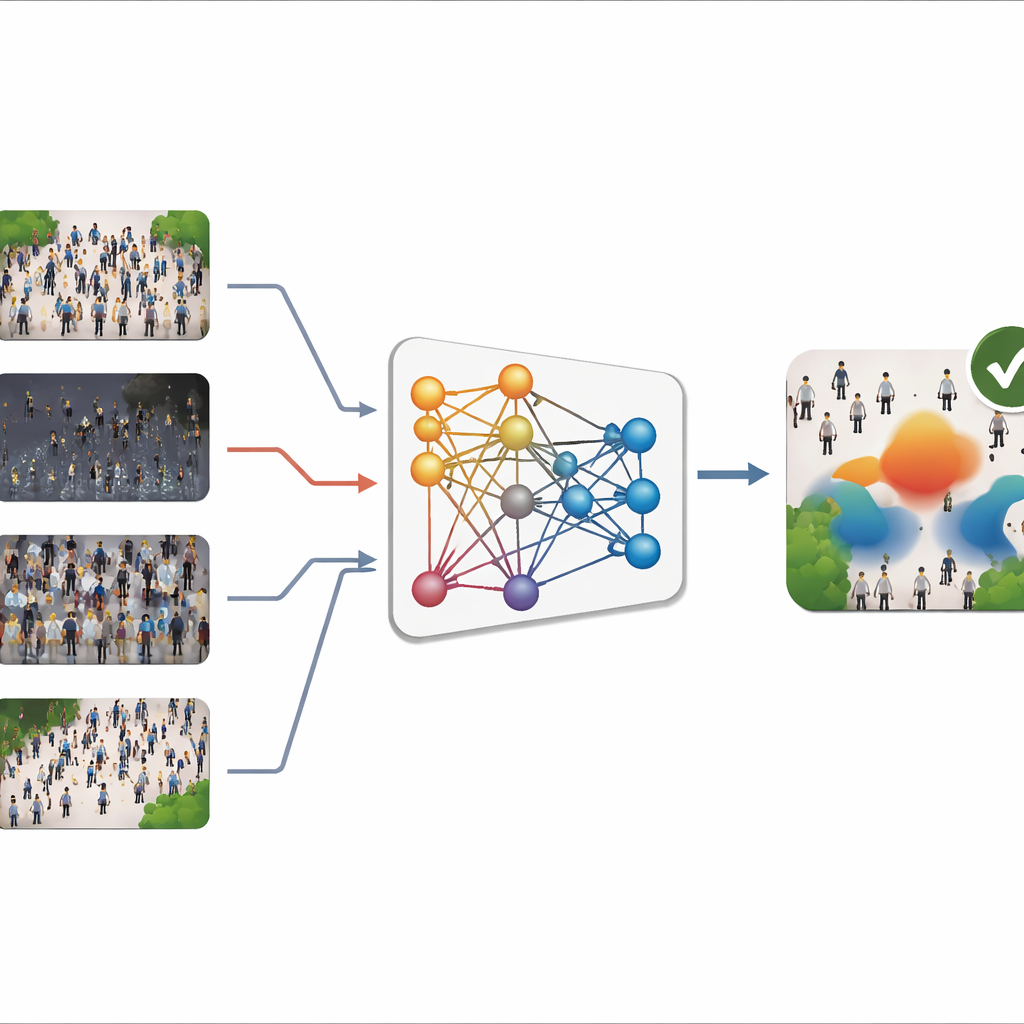
Het probleem van veranderende scènes
De meeste moderne crowd-counters gebruiken deep learning om een afbeelding om te zetten in een zogenaamde “dichtheidskaart”, een soort warmtepatroon dat aangeeft waar mensen zich bevinden en hoe dicht ze op elkaar staan. Het optellen van deze kaart levert de totale telling. Deze systemen kunnen zeer nauwkeurig zijn wanneer de beelden tijdens gebruik lijken op de beelden waarop ze getraind zijn. In de praktijk variëren scènes echter enorm: camera’s wijzen onder verschillende hoeken, menigten variëren van dunne stoepen tot volgepakte stadions, en het weer en licht kunnen veranderen van felle zon tot mistige nachten. Nieuwe gelabelde beelden verzamelen voor elke locatie is traag en duur, vooral omdat iedere persoon handmatig moet worden gemarkeerd. Daarom falen modellen die in één omgeving zijn getraind vaak wanneer ze naar een andere worden verplaatst, een probleem dat bekendstaat als “domain shift”.
Beelden van menigten bekijken via frequenties
De auteurs pakken dit probleem aan door beelden niet alleen als pixels te zien, maar als combinaties van frequenties, in de zin van de Fourier-transformatie. Hoogfrequente onderdelen benadrukken scherpe randen en fijne details, zoals de omtrekken van hoofden en schouders. Laagfrequente onderdelen vatten de brede opbouw van de scène samen, bijvoorbeeld waar de menigte globaal gezien is of hoe dicht die in verschillende gebieden is. Het team merkt op dat deze twee soorten informatie van nature geschikt zijn voor twee verschillende taken: gedetailleerde frequentie-indicatoren zijn het beste om te schatten hoeveel mensen zich in elk klein vlak bevinden, terwijl vloeiendere, laagfrequente signalen beter zijn voor het beslissen welke gebieden daadwerkelijk menigten bevatten versus achtergrond.
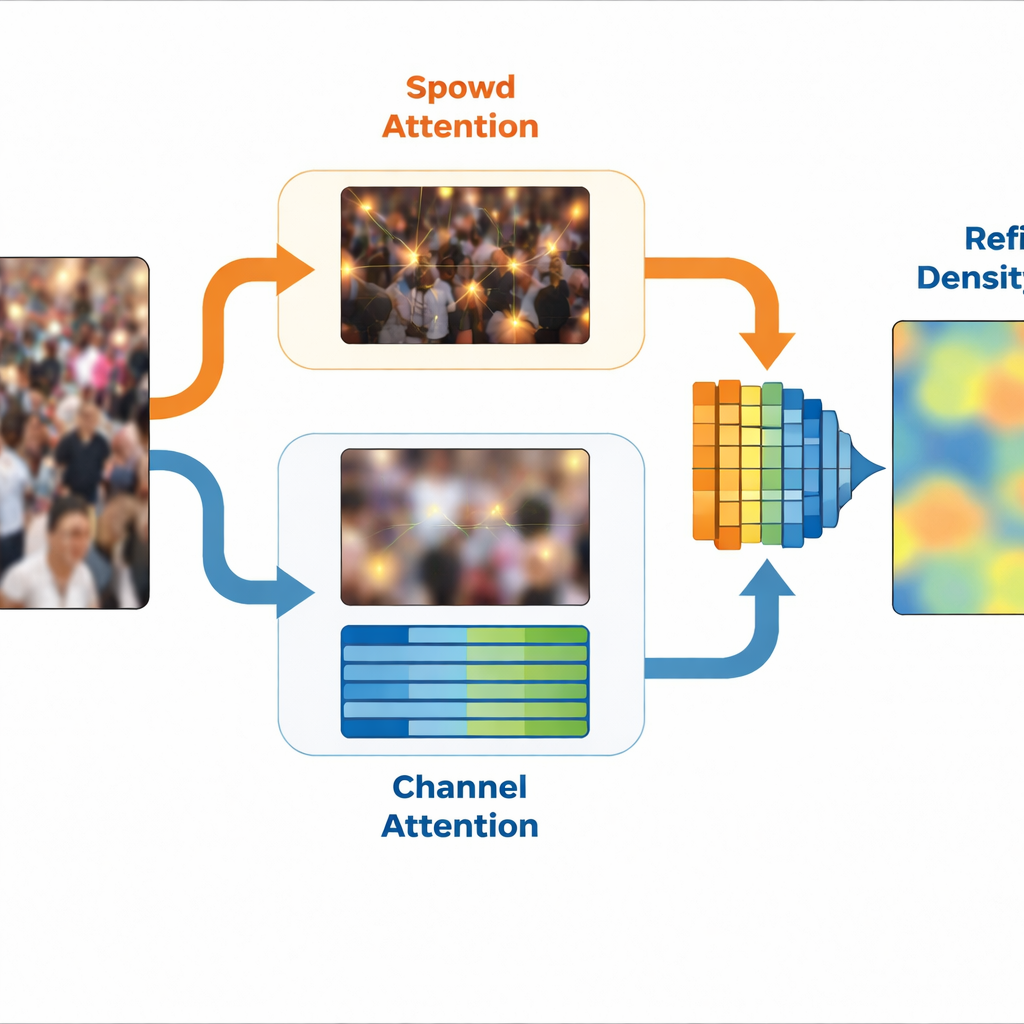
Twee samenwerkende onderdelen die de taak verdelen
Gebaseerd op dit idee gebruikt SinCount een ontwerp met twee takken. Een gedeelde feature-extractor verwerkt eerst een afbeelding en splitst daarna in een dichtheidsvertakking en een classificatievertakking. Een speciaal module, Frequency-Specific Feature Extraction, scheidt hoge- en lagefrequente versies van de scène en leert compacte interne representaties van elk. De dichtheidsvertakking ontvangt hoogfrequente begeleiding via een ruimtelijk aandachtblok dat posities benadrukt die waarschijnlijk overeenkomen met mensen, waardoor de uiteindelijke dichtheidskaart wordt aangescherpt. Ondertussen krijgt de classificatievertakking laagfrequente begeleiding via kanaalgebaseerde aandacht die kenmerken versterkt die met menigtegebieden samenhangen en irrelevante achtergrond onderdrukt. Gezamenlijk produceren deze twee takken een verfijnde dichtheidskaart die zich richt op menigtegebieden terwijl lege of verwarrende regio’s worden genegeerd.
Focus behouden in een rumoerige wereld
Echte afbeeldingen bevatten ook afleidingen: schittering, bewegingsonscherpte of lichtveranderingen kunnen het model naar misleidende patronen duwen. Om dit tegen te gaan voegt SinCount twee extra ideeën toe. Een instance normalisatie-masker vergelijkt hoe features reageren op een originele afbeelding en een geaugmenteerde versie (bijvoorbeeld één met kleurverstoringen of onscherpte) en speelt locaties die te veel veranderen naar beneden, door ze als onbetrouwbaar te behandelen. Een attention consistency loss stimuleert vervolgens het systeem om in beide versies van de afbeelding naar vergelijkbare regio’s te kijken, zodat de focus niet verandert alleen omdat het uiterlijk licht verschuift. Extra trainingssignalen dwingen het hoogfrequente pad beter overeen te komen met echte menigheidsdichtheden en het laagfrequente pad beter te matchen met menigte-vs-achtergrond regio’s.
Wat de resultaten in de praktijk betekenen
De onderzoekers testen SinCount op meerdere uitdagende openbare datasets, waaronder volgepakte stadions, stadsstraten en nachtscènes met onscherpte en weinig licht. Zonder ooit voorbeelden uit de doelscènes tijdens training te zien, evenaart of overtreft SinCount bestaande single-domain generalisatiemethoden, vaak met snellere verwerking omdat het zware geheugenmodules die eerdere ontwerpen gebruikten vermijdt. In eenvoudige termen leert het systeem mensen te tellen in één omgeving en doet het vervolgens degelijk werk wanneer het in vele andere, ongeziene omgevingen wordt ingezet. Voor stadsbeheerders, evenementenorganisatoren en veiligheidsfunctionarissen wijst dit op monitoringtools die veerkrachtiger zijn tegenover nieuwe camera’s, nieuwe locaties en veranderend weer—en zo betrouwbare hoofd-tellingen leveren wanneer het er echt toe doet.
Bronvermelding: Song, L., Li, T., Cai, Z. et al. Fourier transform-based single domain generalization for crowd counting. Sci Rep 16, 11744 (2026). https://doi.org/10.1038/s41598-026-46286-3
Trefwoorden: crowd counting, domeingeneralisatie, Fourier-frequentie, computer vision, dichtheidskaarten