Clear Sky Science · pl
Uogólnianie na jedną domenę oparte na transformatcie Fouriera dla zliczania tłumów
Dlaczego inteligentniejsze zliczanie tłumów ma znaczenie
Od festiwali muzycznych i stacji metra po ulice miasta w deszczową noc — wiedza o przybliżonej liczbie osób w danym miejscu jest kluczowa dla planowania bezpieczeństwa, kontroli ruchu i reakcji na sytuacje awaryjne. Dzisiejsze systemy komputerowe potrafią oszacować liczebność tłumów na podstawie nagrań z kamer, ale często zawodzą, gdy warunki się zmieniają — na przykład gdy kamera zostanie przesunięta, oświetlenie zmieni się z dziennego na nocne, albo mgła i rozmycie zasłonią szczegóły. W artykule przedstawiono SinCount, nowe podejście, które ma na celu uczynienie zautomatyzowanego zliczania tłumów znacznie bardziej niezawodnym w chaotycznym, ciągle zmieniającym się rzeczywistym świecie.
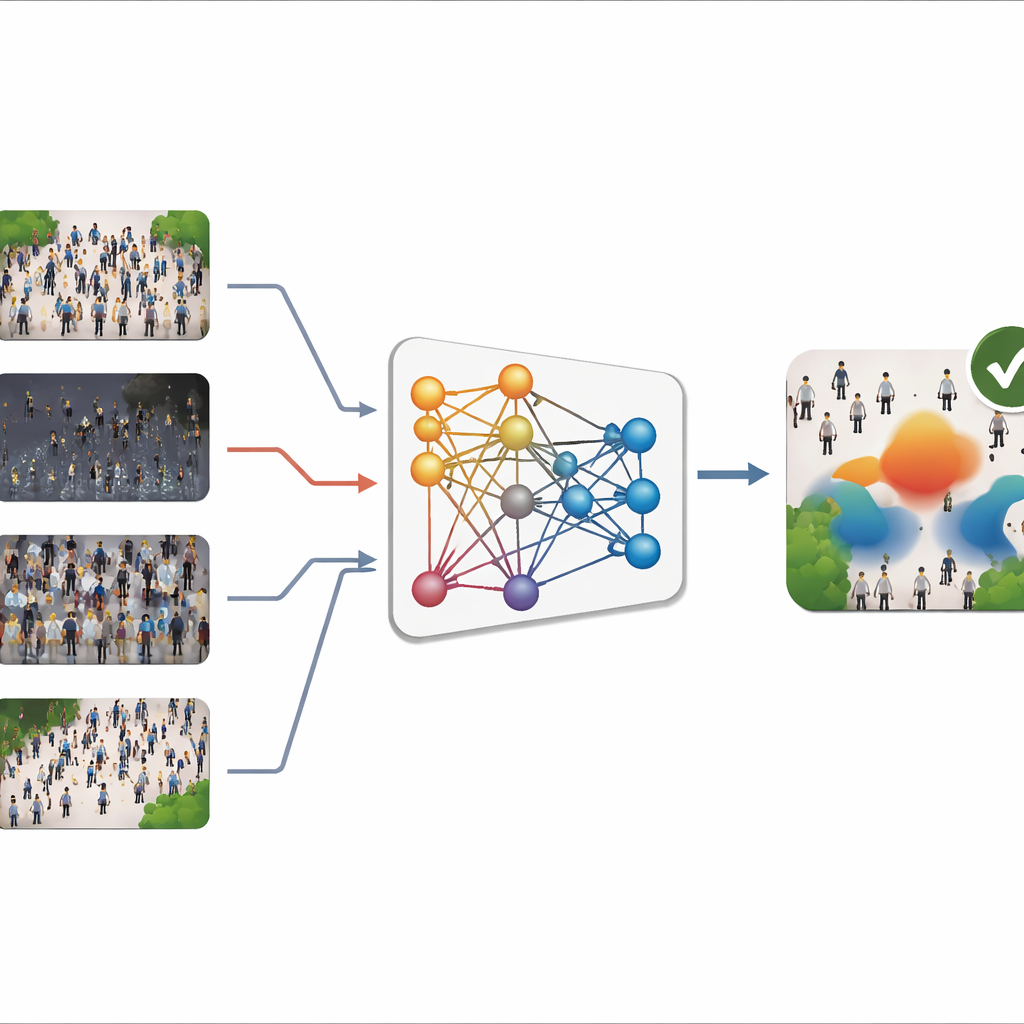
Problem zmieniających się scen
Większość współczesnych liczników tłumów wykorzystuje głębokie uczenie do przekształcenia obrazu w „mapę gęstości” — rodzaj wzoru cieplnego pokazującego, gdzie znajdują się ludzie i jak ciasno są zgromadzeni. Zsumowanie tej mapy daje całkowitą liczbę. Systemy te mogą być bardzo dokładne, gdy obrazy, które widzą w działaniu, przypominają te użyte podczas treningu. W praktyce jednak sceny zmieniają się diametralnie: kamery ustawione są pod różnymi kątami, tłumy mogą być rozproszone na chodnikach lub ściśnięte na stadionach, a pogoda i oświetlenie przechodzą od jasnego słońca po mglistą noc. Zbieranie nowych oznaczonych obrazów dla każdego miejsca jest powolne i kosztowne, zwłaszcza że każda osoba musi być zaznaczona ręcznie. W rezultacie modele wytrenowane w jednym środowisku często zawodzą po przeniesieniu do innego — problem znany jako „przesunięcie domeny”.
Patrząc na tłumy przez pryzmat częstotliwości
Autorzy rozwiązują ten problem, traktując obrazy nie tylko jako zbiory pikseli, lecz jako kombinacje częstotliwości w sensie transformacji Fouriera. Składniki wysokoczęstotliwościowe uwypuklają ostre krawędzie i drobne detale, takie jak kontury głów i ramion. Składniki niskoczęstotliwościowe oddają szeroki układ sceny, na przykład gdzie ogólnie znajduje się tłum i jak zmienia się gęstość w różnych obszarach. Zespół zauważa, że oba rodzaje informacji naturalnie nadają się do różnych zadań: szczegółowe wskazówki częstotliwościowe lepiej nadają się do oszacowania liczby osób w małych fragmentach obrazu, podczas gdy gładsze, niskoczęstotliwościowe sygnały są lepsze do rozróżnienia obszarów zajętych przez ludzi od tła.
Dwie współpracujące części dzielące zadanie
W oparciu o tę koncepcję SinCount wykorzystuje projekt z dwiema gałęziami. Wspólny ekstraktor cech najpierw przetwarza obraz, po czym rozdziela się na gałąź gęstości i gałąź klasyfikacji. Specjalny moduł, nazwany Ekstrakcją Cech Specyficznych dla Częstotliwości, rozdziela scenę na wersje wysokiej i niskiej częstotliwości i uczy się zwartych wewnętrznych reprezentacji każdej z nich. Gałąź gęstości otrzymuje wskazówki wysokoczęstotliwościowe za pośrednictwem bloków uwagi przestrzennej, które podkreślają pozycje prawdopodobnie odpowiadające ludziom, wyostrzając ostateczną mapę gęstości. Tymczasem gałąź klasyfikacji korzysta z wskazówek niskoczęstotliwościowych przez uwagę opartą na kanałach, która wzmacnia cechy związane z obszarami tłumu i tłumi nieistotne tło. Razem obie gałęzie generują dopracowaną mapę gęstości, która koncentruje się na obszarach z tłumem, ignorując puste lub mylące rejony.
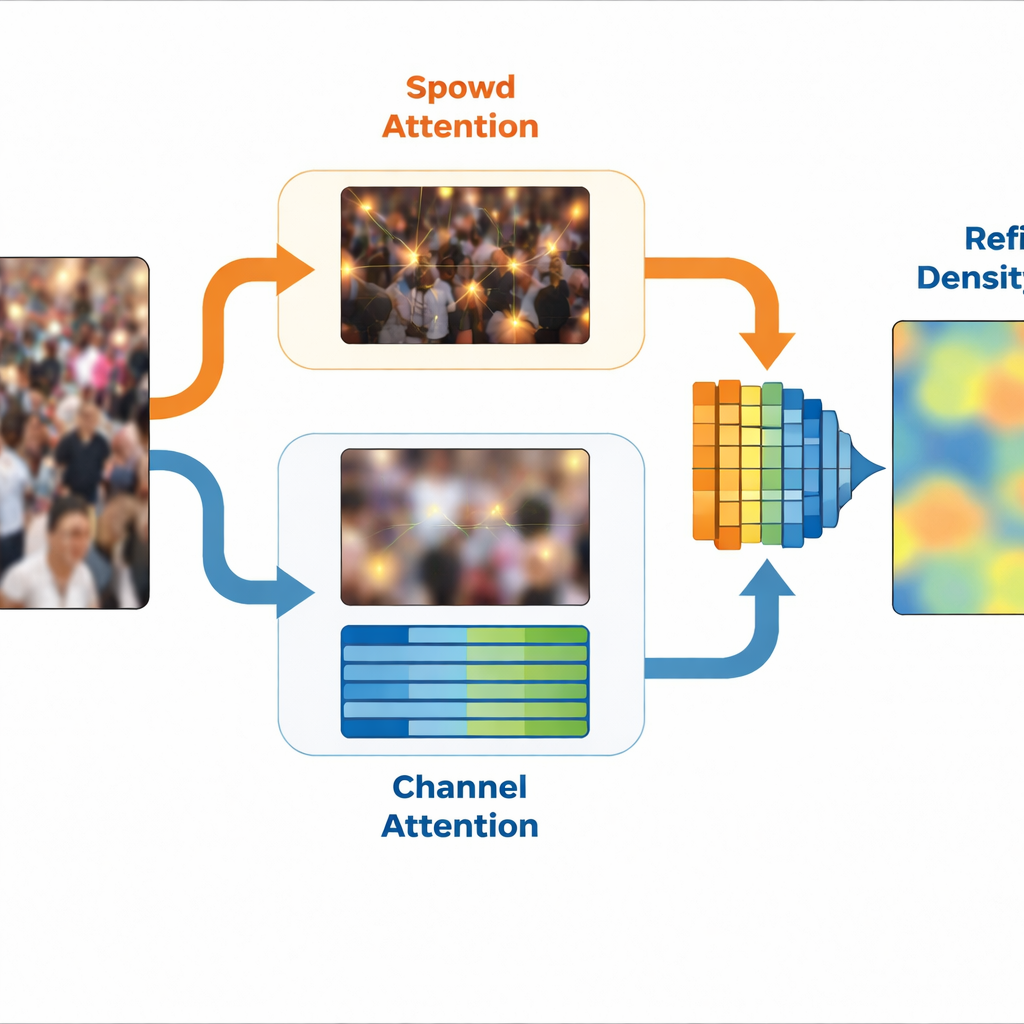
Utrzymanie uwagi w zaszumionym świecie
Rzeczywiste obrazy zawierają także rozpraszacze: odblaski, rozmycie ruchu czy zmiany oświetlenia mogą skierować model na mylące wzorce. Aby temu przeciwdziałać, SinCount wprowadza dwa dodatkowe rozwiązania. Maska normalizacji instancji porównuje, jak cechy reagują na oryginalny obraz i jego wersję poddaną augmentacji (na przykład z przesunięciem kolorów lub rozmyciem) i osłabia lokalizacje, które zmieniają się zbyt mocno, traktując je jako niepewne. Funkcja straty zgodności uwagi zachęca następnie system do skupiania się na podobnych regionach w obu wersjach obrazu, aby jego uwaga nie błądziła tylko dlatego, że wygląd nieznacznie się zmienił. Dodatkowe sygnały treningowe kierują ścieżkę wysokoczęstotliwościową, by lepiej odpowiadała rzeczywistym gęstościom tłumu, oraz ścieżkę niskoczęstotliwościową, by lepiej odróżniała obszary z tłumem od tła.
Co wyniki znaczą w praktyce
Naukowcy przetestowali SinCount na kilku wymagających publicznych zbiorach danych, obejmujących wypełnione stadiony, ulice miejskie oraz sceny nocne z rozmyciem i słabym światłem. Nie widząc w czasie treningu przykładów z docelowych scen, SinCount dorównuje lub przewyższa istniejące metody uogólniania z jednej domeny, często działając szybciej, ponieważ unika ciężkich modułów pamięci stosowanych w wcześniejszych konstrukcjach. Mówiąc prosto: system uczy się zliczać tłumy w jednym środowisku, a następnie radzi sobie dobrze po przeniesieniu do wielu innych, których nigdy wcześniej nie widział. Dla zarządców miast, organizatorów wydarzeń i służb bezpieczeństwa to krok w kierunku narzędzi monitorowania tłumów bardziej odpornych na nowe kamery, lokalizacje i zmienne warunki pogodowe — pomagający dostarczać wiarygodne liczby osób wtedy, gdy są najbardziej potrzebne.
Cytowanie: Song, L., Li, T., Cai, Z. et al. Fourier transform-based single domain generalization for crowd counting. Sci Rep 16, 11744 (2026). https://doi.org/10.1038/s41598-026-46286-3
Słowa kluczowe: zliczanie tłumów, uogólnianie domenowe, częstotliwość Fouriera, wzrok komputerowy, mapy gęstości