Clear Sky Science · de
Fourier-Transform-basierte Single-Domain-Generalisation für die Personenmengen-Zählung
Warum bessere Personen-Zählungen wichtig sind
Ob bei Musikfestivals und U‑Bahn-Stationen oder auf nassen Stadtstraßen bei Regen: Die grobe Kenntnis darüber, wie viele Menschen sich an einem Ort aufhalten, ist entscheidend für Sicherheitsplanung, Verkehrssteuerung und Notfallmaßnahmen. Heutige Computersysteme können aus Kamerabildern die Größe von Menschenmengen schätzen, versagen jedoch häufig, wenn sich die Bedingungen ändern – etwa wenn die Kamera versetzt wird, das Licht von Tag auf Nacht wechselt oder Nebel und Unschärfe Details verschleiern. Dieses Papier stellt SinCount vor, einen neuen Ansatz, der automatisierte Personen-Zählung in der unordentlichen, sich ständig verändernden Realität deutlich verlässlicher machen soll.
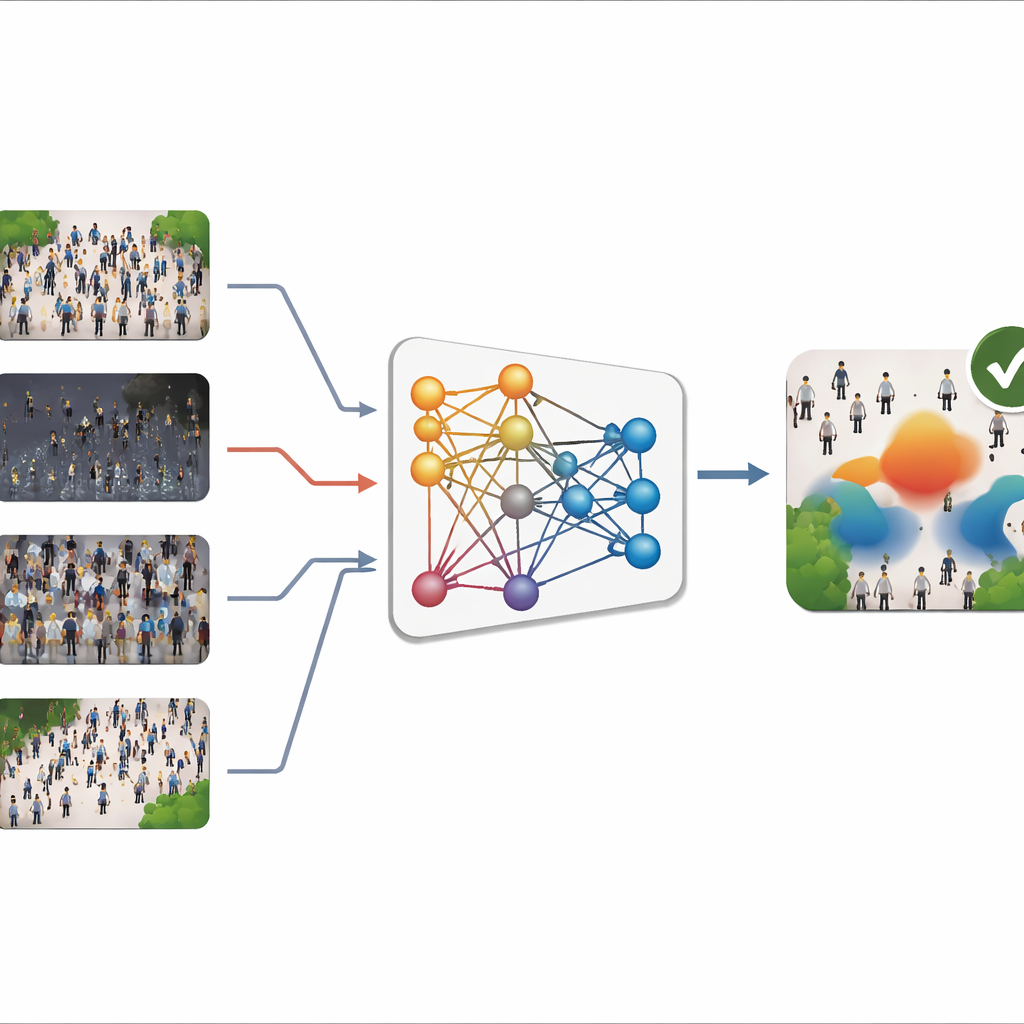
Das Problem wechselnder Szenen
Die meisten modernen Zähler für Menschenmengen nutzen Deep Learning, um ein Bild in eine „Dichtekarte“ zu verwandeln – eine Art Heatmap, die zeigt, wo sich Menschen befinden und wie eng sie gepackt sind. Die Summe dieser Karte ergibt die Gesamtzahl. Solche Systeme sind sehr genau, solange die Bilder, die sie im Einsatz sehen, den Trainingsbildern ähneln. In der Praxis variieren Szenen jedoch stark: Kameras blicken aus unterschiedlichen Winkeln, Menschenmengen reichen von spärlichen Gehsteigen bis zu überfüllten Stadien, und Wetter sowie Beleuchtung ändern sich von hellem Sonnenschein bis zu nebligen Nächten. Neue, gelabelte Bilder für jeden Einsatzort zu sammeln ist langsam und teuer, weil jede Person manuell markiert werden muss. Daher versagen Modelle, die in einem Umfeld trainiert wurden, oft beim Einsatz in einem anderen – ein Problem, das als „Domain Shift“ bekannt ist.
Menschenmengen im Frequenzraum betrachten
Die Autorinnen und Autoren gehen das Problem an, indem sie Bilder nicht nur als Pixel, sondern als Kombinationen von Frequenzen betrachten – im Sinne der Fourier-Transformation. Hochfrequente Komponenten heben scharfe Kanten und feine Details hervor, etwa die Konturen von Köpfen und Schultern. Niedrigfrequente Komponenten erfassen die grobe Struktur der Szene, etwa wo sich die Menschenansammlung im Allgemeinen befindet oder wie die Dichte in verschiedenen Bereichen verteilt ist. Das Team beobachtet, dass diese beiden Informationsarten sich naturgemäß für zwei unterschiedliche Aufgaben eignen: Detaillierte Frequenzhinweise sind am besten, um die Zahl der Personen in kleinen Bildausschnitten abzuschätzen, während glattere, niedrigfrequente Hinweise besser darin sind zu entscheiden, welche Bereiche tatsächlich Menschenmengen und welche Hintergrund sind.
Zwei arbeitsteilige Komponenten
Aufbauend auf dieser Idee verwendet SinCount ein zweigleisiges Design. Ein gemeinsamer Merkmalsextraktor verarbeitet zuerst ein Bild und teilt dann in einen Dichtezweig und einen Klassifikationszweig auf. Ein spezielles Modul, genannt Frequency-Specific Feature Extraction, trennt hoch- und niedrigfrequente Versionen der Szene und lernt kompakte interne Repräsentationen jeder Komponente. Der Dichtezweig erhält hochfrequente Führung durch einen räumlichen Aufmerksamkeitsblock, der Positionen hervorhebt, die wahrscheinlich Personen entsprechen, und so die entstehende Dichtekarte schärft. Derweil bekommt der Klassifikationszweig niedrigfrequente Führung durch kanalbasierte Aufmerksamkeit, die Merkmale für Menschenmengen verstärkt und irrelevanten Hintergrund unterdrückt. Zusammen erzeugen diese beiden Zweige eine verfeinerte Dichtekarte, die sich auf Bereiche mit Menschen konzentriert und leere oder verwirrende Regionen ignoriert.
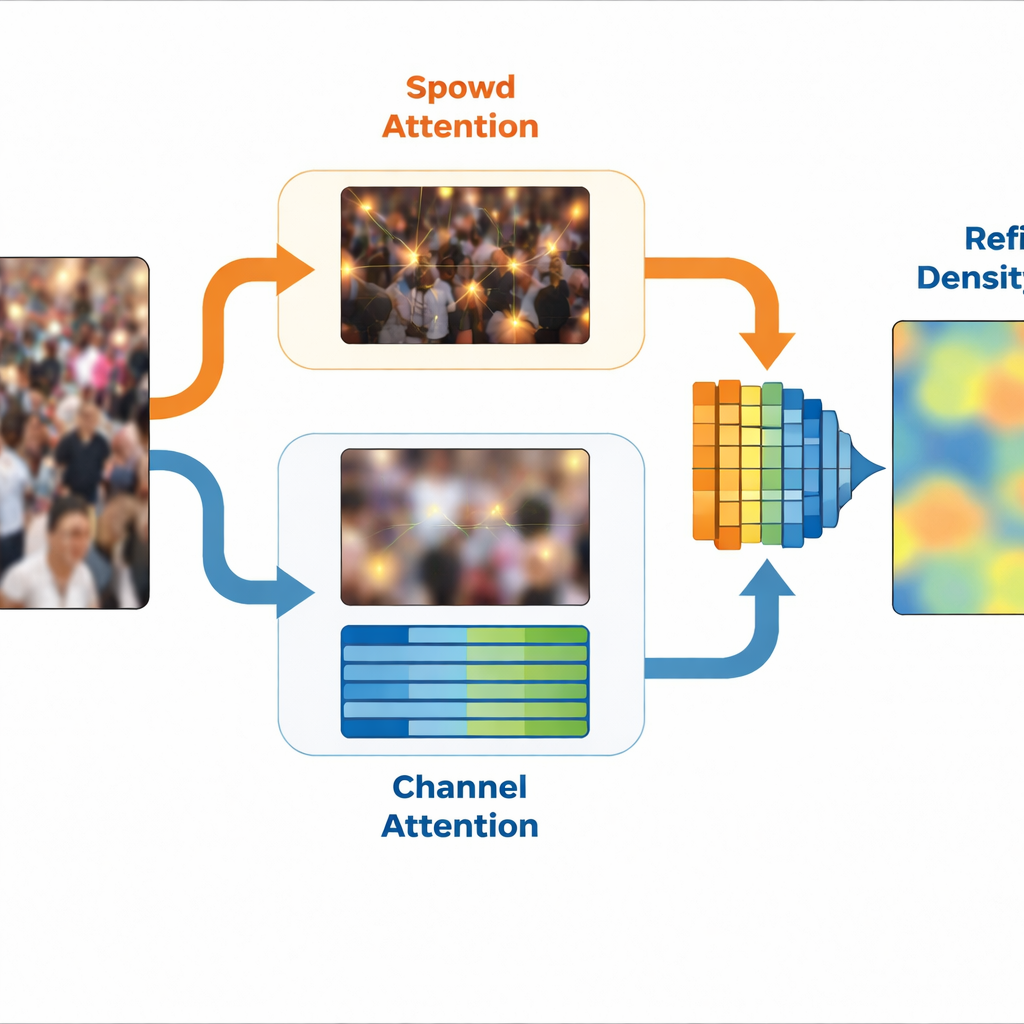
Fokus behalten in einer lauten Welt
Echte Bilder enthalten zudem Störfaktoren: Blendungen, Bewegungsunschärfe oder Lichtveränderungen können das Modell auf irreführende Muster lenken. Um dem entgegenzuwirken, ergänzt SinCount zwei weitere Ideen. Eine Instance-Normalization-Maske vergleicht, wie Merkmale auf das Originalbild und eine augmentierte Version (zum Beispiel mit Farb-Jitter oder Unschärfe) reagieren, und spielt Stellen herunter, die sich zu stark verändern, indem sie diese als unzuverlässig behandelt. Ein Attention-Consistency-Loss ermutigt das System außerdem dazu, in beiden Bildversionen ähnliche Regionen zu beachten, sodass sich sein Fokus nicht allein wegen einer leichten Erscheinungsänderung verschiebt. Zusätzliche Trainingssignale treiben den hochfrequenten Pfad dazu, besser mit den echten Personendichten übereinzustimmen, und den niedrigfrequenten Pfad dazu, besseren Unterschied zwischen Menschenmengen und Hintergrund zu lernen.
Was die Ergebnisse praktisch bedeuten
Die Forschenden testen SinCount auf mehreren herausfordernden öffentlichen Datensätzen, darunter volle Stadien, Stadtstraßen und nächtliche Szenen mit Unschärfe und wenig Licht. Ohne jemals Beispiele aus den Zielszenen während des Trainings zu sehen, erreicht SinCount Ergebnisse, die mit bestehenden Methoden zur Single-Domain-Generalisation vergleichbar sind oder diese übertreffen – oft mit schnellerer Verarbeitung, weil auf speicherintensive Module früherer Entwürfe verzichtet wird. Einfach gesagt: Das System lernt, Menschenmengen in einer Umgebung zu zählen, und leistet dann auch in vielen anderen, zuvor unbekannten Umgebungen solide Arbeit. Für Stadtverwaltungen, Veranstalter und Sicherheitsverantwortliche deutet dies auf Überwachungswerkzeuge hin, die widerstandsfähiger gegenüber neuen Kameras, neuen Orten und wechselndem Wetter sind – und zuverlässige Kopfzählungen liefern, wenn es darauf ankommt.
Zitation: Song, L., Li, T., Cai, Z. et al. Fourier transform-based single domain generalization for crowd counting. Sci Rep 16, 11744 (2026). https://doi.org/10.1038/s41598-026-46286-3
Schlüsselwörter: Personenzählung, Domain-Generalisation, Fourier-Frequenz, Computer Vision, Dichtekarten