Clear Sky Science · en
Fourier transform-based single domain generalization for crowd counting
Why Smarter Crowd Counts Matter
From music festivals and subway stations to city streets on a rainy night, knowing roughly how many people are in a space is vital for safety planning, traffic control, and emergency response. Today’s computer systems can estimate crowd sizes from camera footage, but they often fail when conditions change—say, when a camera is moved, the lighting shifts from day to night, or fog and blur obscure details. This paper introduces SinCount, a new approach that aims to make automated crowd counting far more dependable in the messy, ever-changing real world.
The Trouble with Changing Scenes
Most modern crowd-counters use deep learning to turn an image into a “density map,” a kind of heat pattern showing where people are and how tightly they are packed. Summing this map yields the total count. These systems can be very accurate when the images they see during operation look like the ones they were trained on. In practice, however, real scenes vary wildly: cameras point at different angles, crowds range from sparse sidewalks to packed stadiums, and weather and lighting can change from bright sunshine to foggy nights. Collecting new labeled images for every new site is slow and expensive, especially because each person must be marked by hand. As a result, models trained in one setting often falter when moved to another, a problem known as “domain shift.”
Looking at Crowds Through Frequencies
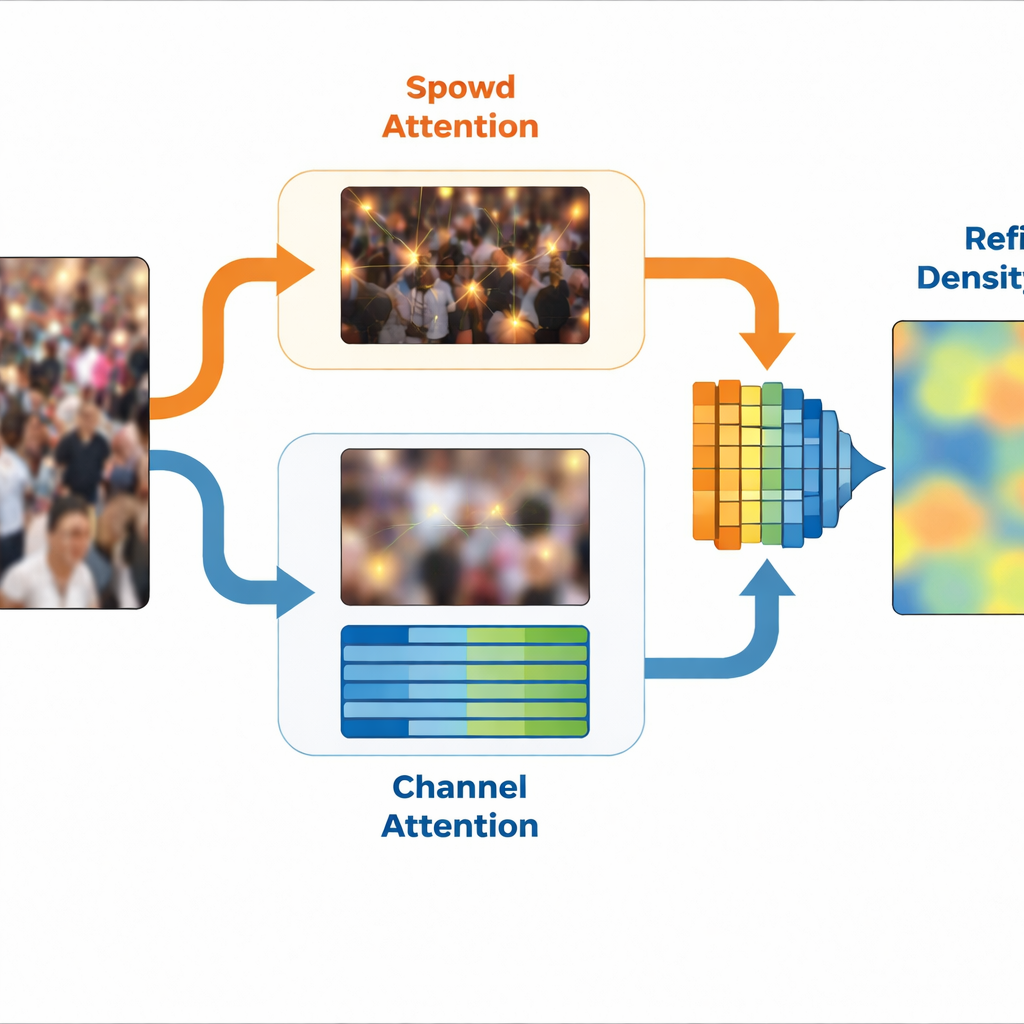
The authors tackle this problem by viewing images not just as pixels, but as combinations of frequencies, in the sense used in the Fourier transform. High-frequency parts highlight sharp edges and fine details, such as the outlines of heads and shoulders. Low-frequency parts capture the broad layout of the scene, like where the crowd is generally located or how dense it is in different regions. The team observes that these two kinds of information naturally suit two different tasks: detailed frequency cues are best for estimating how many people are in each small patch, while smoother, low-frequency cues are better for deciding which areas actually contain crowds versus background.
Two Working Parts that Share the Load
Building on this idea, SinCount uses a dual-branch design. A shared feature extractor first processes an image, then splits into a density branch and a classification branch. A special module, called Frequency-Specific Feature Extraction, separates out high-frequency and low-frequency versions of the scene and learns compact internal representations of each. The density branch receives high-frequency guidance through a spatial attention block that highlights positions likely to correspond to people, sharpening the eventual density map. Meanwhile, the classification branch receives low-frequency guidance through channel-based attention that boosts features linked to crowd regions and suppresses irrelevant background. Together, these two branches produce a refined density map that zeroes in on crowd areas while ignoring empty or confusing regions.
Keeping Focus in a Noisy World
Real images also contain distractions: glare, motion blur, or lighting changes can nudge the model toward misleading patterns. To guard against this, SinCount adds two further ideas. An instance normalization mask compares how features respond to an original image and an augmented version (for example, one that has been color-jittered or blurred) and downplays locations that change too much, treating them as unreliable. An attention consistency loss then encourages the system to look at similar regions in both versions of the image, so its focus does not wander just because the appearance has shifted slightly. Extra training signals push the high-frequency path to better match true crowd densities and the low-frequency path to better match crowd-versus-background regions.
What the Results Mean in Practice
The researchers test SinCount on several challenging public datasets, including packed stadiums, city streets, and nighttime scenes with blur and low light. Without ever seeing examples from the target scenes during training, SinCount matches or outperforms existing single-domain generalization methods, often with faster processing because it avoids heavy memory modules used by earlier designs. In plain terms, the system learns to count crowds from one environment and then does a solid job when dropped into many others it has never seen. For city managers, event organizers, and safety officials, this points toward crowd monitoring tools that are more resilient to new cameras, new locations, and shifting weather—helping deliver reliable head counts when it matters most.
Citation: Song, L., Li, T., Cai, Z. et al. Fourier transform-based single domain generalization for crowd counting. Sci Rep 16, 11744 (2026). https://doi.org/10.1038/s41598-026-46286-3
Keywords: crowd counting, domain generalization, Fourier frequency, computer vision, density maps