Clear Sky Science · it
Generalizzazione in un solo dominio basata sulla trasformata di Fourier per il conteggio della folla
Perché contare meglio le folle è importante
Dai festival musicali alle stazioni della metropolitana fino alle strade cittadine in una notte di pioggia, avere una stima approssimativa del numero di persone in uno spazio è fondamentale per la pianificazione della sicurezza, il controllo del traffico e la risposta alle emergenze. I sistemi automatici odierni possono stimare le dimensioni delle folle da filmati delle telecamere, ma spesso falliscono quando cambiano le condizioni — ad esempio se una telecamera viene spostata, l’illuminazione passa dal giorno alla notte o nebbia e sfocatura nascondono i dettagli. Questo articolo presenta SinCount, un nuovo approccio che punta a rendere il conteggio automatico delle folle molto più affidabile nel mondo reale, caotico e in continua evoluzione.
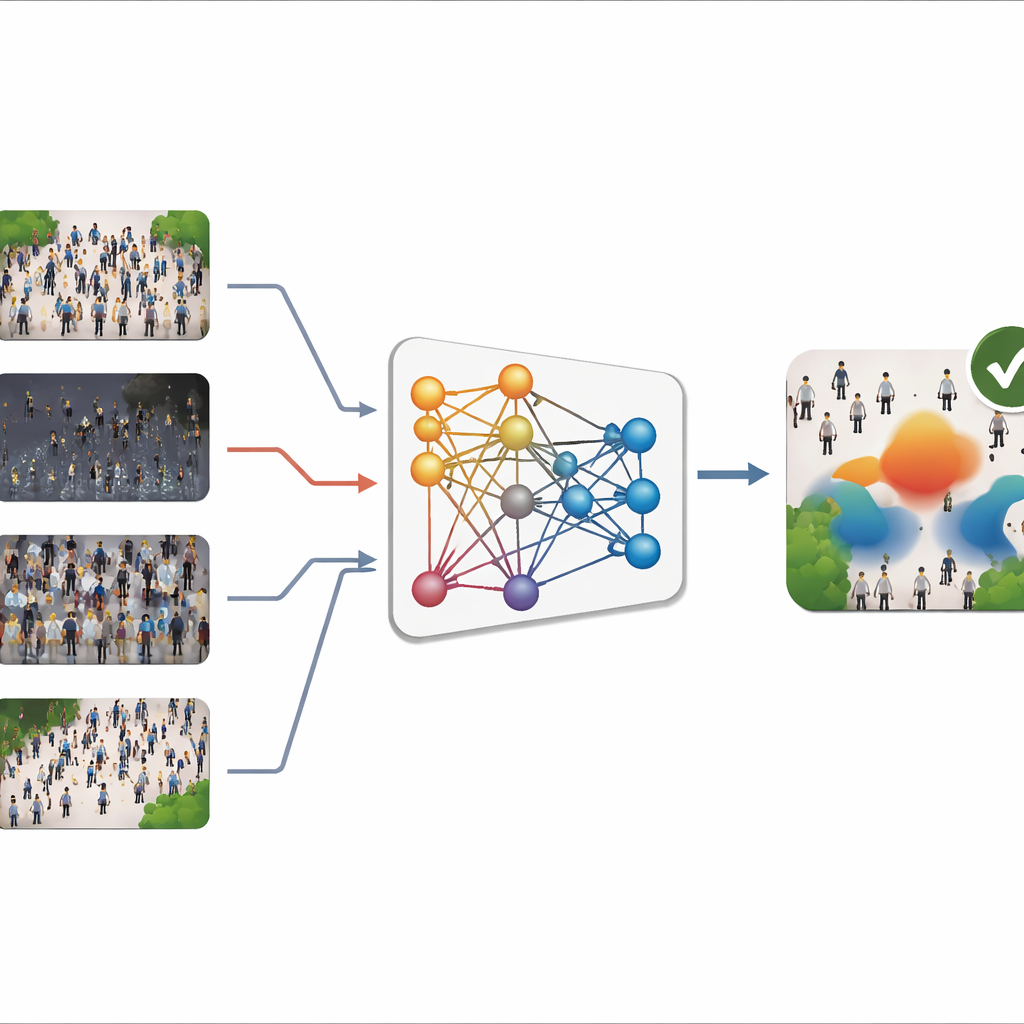
Il problema delle scene che cambiano
La maggior parte dei contatori di folle moderni usa il deep learning per trasformare un’immagine in una «mappa di densità», una sorta di modello a calore che mostra dove si trovano le persone e quanto sono concentrate. La somma di questa mappa fornisce il conteggio totale. Questi sistemi possono essere molto precisi quando le immagini operative assomigliano a quelle usate per l’addestramento. In pratica, però, le scene reali variano moltissimo: le telecamere puntano con angolazioni diverse, le folle spaziano da marciapiedi scarsi fino a stadi pieni, e il meteo e l’illuminazione cambiano dalla piena luce solare a notti nebbiose. Raccogliere nuove immagini etichettate per ogni nuovo sito è lento e costoso, soprattutto perché ogni persona deve essere segnala manualmente. Di conseguenza, i modelli addestrati in un contesto spesso vacillano quando spostati in un altro, un problema noto come «shift di dominio».
Guardare le folle attraverso le frequenze
Gli autori affrontano questo problema considerando le immagini non solo come pixel, ma come combinazioni di frequenze, nel senso usato dalla trasformata di Fourier. Le componenti ad alta frequenza mettono in evidenza bordi netti e dettagli fini, come i contorni di teste e spalle. Le componenti a bassa frequenza catturano la disposizione generale della scena, per esempio dove la folla è posizionata in termini ampi o quanto è densa in diverse aree. Il team osserva che questi due tipi di informazioni si prestano naturalmente a compiti differenti: gli indizi di frequenza dettagliati sono più adatti a stimare quante persone ci sono in ciascuna piccola porzione, mentre gli indizi più morbidi a bassa frequenza sono migliori per decidere quali aree contengono effettivamente folle rispetto allo sfondo.
Due componenti operative che si condividono il lavoro
Sulla base di questa idea, SinCount usa un design a doppio ramo. Un estrattore di caratteristiche condiviso elabora prima l’immagine, poi si divide in un ramo di densità e un ramo di classificazione. Un modulo speciale, chiamato Estrazione di Caratteristiche Specifiche per Frequenza, separa versioni ad alta e bassa frequenza della scena e apprende rappresentazioni compatte interne di ciascuna. Il ramo di densità riceve indicazioni ad alta frequenza tramite un blocco di attenzione spaziale che evidenzia le posizioni probabilmente corrispondenti alle persone, affinando la mappa di densità finale. Nel frattempo, il ramo di classificazione riceve indicazioni a bassa frequenza tramite attenzione basata sui canali che potenzia le caratteristiche legate alle regioni con folla e sopprime lo sfondo irrilevante. Insieme, questi due rami producono una mappa di densità raffinata che si concentra sulle aree con folla ignorando le regioni vuote o fuorvianti.
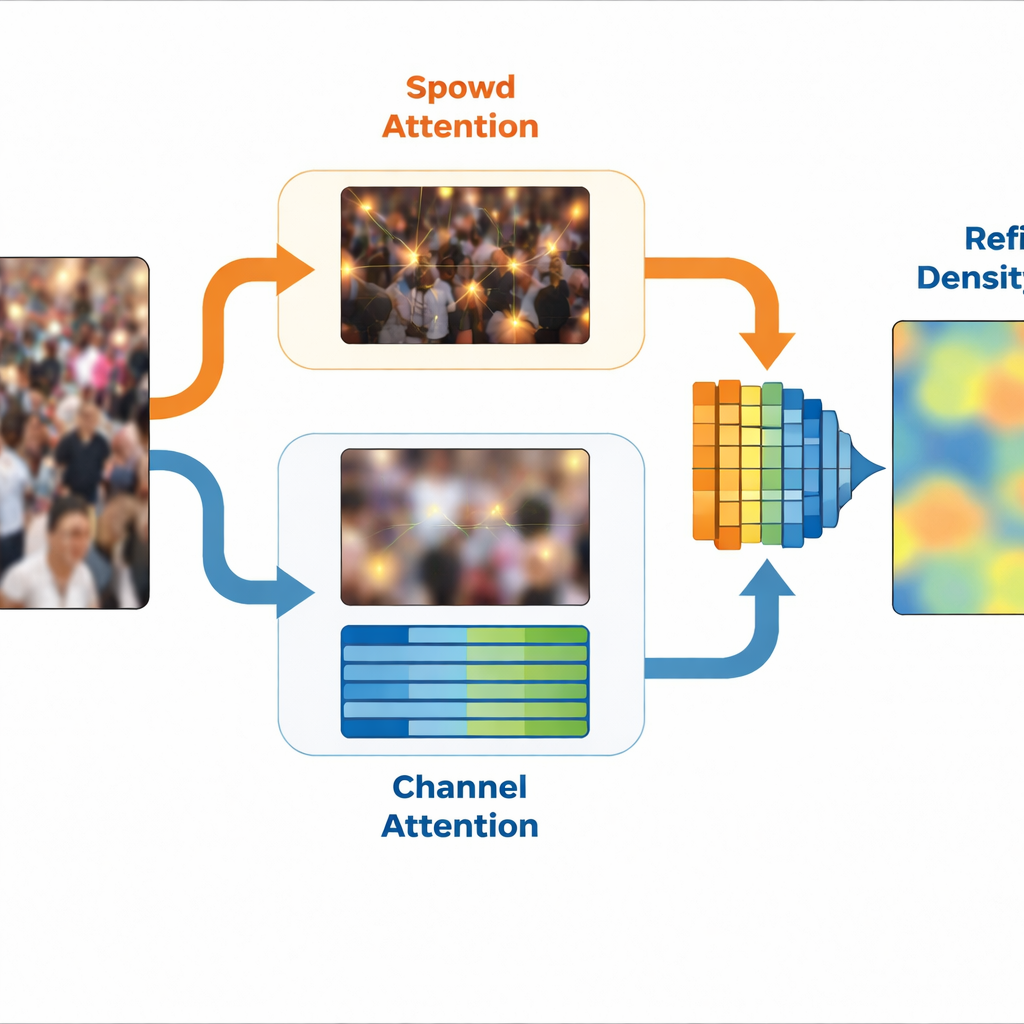
Mantenere la concentrazione in un mondo rumoroso
Le immagini reali contengono anche distrazioni: bagliori, sfocature da movimento o cambiamenti di illuminazione possono indurre il modello verso pattern fuorvianti. Per proteggersi da ciò, SinCount aggiunge altre due idee. Una maschera di normalizzazione per istanze confronta come le caratteristiche rispondono all’immagine originale e a una versione aumentata (per esempio una con variazioni di colore o sfocatura) e attenua le posizioni che cambiano troppo, trattandole come poco affidabili. Una perdita di coerenza dell’attenzione poi incoraggia il sistema a guardare regioni simili in entrambe le versioni dell’immagine, così che il suo focus non vaghi solo perché l’aspetto è cambiato leggermente. Segnali di addestramento aggiuntivi spingono il percorso ad alta frequenza a corrispondere meglio alle densità reali della folla e il percorso a bassa frequenza a distinguere meglio tra zona di folla e sfondo.
Cosa significano i risultati nella pratica
I ricercatori testano SinCount su diversi dataset pubblici impegnativi, inclusi stadi affollati, strade cittadine e scene notturne con sfocatura e scarsa illuminazione. Senza aver mai visto esempi delle scene target durante l’addestramento, SinCount eguaglia o supera i metodi esistenti di generalizzazione in un solo dominio, spesso con una velocità superiore perché evita moduli di memoria pesanti usati da progetti precedenti. In termini pratici, il sistema impara a contare le folle in un ambiente e poi svolge un buon lavoro quando viene collocato in molti altri ambienti mai incontrati prima. Per i gestori urbani, gli organizzatori di eventi e gli addetti alla sicurezza, questo indica strumenti di monitoraggio delle folle più resilienti a nuove telecamere, nuove ubicazioni e cambiamenti meteorologici — aiutando a fornire conteggi affidabili quando è più importante.
Citazione: Song, L., Li, T., Cai, Z. et al. Fourier transform-based single domain generalization for crowd counting. Sci Rep 16, 11744 (2026). https://doi.org/10.1038/s41598-026-46286-3
Parole chiave: conteggio della folla, generalizzazione del dominio, frequenza di Fourier, visione artificiale, mappe di densità