Clear Sky Science · fr
Généralisation mono-domaine basée sur la transformée de Fourier pour le comptage de foule
Pourquoi des comptages de foule plus intelligents comptent
Des festivals de musique et des stations de métro aux rues de la ville par une nuit pluvieuse, connaître approximativement le nombre de personnes présentes dans un espace est essentiel pour la planification de la sécurité, la gestion du trafic et les interventions d’urgence. Les systèmes informatiques actuels peuvent estimer la taille des foules à partir d’images vidéo, mais ils échouent souvent lorsque les conditions changent — par exemple lorsque la caméra est déplacée, que l’éclairage passe du jour à la nuit, ou que le brouillard et le flou masquent des détails. Cet article présente SinCount, une nouvelle approche visant à rendre le comptage automatisé des foules beaucoup plus fiable dans le monde réel, chaotique et en perpétuelle évolution.
Le problème des scènes changeantes
La plupart des estimateurs de foule modernes utilisent l’apprentissage profond pour transformer une image en une « carte de densité », une sorte de carte thermique indiquant où se trouvent les personnes et leur densité locale. La somme de cette carte donne le nombre total. Ces systèmes peuvent être très précis lorsque les images traitées en exploitation ressemblent à celles utilisées lors de l’entraînement. En pratique, toutefois, les scènes réelles varient énormément : les caméras pointent sous des angles différents, les foules vont du trottoir clairsemé au stade bondé, et la météo ou l’éclairage peuvent passer d’un soleil éclatant à des nuits brumeuses. Collecter de nouvelles images annotées pour chaque site est long et coûteux, surtout parce que chaque personne doit être marquée manuellement. En conséquence, les modèles entraînés dans un contexte donné échouent souvent lorsqu’on les déplace ailleurs, un problème connu sous le nom de « décalage de domaine ».
Observer les foules à travers les fréquences
Les auteurs abordent ce problème en considérant les images non seulement comme des pixels, mais comme des combinaisons de fréquences, au sens de la transformée de Fourier. Les composantes haute fréquence mettent en évidence les arêtes nettes et les détails fins, comme le contour des têtes et des épaules. Les composantes basse fréquence capturent la configuration générale de la scène, par exemple où la foule est globalement située ou comment la densité varie selon les régions. L’équipe observe que ces deux types d’informations conviennent naturellement à deux tâches différentes : les indices haute fréquence sont les plus utiles pour estimer le nombre de personnes dans chaque petite zone, tandis que les indices basse fréquence, plus lisses, sont meilleurs pour distinguer les zones effectivement peuplées du fond.
Deux modules complémentaires qui se partagent la charge
Partant de cette idée, SinCount adopte une architecture à double branche. Un extracteur de caractéristiques partagé traite d’abord l’image, puis se scinde en une branche de densité et une branche de classification. Un module spécifique, appelé Extraction de Caractéristiques Spécifiques en Fréquence, sépare des versions haute fréquence et basse fréquence de la scène et apprend des représentations internes compactes pour chacune. La branche de densité reçoit un guidage haute fréquence via un bloc d’attention spatiale qui met en valeur les positions susceptibles de correspondre à des personnes, affinant ainsi la carte de densité finale. Dans le même temps, la branche de classification bénéficie d’un guidage basse fréquence via une attention par canal qui valorise les caractéristiques liées aux régions peuplées et supprime les arrière-plans non pertinents. Ensemble, ces deux branches produisent une carte de densité affinée qui se concentre sur les zones de foule tout en ignorant les régions vides ou confuses.
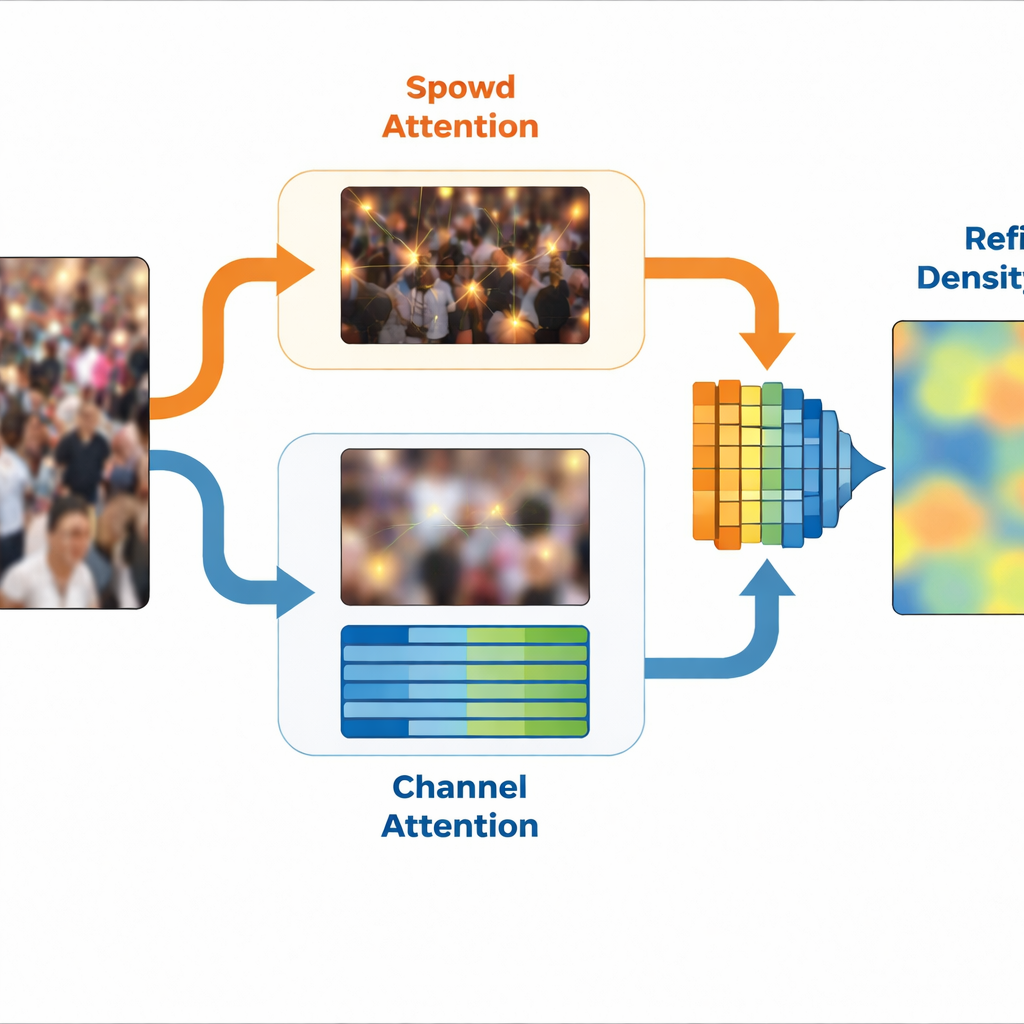
Conserver la focalisation dans un monde bruyant
Les images réelles contiennent aussi des distractions : éblouissement, flou de mouvement ou variations d’éclairage peuvent amener le modèle à se focaliser sur des motifs trompeurs. Pour se prémunir contre cela, SinCount ajoute deux idées complémentaires. Un masque de normalisation d’instance compare la réponse des caractéristiques entre une image originale et une version augmentée (par exemple colorée différemment ou floutée) et atténue les emplacements qui changent trop, les considérant comme peu fiables. Une perte de cohérence d’attention encourage ensuite le système à observer des régions similaires dans les deux versions de l’image, afin que son attention ne dérive pas simplement parce que l’apparence a légèrement changé. Des signaux d’entraînement supplémentaires poussent la voie haute fréquence à mieux correspondre aux densités réelles de foule et la voie basse fréquence à mieux distinguer foule et arrière-plan.
Ce que signifient les résultats en pratique
Les chercheurs évaluent SinCount sur plusieurs jeux de données publics difficiles, incluant des stades bondés, des rues urbaines et des scènes nocturnes avec flou et faible luminosité. Sans jamais voir d’exemples des scènes cibles pendant l’entraînement, SinCount égalise ou surpasse les méthodes existantes de généralisation mono-domaine, souvent avec un traitement plus rapide car il évite les modules mémoire lourds utilisés par des conceptions antérieures. En termes simples, le système apprend à compter les foules dans un environnement puis s’en sort bien lorsqu’on le déplace dans bien d’autres qu’il n’a jamais vus. Pour les gestionnaires urbains, les organisateurs d’événements et les responsables de la sécurité, cela ouvre la voie à des outils de surveillance des foules plus résilients face à de nouvelles caméras, de nouveaux lieux et des conditions météorologiques changeantes — permettant d’obtenir des comptages fiables quand cela compte le plus.
Citation: Song, L., Li, T., Cai, Z. et al. Fourier transform-based single domain generalization for crowd counting. Sci Rep 16, 11744 (2026). https://doi.org/10.1038/s41598-026-46286-3
Mots-clés: comptage de foule, généralisation de domaine, fréquence de Fourier, vision par ordinateur, cartes de densité