Clear Sky Science · pt
Método leve de super-resolução baseado em processamento de espalhamento e interação de características
Imagens mais nítidas a partir de fotos borradas
Qualquer pessoa que já deu zoom em uma foto de smartphone conhece a frustração de ver detalhes blocados e borrados. De câmeras de segurança a exames médicos e imagens de satélite, muitas imagens importantes sofrem do mesmo problema. Este artigo apresenta uma nova forma de transformar imagens de baixa resolução em versões mais claras, com o objetivo de recuperar bordas e texturas nítidas ao mesmo tempo em que mantém o custo computacional baixo o suficiente para dispositivos do mundo real.
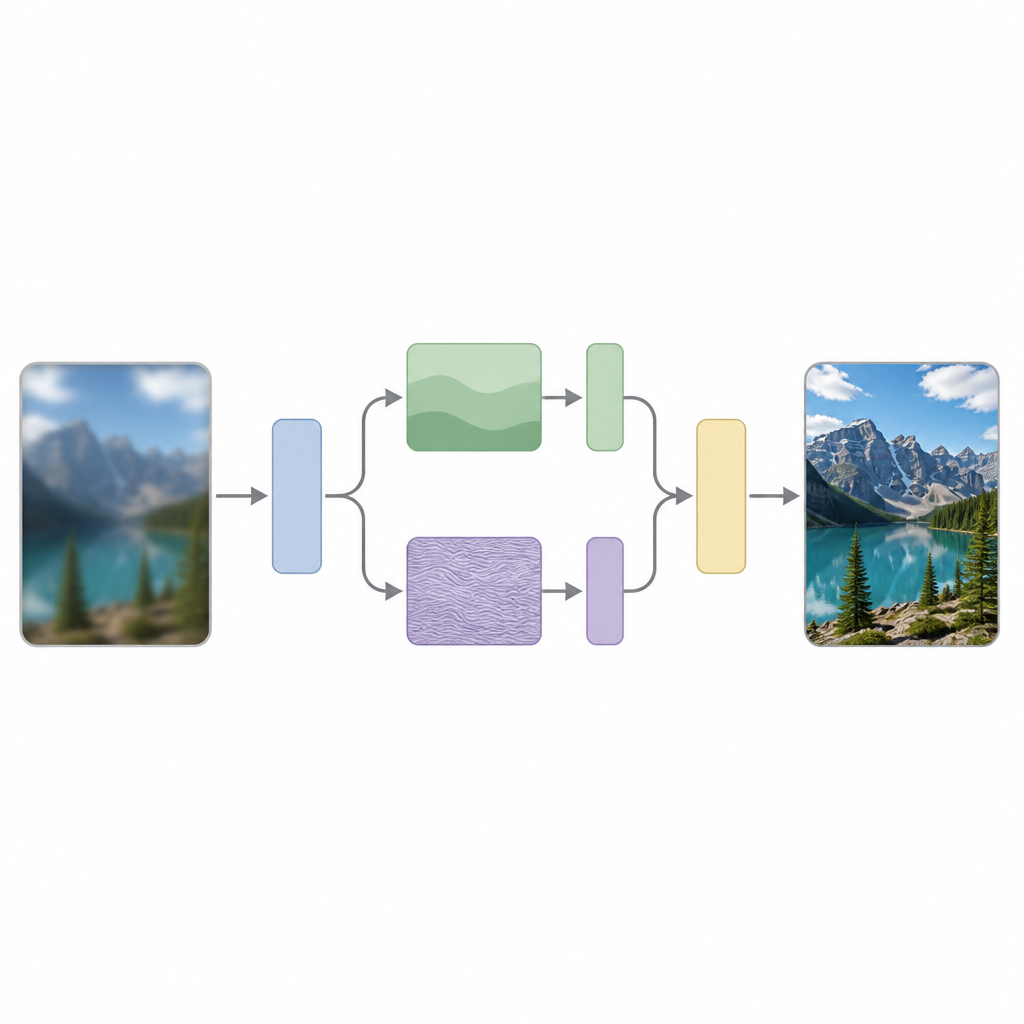
Por que aumentar o detalhe é tão difícil
Super-resolução de imagem é a tarefa de reconstruir uma imagem de alta resolução a partir de uma entrada de baixa resolução. É importante para fotografia do dia a dia, mas também para vigilância por vídeo, imagens médicas e sensoriamento remoto. Sistemas clássicos de aprendizado profundo baseados em redes neurais convolucionais conseguem melhorar imagens, mas geralmente analisam apenas pequenas vizinhanças de pixels e frequentemente deixam de capturar como partes distantes da imagem se relacionam. Modelos mais recentes baseados em Transformers capturam essas relações de longo alcance, porém são pesados para executar e ainda têm dificuldade em reconstruir os detalhes mais finos, como texturas minúsculas e bordas muito finas, especialmente em dispositivos com poder computacional limitado.
Separando a imagem em mudanças lentas e rápidas
Os autores argumentam que uma razão-chave para essa dificuldade é que a maioria dos modelos trata todas as partes da imagem da mesma forma, embora imagens contenham naturalmente uma mistura de mudanças lentas, como céus suaves, e mudanças rápidas, como bordas nítidas ou padrões repetitivos. O método deles, chamado Scattering Processing and Feature Interaction (SPFI), aborda isso separando explicitamente as características de entrada em componentes de baixa frequência, que descrevem a estrutura ampla, e componentes de alta frequência, que codificam detalhes finos. Eles usam uma ferramenta matemática conhecida como Transformada Wavelet Complexa Dual-Tree para realizar essa separação de forma menos sensível a pequenos deslocamentos na imagem e melhor na detecção de direções, como linhas e arestas.

Tratamento especial para detalhes finos sem custo elevado
Uma vez que a informação da imagem é dividida, o SPFI processa as partes suaves e detalhadas de forma diferente. A informação de baixa frequência, que é compacta, é tratada com um método de mistura direto para capturar a estrutura global. Para a parte de alta frequência, uma abordagem direta exigiria um número enorme de cálculos porque tentaria relacionar cada pixel com todos os outros. Para evitar isso, os autores projetam um Método de Mistura Einstein que reestrutura os dados e mistura canais de modo a preservar as interações de detalhe importantes enquanto reduz drasticamente o número de operações. Na prática, o modelo presta atenção extra a bordas e texturas sem ficar grande ou lento demais.
Reunindo escalas de forma eficiente
Outro desafio para uma reconstrução nítida é que informação útil aparece em múltiplas escalas, desde padrões minúsculos até formas amplas. A atenção padrão de Transformers trata todos os tokens em uma única escala, o que é tanto custoso quanto limitado. O SPFI introduz um bloco de Integração Cross-token que cria várias versões das características em diferentes escalas usando convoluções separáveis por profundidade, uma forma leve de filtragem. Esses fluxos multiescala interagem e são recombinados antes da etapa de atenção, de modo que o modelo pode aproveitar tanto o detalhe local quanto o contexto global enquanto reduz o trabalho que o mecanismo de atenção precisa fazer. Esse desenho ajuda a rede a focar nas interações mais relevantes sem desperdiçar computação.
Melhor qualidade, resultados mais rápidos, com algumas ressalvas
Em testes em benchmarks padrão de imagem, o SPFI produziu reconstruções de qualidade superior em comparação com uma série de métodos recentes de super-resolução, incluindo vários baseados em Transformers, ao mesmo tempo em que usou menos operações de ponto flutuante. Ele alcançou taxas de pico sinal-ruído ligeiramente maiores e melhores pontuações de similaridade estrutural, e rodou mais rápido durante a inferência, tornando-se mais adequado para uso quase em tempo real. Comparações visuais mostram que o SPFI recupera fachadas de prédios e outras texturas com menos artefatos borrados, e também se mostra relativamente robusto quando as imagens de entrada contêm ruído ou estão degradadas de maneiras ligeiramente diferentes do esperado. No entanto, os autores observam que detalhes muito pequenos e irregulares, como textos minúsculos, continuam desafiadores, sugerindo que uma forma fixa de separar frequências pode não servir para todos os tipos de padrões.
O que isso significa para futuras ferramentas de imagem
Para um público não especialista, a principal mensagem é que os autores encontraram uma forma de tornar imagens mais nítidas separando primeiro regiões suaves de detalhes finos e então permitindo que essas partes interajam de forma eficiente através das escalas. O método SPFI mostra que combinar processamento sensível à frequência com mistura cuidadosa de características pode produzir imagens mais claras com menor custo computacional. Embora não recupere perfeitamente todo tipo de detalhe, especialmente textos intrincados, ele aponta para sistemas de super-resolução mais práticos que poderiam rodar em hardware cotidiano e melhorar a clareza de imagens usadas em ciência, medicina, segurança e além.
Citação: Zheng, X., Chen, Z. & Huang, D. Lightweight super-resolution method based on scattering processing and feature interaction. Sci Rep 16, 15018 (2026). https://doi.org/10.1038/s41598-026-44351-5
Palavras-chave: super-resolução de imagem, aprendizado profundo, modelos transformer, decomposição de frequência, modelos de visão eficientes