Clear Sky Science · pl
Lekka metoda super-rozdzielczości oparta na przetwarzaniu rozpraszającym i interakcji cech
Ostroższe obrazy z rozmytych zdjęć
Każdy, kto powiększał zdjęcie ze smartfona, zna rozczarowanie wynikające z blokowych, rozmytych detali. Od kamer bezpieczeństwa po skany medyczne i zdjęcia satelitarne — wiele istotnych obrazów cierpi z tego samego powodu. Artykuł przedstawia nowy sposób przekształcania obrazów niskiej rozdzielczości w wyraźniejsze, mający na celu odzyskanie ostrych krawędzi i tekstur przy jednoczesnym utrzymaniu kosztu obliczeniowego na poziomie dopuszczalnym dla urządzeń rzeczywistych.
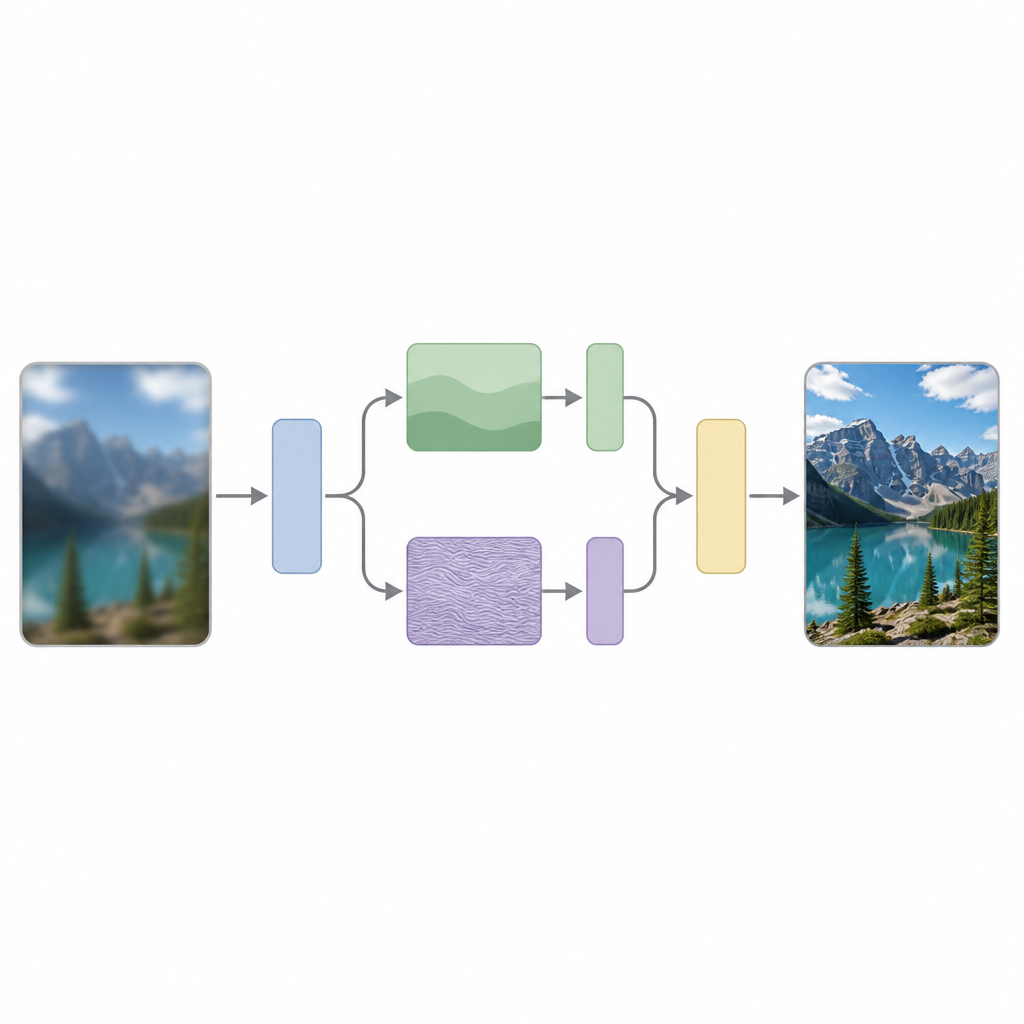
Dlaczego zwiększanie szczegółów jest takie trudne
Super-rozdzielczość obrazu to zadanie rekonstrukcji obrazu o wysokiej rozdzielczości z wejścia o niskiej rozdzielczości. Ma znaczenie w fotografii codziennej, ale także w nadzorze wideo, obrazowaniu medycznym i teledetekcji. Klasyczne systemy uczenia głębokiego oparte na sieciach konwolucyjnych potrafią poprawiać obrazy, jednak skupiają się głównie na małych sąsiedztwach pikseli i często pomijają relacje między odległymi fragmentami obrazu. Nowsze modele oparte na Transformerach wychwytują te długozasięgowe zależności, ale są kosztowne w uruchomieniu i wciąż mają trudności z odtworzeniem najdrobniejszych detali, takich jak drobne tekstury czy cienkie krawędzie, szczególnie na urządzeniach o ograniczonej mocy obliczeniowej.
Rozdzielanie obrazu na wolne i szybkie zmiany
Autorzy argumentują, że kluczowym powodem tych trudności jest to, że większość modeli traktuje wszystkie części obrazu tak samo, mimo że obrazy naturalnie zawierają mieszankę powolnych zmian, takich jak gładkie niebo, oraz szybkich zmian, jak ostre krawędzie czy powtarzalne wzory. Ich metoda, nazwana Scattering Processing and Feature Interaction (SPFI), zajmuje się tym, jawnie rozdzielając cechy wejściowe na składowe niskoczęstotliwościowe opisujące ogólną strukturę oraz składowe wysokoczęstotliwościowe kodujące drobne detale. Do wykonania tego podziału używają matematycznego narzędzia znanego jako Dual-Tree Complex Wavelet Transform, które jest mniej wrażliwe na drobne przesunięcia w obrazie i lepiej wychwytuje kierunki, takie jak linie i krawędzie.

Szczególne traktowanie drobnych detali bez dużych kosztów
Po rozdzieleniu informacji obrazowych SPFI przetwarza części gładkie i szczegółowe inaczej. Informacje niskoczęstotliwościowe, które są zwarte, są obsługiwane prostą metodą mieszania w celu uchwycenia globalnej struktury. Dla części wysokoczęstotliwościowej bezpośrednie podejście wymagałoby ogromnej liczby obliczeń, ponieważ próbowałoby powiązać każdy piksel z każdym innym. Aby tego uniknąć, autorzy projektują Einstein Mixing Method, która sprytnie przekształca dane i miesza kanały w sposób zachowujący istotne interakcje detali przy znacznym zmniejszeniu liczby operacji. W praktyce model poświęca dodatkową uwagę krawędziom i teksturom, nie stając się przy tym zbyt duży ani wolny.
Efektywne łączenie skal
Innym wyzwaniem dla ostrej rekonstrukcji jest to, że użyteczne informacje pojawiają się na wielu skalach — od drobnych wzorów po szerokie kształty. Standardowa uwaga w Transformerze traktuje wszystkie tokeny w jednej skali, co jest zarówno kosztowne, jak i ograniczone. SPFI wprowadza blok Cross-token Integration, który tworzy kilka wersji cech w różnych skalach za pomocą konwolucji separowalnych głębokościowo, lekkiej formy filtracji. Te wieloskalowe strumienie oddziałują ze sobą i są ponownie łączone przed etapem uwagi, dzięki czemu model może wykorzystywać zarówno lokalne detale, jak i kontekst globalny, zmniejszając przy tym obciążenie mechanizmu uwagi. Projekt ten pomaga sieci skupić się na najbardziej istotnych interakcjach bez tracenia zasobów obliczeniowych.
Lepsza jakość, szybsze wyniki, z pewnymi zastrzeżeniami
W testach na standardowych benchmarkach obrazu SPFI dało lepsze rekonstrukcje niż szereg niedawnych metod super-rozdzielczości, w tym kilka opartych na Transformerach, przy jednoczesnym wykorzystaniu mniejszej liczby operacji zmiennoprzecinkowych. Uzyskało nieznacznie wyższe wartości stosunku sygnału do szumu (PSNR) i lepsze wskaźniki strukturalnego podobieństwa (SSIM), a podczas inferencji działało szybciej, co czyni je bardziej odpowiednim do zastosowań bliskich rzeczywistemu czasowi. Porównania wizualne pokazują, że SPFI odtwarza fasady budynków i inne tekstury z mniejszą liczbą rozmytych artefaktów, a także okazuje się stosunkowo odporne, gdy obrazy wejściowe zawierają szum lub są nieco inaczej zdegradowane niż oczekiwano. Autorzy zauważają jednak, że bardzo małe, nieregularne detale, takie jak drobny tekst, wciąż pozostają wyzwaniem, co sugeruje, że stały sposób rozdzielania częstotliwości może nie pasować do wszystkich typów wzorców.
Co to oznacza dla przyszłych narzędzi obrazowania
Dla osoby niebędącej specjalistą główne przesłanie jest takie, że autorzy znaleźli sposób na wyostrzenie obrazów przez najpierw oddzielenie obszarów gładkich od drobnych detali, a następnie umożliwienie efektywnej interakcji tych części na różnych skalach. Ich metoda SPFI pokazuje, że łączenie przetwarzania świadomego częstotliwości z ostro przemyślanym mieszaniem cech może dawać wyraźniejsze obrazy przy mniejszych kosztach obliczeniowych. Choć nie odtwarza perfekcyjnie każdego rodzaju detalu, zwłaszcza skomplikowanego tekstu, wskazuje drogę ku bardziej praktycznym systemom super-rozdzielczości, które mogłyby działać na codziennym sprzęcie i poprawiać czytelność obrazów używanych w nauce, medycynie, bezpieczeństwie i innych dziedzinach.
Cytowanie: Zheng, X., Chen, Z. & Huang, D. Lightweight super-resolution method based on scattering processing and feature interaction. Sci Rep 16, 15018 (2026). https://doi.org/10.1038/s41598-026-44351-5
Słowa kluczowe: super-rozdzielczość obrazu, uczenie głębokie, modele Transformer, dekompozycja częstotliwościowa, wydajne modele wizji