Clear Sky Science · en
Lightweight super-resolution method based on scattering processing and feature interaction
Sharper pictures from blurry images
Anyone who has zoomed in on a smartphone photo knows the disappointment of blocky, blurred details. From security cameras to medical scans and satellite views, many important images suffer from the same problem. This paper presents a new way to turn low-resolution pictures into clearer ones, aiming to recover crisp edges and textures while keeping the computing cost low enough for real-world devices.
Why turning up the detail is so hard
Image super-resolution is the task of reconstructing a high-resolution image from a low-resolution input. It matters for everyday photography, but also for video surveillance, medical imaging, and remote sensing. Classic deep-learning systems based on convolutional neural networks can enhance images, yet they mainly look at small neighborhoods of pixels and often miss how distant parts of an image relate to each other. Newer Transformer-based models capture these long-range relationships but are heavy to run and still struggle to reconstruct the finest details, like tiny textures and hairline edges, especially on devices with limited computing power.
Splitting images into slow and fast changes
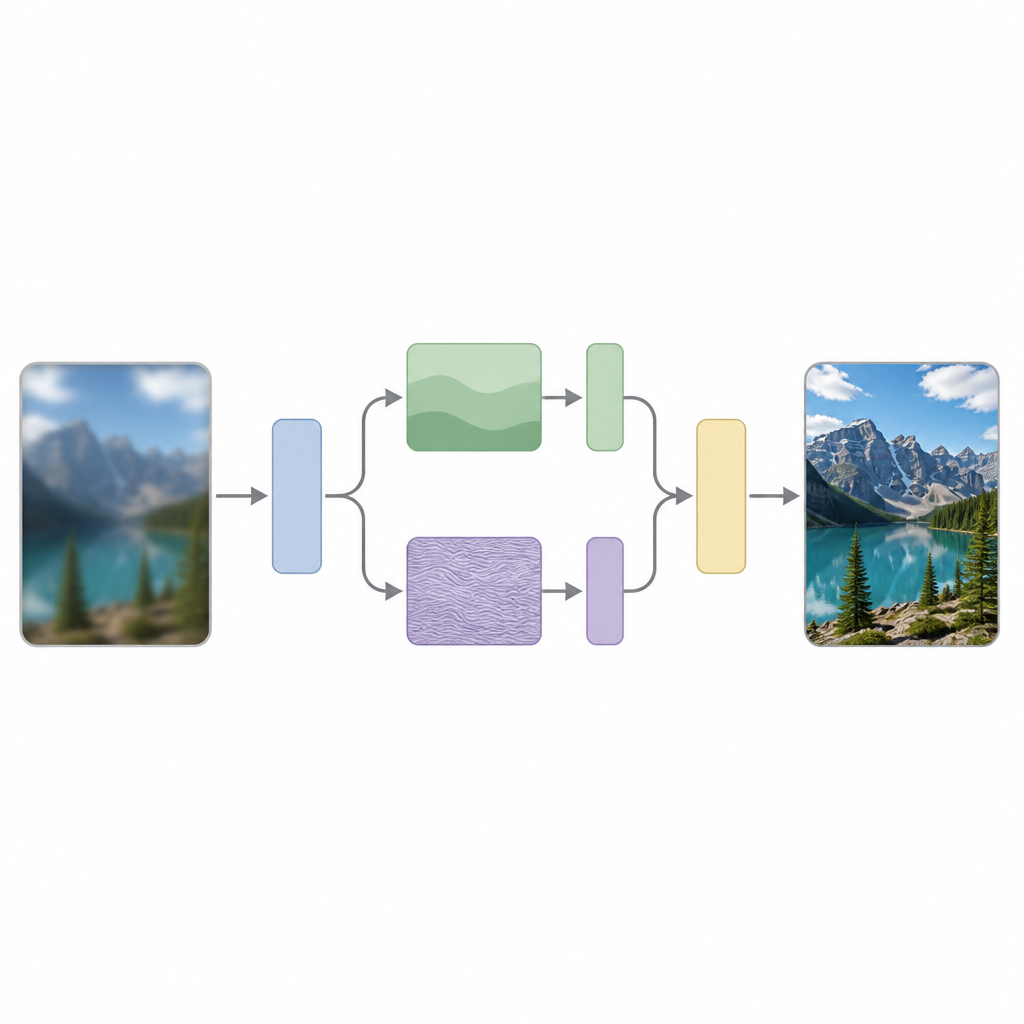
The authors argue that a key reason for this struggle is that most models treat all parts of an image the same, even though images naturally contain a mix of slow changes, such as smooth skies, and fast changes, such as sharp edges or repeating patterns. Their method, called Scattering Processing and Feature Interaction (SPFI), tackles this by explicitly separating input features into low-frequency components that describe broad structure and high-frequency components that encode fine details. They use a mathematical tool known as the Dual-Tree Complex Wavelet Transform to perform this split in a way that is less sensitive to small shifts in the image and better at picking out directions, such as lines and edges.

Special handling for fine details without heavy cost
Once the image information is split, SPFI processes the smooth and detailed parts differently. Low-frequency information, which is compact, is handled with a straightforward mixing method to capture global structure. For the high-frequency part, a direct approach would require a huge number of calculations because it tries to relate every pixel to every other one. To avoid this, the authors design an Einstein Mixing Method that cleverly reshapes the data and mixes channels in a way that keeps the important detail interactions while dramatically reducing the number of operations. In effect, the model pays extra attention to edges and textures without becoming too large or slow.
Bringing scales together efficiently
Another challenge for sharp reconstruction is that useful information appears at multiple scales, from tiny patterns to broad shapes. Standard Transformer attention treats all tokens at a single scale, which is both costly and limited. SPFI introduces a Cross-token Integration block that creates several versions of the features at different scales using depth-wise separable convolutions, a light form of filtering. These multi-scale streams interact and are recombined before the attention step, so the model can use both local detail and global context while reducing how much work the attention mechanism must do. This design helps the network focus on the most relevant interactions without wasting computation.
Better quality, faster results, with some caveats
In tests on standard image benchmarks, SPFI produced higher quality reconstructions than a range of recent super-resolution methods, including several based on Transformers, while using fewer floating point operations. It achieved slightly higher peak signal-to-noise ratios and better structural similarity scores, and it ran faster during inference, making it more suitable for near real-time use. Visual comparisons show that SPFI recovers building facades and other textures with fewer blurry artifacts, and it also proves relatively robust when the input images contain noise or are degraded in slightly different ways than expected. However, the authors note that very small, irregular details such as tiny text remain challenging, hinting that a fixed way of splitting frequencies may not fit all types of patterns.
What this means for future imaging tools
For a non-specialist, the main message is that the authors found a way to sharpen images by first separating smooth regions from fine details and then letting these parts interact efficiently across scales. Their SPFI method shows that combining frequency-aware processing with careful feature mixing can yield clearer pictures at a lower computational cost. While it does not perfectly recover every kind of detail, especially intricate text, it points toward more practical super-resolution systems that could run on everyday hardware and improve the clarity of images used in science, medicine, security, and beyond.
Citation: Zheng, X., Chen, Z. & Huang, D. Lightweight super-resolution method based on scattering processing and feature interaction. Sci Rep 16, 15018 (2026). https://doi.org/10.1038/s41598-026-44351-5
Keywords: image super resolution, deep learning, transformer models, frequency decomposition, efficient vision models