Clear Sky Science · de
Leichte Superauflösungsmethode basierend auf Streuverarbeitung und Merkmalsinteraktion
Schärfere Bilder aus unscharfen Aufnahmen
Wer schon einmal in ein Smartphone-Foto hineingezoomt hat, kennt die Enttäuschung über klobige, verschwommene Details. Von Überwachungskameras über medizinische Scans bis hin zu Satellitenaufnahmen leiden viele wichtige Bilder unter demselben Problem. Diese Arbeit stellt eine neue Methode vor, um niedrig aufgelöste Bilder in klarere Bilder zu verwandeln, mit dem Ziel, scharfe Kanten und Texturen wiederherzustellen und gleichzeitig die Rechenkosten so gering zu halten, dass sie auf realen Geräten praktikabel sind.
Warum es so schwer ist, Details zu verstärken
Bild-Superauflösung ist die Aufgabe, aus einer niedrig aufgelösten Eingabe ein hochaufgelöstes Bild zu rekonstruieren. Sie ist wichtig für Alltagsfotografie, aber auch für Videoüberwachung, medizinische Bildgebung und Fernerkundung. Klassische Deep-Learning-Systeme auf Basis von Convolutional Neural Networks können Bilder verbessern, betrachten dabei aber meist nur kleine Pixelumgebungen und übersehen oft, wie weit auseinanderliegende Bildteile zueinander in Beziehung stehen. Neuere Transformer-basierte Modelle erfassen diese langfristigen Zusammenhänge, sind aber rechenintensiv und tun sich weiterhin schwer, feinste Details wie winzige Texturen und haarfeine Kanten zu rekonstruieren — besonders auf Geräten mit begrenzter Rechenleistung.
Aufteilen von Bildern in langsame und schnelle Änderungen
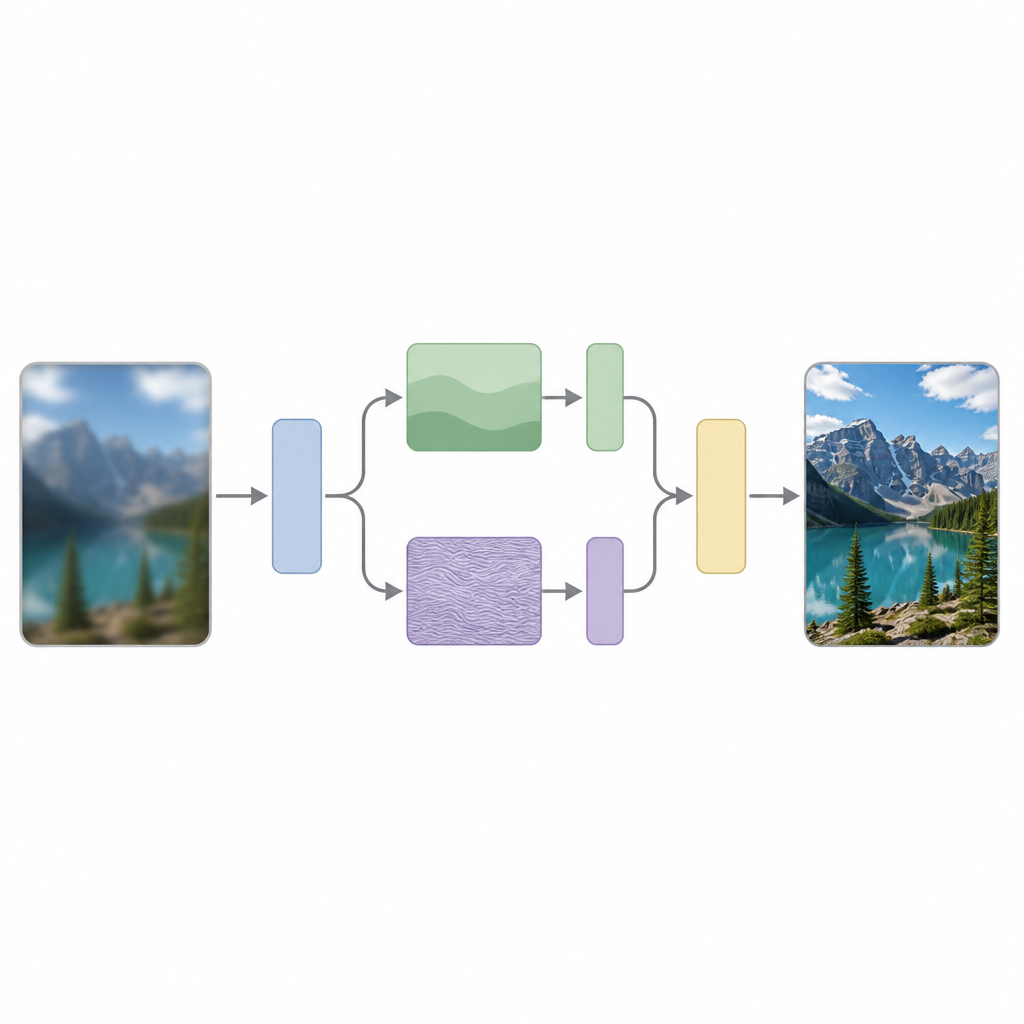
Die Autoren argumentieren, dass ein zentraler Grund für diese Schwierigkeiten darin liegt, dass die meisten Modelle alle Bildbereiche gleich behandeln, obwohl Bilder natürlicherweise eine Mischung aus langsamen Veränderungen, wie glatten Himmeln, und schnellen Veränderungen, wie scharfen Kanten oder wiederkehrenden Mustern, enthalten. Ihre Methode, genannt Scattering Processing and Feature Interaction (SPFI), begegnet dem, indem sie Eingabemerkmale explizit in niederfrequente Komponenten, die grobe Struktur beschreiben, und hochfrequente Komponenten, die feine Details kodieren, trennt. Zur Durchführung dieser Aufteilung verwenden sie ein mathematisches Werkzeug, das als Dual-Tree Complex Wavelet Transform bekannt ist; dieses ist weniger empfindlich gegenüber kleinen Verschiebungen im Bild und besser darin, Richtungen wie Linien und Kanten zu erkennen.

Spezielle Behandlung feiner Details ohne hohen Kostenaufwand
Nachdem die Bildinformation aufgeteilt ist, verarbeitet SPFI die glatten und die detailreichen Teile unterschiedlich. Niederfrequente Informationen, die kompakt sind, werden mit einer einfachen Mischmethode behandelt, um die globale Struktur zu erfassen. Für den hochfrequenten Anteil würde ein direkter Ansatz eine enorme Anzahl von Berechnungen erfordern, weil er versucht, jeden Pixel mit jedem anderen in Beziehung zu setzen. Um dies zu vermeiden, entwerfen die Autoren eine sogenannte Einstein Mixing Method, die die Daten geschickt umformt und Kanäle mischt, sodass die wichtigen Detailinteraktionen erhalten bleiben und gleichzeitig die Anzahl der Operationen drastisch reduziert wird. Effektiv richtet das Modell mehr Aufmerksamkeit auf Kanten und Texturen, ohne zu groß oder langsam zu werden.
Effizientes Zusammenführen von Skalen
Eine weitere Herausforderung für eine scharfe Rekonstruktion besteht darin, dass nützliche Informationen auf mehreren Skalen vorkommen, von winzigen Mustern bis zu breiten Formen. Standardmäßige Transformer-Attention behandelt alle Tokens in einer einzigen Skala, was sowohl kostspielig als auch begrenzt ist. SPFI führt einen Cross-token Integration Block ein, der mehrere Versionen der Merkmale auf unterschiedlichen Skalen erzeugt, indem depth-wise separable Convolutions verwendet werden — eine leichte Form der Filterung. Diese Multi-Skalen-Ströme interagieren und werden vor dem Attention-Schritt wieder zusammengeführt, sodass das Modell sowohl lokale Details als auch globalen Kontext nutzen kann und gleichzeitig den Aufwand reduziert, den der Attention-Mechanismus leisten muss. Dieses Design hilft dem Netzwerk, sich auf die relevantesten Interaktionen zu konzentrieren, ohne Rechenleistung zu verschwenden.
Bessere Qualität, schnellere Ergebnisse, mit einigen Einschränkungen
In Tests auf standardisierten Bildbenchmarks erzeugte SPFI qualitativ hochwertigere Rekonstruktionen als eine Reihe aktueller Superauflösungsmethoden, darunter mehrere auf Transformern basierende Ansätze, und das bei geringerem Fließkommaaufwand. Es erreichte leicht höhere Peak-Signal-to-Noise-Ratios und bessere Structural-Similarity-Werte und lief während der Inferenz schneller, wodurch es sich eher für nahezu Echtzeitanwendungen eignet. Visuelle Vergleiche zeigen, dass SPFI Fassaden und andere Texturen mit weniger verschwommenen Artefakten rekonstruiert, und es erweist sich zudem als relativ robust, wenn die Eingangsbilder Rauschen enthalten oder in leicht abweichender Weise degradiert sind. Die Autoren merken jedoch an, dass sehr kleine, unregelmäßige Details wie winziger Text weiterhin eine Herausforderung darstellen, was darauf hinweist, dass eine feste Frequenzaufteilung nicht für alle Musterarten optimal ist.
Was das für zukünftige Bildwerkzeuge bedeutet
Für Nicht-Spezialisten lautet die Kernbotschaft: Die Autoren haben einen Weg gefunden, Bilder zu schärfen, indem sie glatte Regionen von feinen Details trennen und diese Teile dann über Skalen hinweg effizient interagieren lassen. Ihre SPFI-Methode zeigt, dass die Kombination aus frequenzbewusster Verarbeitung und sorgfältigem Merkmalsmischen klarere Bilder bei geringeren Rechenkosten liefern kann. Obwohl sie nicht jede Detailart perfekt rekonstruiert, insbesondere sehr feinen Text, weist sie den Weg zu praktischeren Superauflösungssystemen, die auf Alltags-Hardware laufen und die Klarheit von Bildern in Wissenschaft, Medizin, Sicherheit und darüber hinaus verbessern könnten.
Zitation: Zheng, X., Chen, Z. & Huang, D. Lightweight super-resolution method based on scattering processing and feature interaction. Sci Rep 16, 15018 (2026). https://doi.org/10.1038/s41598-026-44351-5
Schlüsselwörter: Bild-Superauflösung, Tiefes Lernen, Transformer-Modelle, Frequenzzerlegung, effiziente Vision-Modelle