Clear Sky Science · fr
Méthode de super-résolution légère basée sur le traitement par diffusion et l’interaction des caractéristiques
Des images plus nettes à partir de photos floues
Quiconque a zoomé sur une photo prise au smartphone connaît la déception des détails pixelisés et flous. Des caméras de surveillance aux examens médicaux en passant par les images satellites, de nombreuses images importantes souffrent du même problème. Cet article présente une nouvelle façon de transformer des images basse résolution en images plus nettes, visant à retrouver des contours et des textures précis tout en maintenant un coût de calcul suffisamment faible pour des appareils réels.
Pourquoi augmenter les détails est si difficile
La super-résolution d’image consiste à reconstruire une image haute résolution à partir d’un entrée basse résolution. Elle compte pour la photographie quotidienne, mais aussi pour la vidéosurveillance, l’imagerie médicale et la télédétection. Les systèmes classiques d’apprentissage profond basés sur les réseaux convolutifs peuvent améliorer les images, mais ils n’examinent que de petits voisinages de pixels et manquent souvent les relations entre parties éloignées de l’image. Les modèles récents basés sur les Transformers capturent ces relations à longue portée mais sont lourds à exécuter et peinent encore à reconstruire les détails les plus fins, comme les textures minuscules et les bords fins, surtout sur des appareils aux ressources limitées.
Diviser l’image en changements lents et rapides
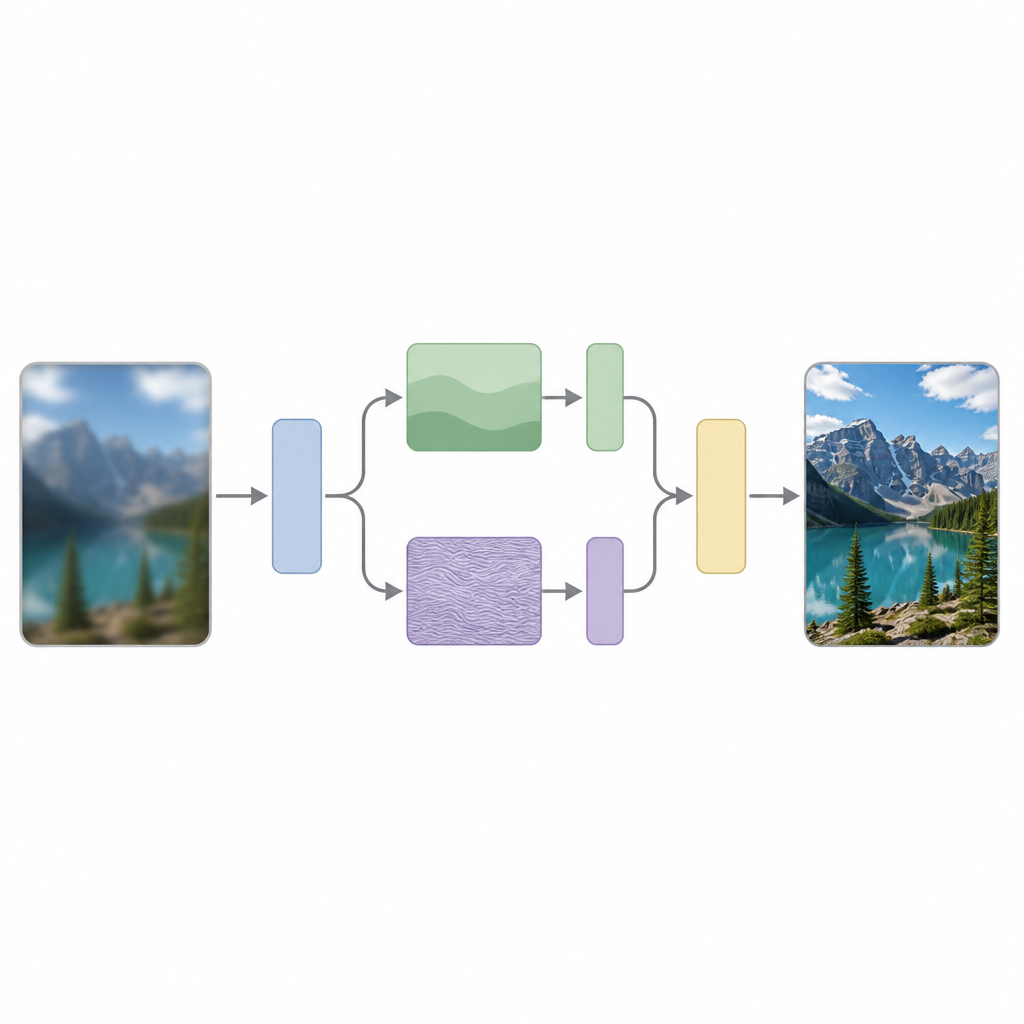
Les auteurs soutiennent qu’une raison clé de cette difficulté est que la plupart des modèles traitent toutes les parties d’une image de la même manière, alors que les images contiennent naturellement un mélange de changements lents, comme un ciel uniforme, et de changements rapides, comme des contours nets ou des motifs répétés. Leur méthode, appelée Scattering Processing and Feature Interaction (SPFI), s’attaque à cela en séparant explicitement les caractéristiques d’entrée en composants basse fréquence décrivant la structure globale et composants haute fréquence codant les détails fins. Ils utilisent un outil mathématique connu sous le nom de Transformée en ondelettes complexes Dual-Tree pour effectuer cette séparation d’une manière moins sensible aux petits décalages dans l’image et meilleure pour identifier les directions, comme les lignes et les bords.

Traitement spécial des détails fins sans coût important
Une fois l’information image séparée, SPFI traite différemment les parties lisses et les parties détaillées. L’information basse fréquence, qui est compacte, est gérée par une méthode de mélange simple pour capturer la structure globale. Pour la partie haute fréquence, une approche directe nécessiterait un nombre énorme de calculs parce qu’elle tenterait de relier chaque pixel à tous les autres. Pour éviter cela, les auteurs conçoivent une méthode de mélange dite Einstein qui remodèle astucieusement les données et mélange les canaux de façon à préserver les interactions de détail importantes tout en réduisant drastiquement le nombre d’opérations. En pratique, le modèle accorde une attention supplémentaire aux contours et aux textures sans devenir trop volumineux ni trop lent.
Rapprocher les échelles de façon efficace
Un autre défi pour une reconstruction nette est que l’information utile apparaît à plusieurs échelles, des motifs minuscules aux formes larges. L’attention standard des Transformers traite tous les tokens à une seule échelle, ce qui est à la fois coûteux et limité. SPFI introduit un bloc d’Intégration Cross-token qui crée plusieurs versions des caractéristiques à différentes échelles en utilisant des convolutions séparables en profondeur, une forme légère de filtrage. Ces flux multi-échelles interagissent et sont recombinés avant l’étape d’attention, de sorte que le modèle peut exploiter à la fois le détail local et le contexte global tout en réduisant le travail requis par le mécanisme d’attention. Cette conception aide le réseau à se concentrer sur les interactions les plus pertinentes sans gaspiller de calcul.
Meilleure qualité, résultats plus rapides, avec quelques limites
Dans des tests sur des benchmarks standards d’images, SPFI a produit des reconstructions de meilleure qualité que diverses méthodes récentes de super-résolution, y compris plusieurs basées sur des Transformers, tout en utilisant moins d’opérations en virgule flottante. Il a atteint des rapports signal/bruit légèrement supérieurs et de meilleurs scores de similarité structurelle, et il s’est exécuté plus rapidement à l’inférence, le rendant plus adapté à une utilisation quasi temps réel. Les comparaisons visuelles montrent que SPFI récupère les façades de bâtiments et autres textures avec moins d’artefacts flous, et il se montre relativement robuste lorsque les images d’entrée contiennent du bruit ou sont dégradées d’une manière légèrement différente de celle attendue. Cependant, les auteurs notent que des détails très petits et irréguliers, comme de tout petits textes, restent difficiles, ce qui suggère qu’une séparation des fréquences fixe peut ne pas convenir à tous les types de motifs.
Ce que cela signifie pour les futurs outils d’imagerie
Pour un non-spécialiste, le message principal est que les auteurs ont trouvé un moyen d’affiner les images en séparant d’abord les régions lisses des détails fins, puis en laissant ces parties interagir efficacement à travers les échelles. Leur méthode SPFI montre que combiner un traitement conscient des fréquences avec un mélange soigné des caractéristiques peut produire des images plus claires à un coût computationnel réduit. Bien qu’elle ne récupère pas parfaitement chaque type de détail, en particulier les textes très fins, elle ouvre la voie à des systèmes de super-résolution plus pratiques pouvant fonctionner sur du matériel courant et améliorer la lisibilité des images utilisées en science, en médecine, en sécurité et au-delà.
Citation: Zheng, X., Chen, Z. & Huang, D. Lightweight super-resolution method based on scattering processing and feature interaction. Sci Rep 16, 15018 (2026). https://doi.org/10.1038/s41598-026-44351-5
Mots-clés: super-résolution d’image, apprentissage profond, modèles Transformer, décomposition en fréquence, modèles de vision efficaces