Clear Sky Science · it
Metodo leggero di super-risoluzione basato sul processamento di scattering e sull’interazione delle caratteristiche
Immagini più nitide a partire da foto sfocate
Chiunque abbia ingrandito una foto scattata con lo smartphone conosce la delusione di dettagli blocchettati e sfocati. Dalle telecamere di sorveglianza alle scansioni mediche fino alle vedute satellitari, molte immagini importanti soffrono dello stesso problema. Questo articolo presenta un nuovo modo per trasformare immagini a bassa risoluzione in versioni più chiare, con l’obiettivo di recuperare bordi e texture nitidi mantenendo il costo computazionale sufficientemente basso per dispositivi reali.
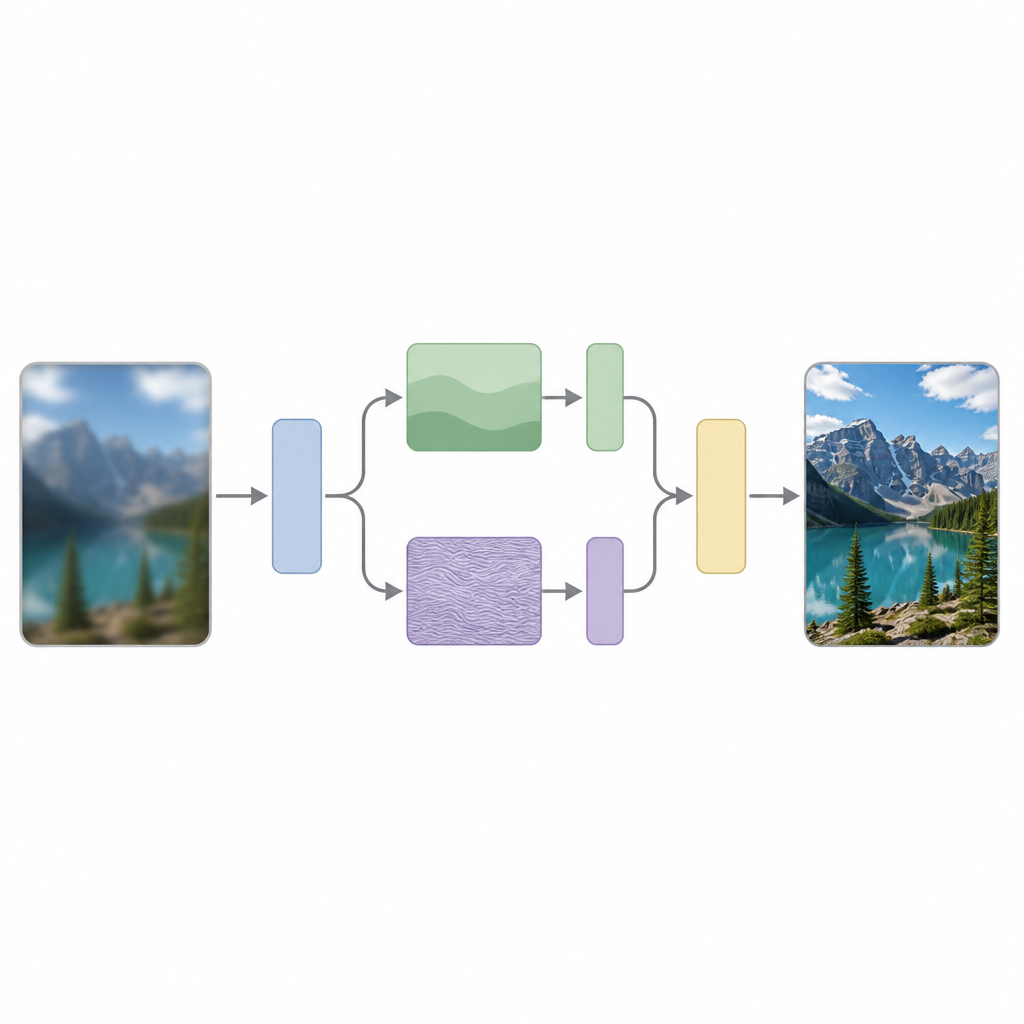
Perché aumentare i dettagli è così difficile
La super-risoluzione delle immagini è il compito di ricostruire un’immagine ad alta risoluzione a partire da un input a bassa risoluzione. Conta per la fotografia di tutti i giorni, ma anche per la videosorveglianza, l’imaging medico e il telerilevamento. I sistemi classici di deep learning basati su reti neurali convoluzionali possono migliorare le immagini, ma guardano principalmente a piccoli intorni di pixel e spesso perdono le relazioni tra parti distanti dell’immagine. I modelli più recenti basati su Transformer catturano queste relazioni a lungo raggio ma sono pesanti da eseguire e fanno ancora fatica a ricostruire i dettagli più fini, come sottili texture e bordi leggeri, specialmente su dispositivi con risorse di calcolo limitate.
Separare le immagini in variazioni lente e veloci
Gli autori sostengono che una ragione chiave di questa difficoltà è che la maggior parte dei modelli tratta tutte le parti di un’immagine allo stesso modo, nonostante le immagini contengano naturalmente una mescola di cambiamenti lenti, come cieli uniformi, e cambiamenti veloci, come bordi netti o pattern ripetuti. Il loro metodo, chiamato Scattering Processing and Feature Interaction (SPFI), affronta questo problema separando esplicitamente le caratteristiche di input in componenti a bassa frequenza che descrivono la struttura ampia e componenti ad alta frequenza che codificano i dettagli fini. Utilizzano uno strumento matematico noto come Trasformata Wavelet Complessa a Doppio Albero per effettuare questa divisione in modo meno sensibile a piccoli spostamenti nell’immagine e più efficace nell’individuare direzioni, come linee e bordi.

Gestire i dettagli fini senza costi elevati
Una volta separate le informazioni dell’immagine, SPFI elabora le parti lisce e quelle dettagliate in modo diverso. Le informazioni a bassa frequenza, che sono compatte, sono trattate con un metodo di mixing semplice per catturare la struttura globale. Per la parte ad alta frequenza, un approccio diretto richiederebbe un numero enorme di calcoli perché tenta di mettere in relazione ogni pixel con tutti gli altri. Per evitare ciò, gli autori progettano un Metodo di Mixing 'Einstein' che rimodella intelligentemente i dati e miscela i canali in modo da mantenere le interazioni di dettaglio importanti riducendo drasticamente il numero di operazioni. In pratica, il modello presta maggiore attenzione a bordi e texture senza diventare troppo grande o lento.
Mettere insieme le scale in modo efficiente
Un’altra sfida per una ricostruzione nitida è che l’informazione utile appare a più scale, da pattern minuscoli a forme ampie. L’attenzione standard dei Transformer tratta tutti i token a una singola scala, il che è sia costoso sia limitato. SPFI introduce un blocco di Integrazione Cross-token che crea diverse versioni delle feature a differenti scale mediante convoluzioni separabili in profondità, una forma leggera di filtraggio. Questi flussi multi-scala interagiscono e vengono ricombinati prima del passo di attenzione, così il modello può utilizzare sia il dettaglio locale sia il contesto globale riducendo il lavoro che il meccanismo di attenzione deve svolgere. Questo design aiuta la rete a concentrarsi sulle interazioni più rilevanti senza sprecare calcolo.
Migliore qualità, risultati più veloci, con alcune avvertenze
Nei test su benchmark standard di immagini, SPFI ha prodotto ricostruzioni di qualità superiore rispetto a una gamma di metodi recenti di super-risoluzione, inclusi diversi basati su Transformer, pur usando meno operazioni in virgola mobile. Ha raggiunto rapporti segnale-rumore di picco leggermente più alti e migliori punteggi di similarità strutturale, ed è risultato più veloce durante l’inferenza, rendendolo più adatto per un uso quasi in tempo reale. I confronti visivi mostrano che SPFI recupera facciate di edifici e altre texture con meno artefatti sfocati, e si dimostra relativamente robusto quando le immagini in input contengono rumore o sono degradate in modi leggermente diversi dall’atteso. Tuttavia, gli autori notano che dettagli molto piccoli e irregolari, come testi minuscoli, restano sfidanti, suggerendo che un modo fisso di separare le frequenze potrebbe non adattarsi a tutti i tipi di pattern.
Cosa significa per gli strumenti di imaging futuri
Per un non specialista, il messaggio principale è che gli autori hanno trovato un modo per rendere le immagini più nitide separando prima le regioni lisce dai dettagli fini e poi consentendo a queste parti di interagire in modo efficiente attraverso le scale. Il loro metodo SPFI dimostra che combinare un processamento consapevole delle frequenze con un mixing attento delle feature può produrre immagini più chiare a un costo computazionale inferiore. Pur non recuperando perfettamente ogni tipo di dettaglio, in particolare testi intricati, indica la strada verso sistemi di super-risoluzione più pratici che potrebbero funzionare su hardware di uso quotidiano e migliorare la chiarezza delle immagini impiegate in scienza, medicina, sicurezza e oltre.
Citazione: Zheng, X., Chen, Z. & Huang, D. Lightweight super-resolution method based on scattering processing and feature interaction. Sci Rep 16, 15018 (2026). https://doi.org/10.1038/s41598-026-44351-5
Parole chiave: super-risoluzione delle immagini, apprendimento profondo, modelli transformer, decomposizione in frequenza, modelli visivi efficienti