Clear Sky Science · pt
Destilando conhecimento específico de populações em um modelo unificado para segmentação generalizável de tumores cerebrais
Por que um modelo único para todos importa
Tumores cerebrais não têm a mesma aparência de uma pessoa para outra. Crianças, adultos, pacientes de diferentes países e pessoas com diferentes tipos de tumor podem apresentar padrões muito distintos em exames de ressonância magnética. Ainda assim, médicos e hospitais preferem uma única ferramenta computacional confiável que possa contornar tumores automaticamente para todo paciente, em vez de lidar com vários modelos separados. Este estudo apresenta uma nova maneira de treinar um sistema unificado para que ele funcione bem em cinco tipos muito diferentes de tumores cerebrais, potencialmente trazendo cuidado mais consistente aos pacientes em todo o mundo.
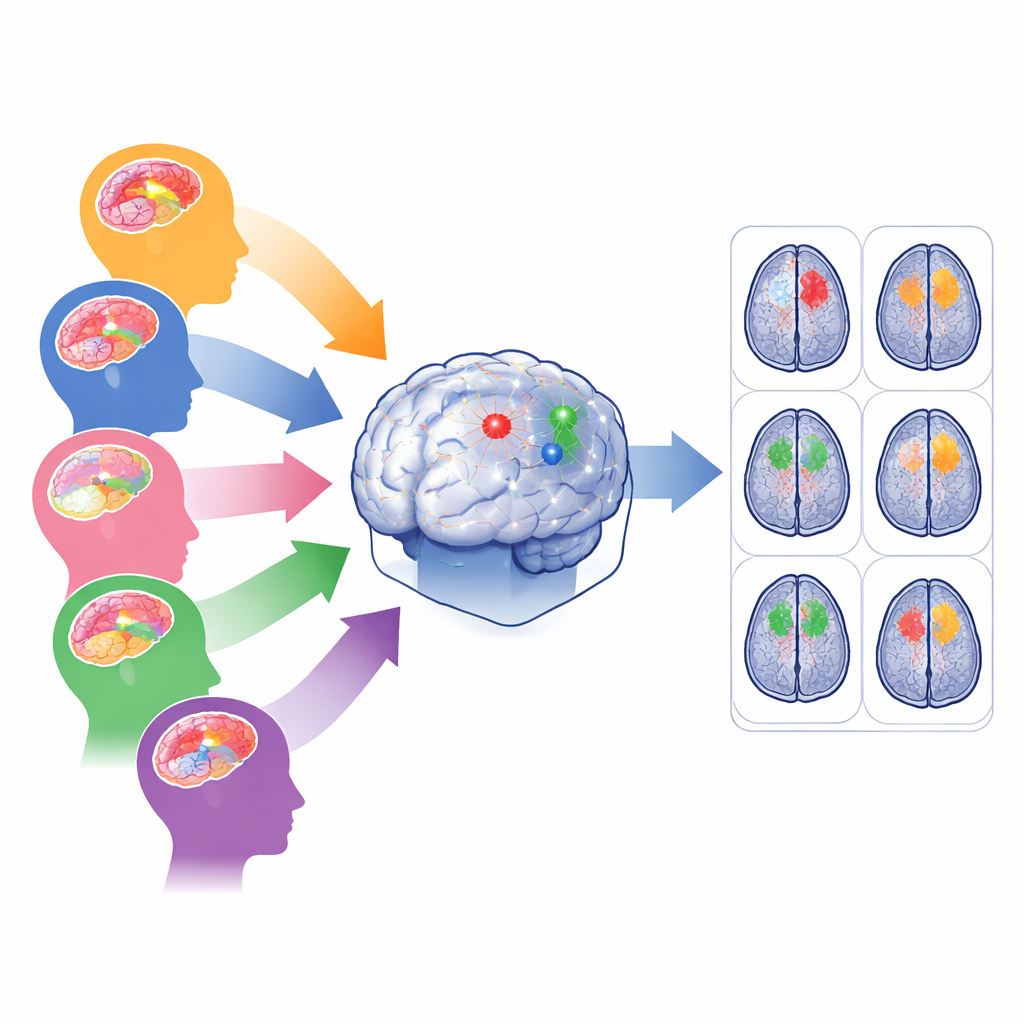
O desafio de muitos tipos de tumores cerebrais
Ferramentas modernas de inteligência artificial podem traçar tumores cerebrais em exames de RM com precisão impressionante — mas normalmente apenas quando os dados se parecem com aqueles usados no treinamento. Em hospitais reais, os exames vêm de máquinas e protocolos diferentes, e os tumores variam em tamanho, forma e localização. Gliomas adultos frequentemente ficam em regiões profundas do cérebro, gliomas na África Subsaariana são capturados com scanners de qualidade inferior, gliomas pediátricos reorganizam regiões internas do tumor, meningiomas ficam na superfície do cérebro e metástases podem aparecer como muitos pontos dispersos. Treinar um único modelo com todos esses casos de uma vez tende a favorecer o grupo mais comum e negligenciar populações raras ou ruidosas, correndo o risco de desempenho ruim justamente onde a ajuda é mais necessária.
Por que as soluções anteriores ficaram aquém
Pesquisadores tentaram várias alternativas. Uma opção é ajustar finamente um modelo para cada novo conjunto de dados ou hospital, mas isso exige manter muitas versões e pode fazer o sistema “esquecer” conhecimentos anteriores. Outra estratégia é usar conjuntos de modelos (ensembles), onde vários modelos especializados votam na resposta final; embora frequentemente precisos, são lentos e caros computacionalmente. Aprendizado por currículo, que alimenta os dados em uma ordem cuidadosamente escolhida de casos mais fáceis para mais difíceis, pode ajudar, mas é complicado de projetar e ainda pode não capturar todas as variedades de tumor. Modelos de fundamento como “segment anything” prometem segmentação de propósito geral, mas normalmente exigem prompts humanos e não são totalmente automáticos — limitando sua utilidade em fluxos de trabalho clínicos rotineiros.
Misturando muitos especialistas em um único aluno
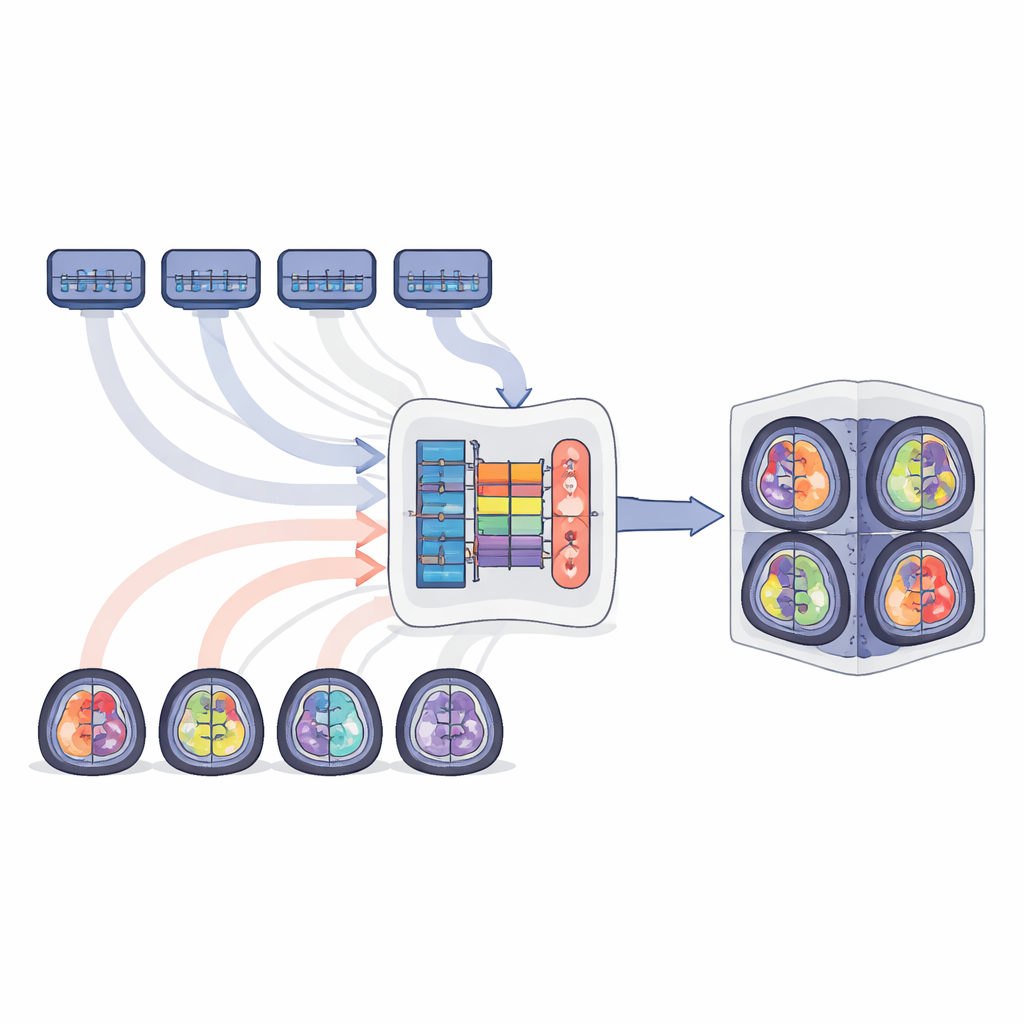
Os autores propõem o MTSS-KDNet, uma abordagem “múltiplos professores, um único aluno” inspirada em como um médico em formação pode aprender com vários especialistas. Primeiro, cinco modelos especialistas são treinados separadamente, cada um focado em uma população tumoral: gliomas adultos, gliomas da África Subsaariana, gliomas pediátricos, meningiomas e metástases. Essas redes professoras se afinam fortemente nas características do seu próprio grupo. Em seguida, um único modelo aluno é treinado para imitá-las — mas de forma inteligente e consciente das populações. Para cada exame de treinamento, o professor correspondente e o aluno processam a imagem em paralelo. O aluno é orientado a igualar os padrões internos e as previsões finais do professor enquanto também é corrigido usando os contornos verdadeiros do tumor. Um esquema de amostragem focado em equidade garante que cada lote de treinamento sempre inclua um caso de cada população, de modo que grupos raros sejam vistos com a mesma frequência que os mais comuns.
Como o modelo unificado se sai na prática
Após o treinamento, apenas o modelo aluno é usado para novos pacientes, mantendo a implantação simples e rápida. Os pesquisadores o avaliaram em todas as cinco populações tumorais usando medidas padrão de quão próximos os volumes e limites preditos do tumor estão dos rótulos de especialistas. Em tumor inteiro, núcleo tumoral e regiões ativamente crescentes, o modelo unificado alcançou pontuações fortes que igualaram ou superaram não só seus professores individuais, mas também linhas de base poderosas como modelos afinados, aprendizado por currículo e ensembles de múltiplos modelos. Os ganhos foram especialmente notáveis em cenários difíceis, como tumores pediátricos, exames de baixa qualidade da África Subsaariana e metástases cerebrais dispersas, onde o aluno claramente superou especialistas específicos de população. Inspeções visuais mostraram contornos mais limpos e completos, e mapas de características internos revelaram que o modelo aprendeu a separar populações em sua representação interna sem precisar de rótulos na hora do teste.
O que isso significa para o cuidado futuro dos pacientes
Para um não especialista, a ideia central é que os autores encontraram uma maneira de transferir o know-how de muitos sistemas especialistas estreitos para um modelo geral, sem perder aquilo que torna cada especialista bom em sua tarefa. A estrutura MTSS-KDNet preserva as vantagens práticas de uma ferramenta única e automática, mantendo o desempenho entre pacientes, scanners e tipos de tumor diversos. Embora ainda exija recursos de treinamento substanciais e dependa de bons modelos professores iniciais, essa abordagem aponta para sistemas de segmentação “fundação” que podem atender populações globais de forma mais equitativa. A longo prazo, modelos unificados assim poderiam ajudar a garantir que pacientes com tumores raros, crianças ou pessoas em regiões com poucos recursos se beneficiem do mesmo nível de precisão em imagem que aqueles atendidos em grandes centros médicos.
Citação: Elzayat, A., Hanafy, N., Magdy, M. et al. Distilling population specific expertise into a unified model for generalizable brain tumor segmentation. Sci Rep 16, 12969 (2026). https://doi.org/10.1038/s41598-026-35627-x
Palavras-chave: segmentação de tumor cerebral, IA em imagem médica, destilação de conhecimento, generalização de modelo, RM