Clear Sky Science · pt
Habilitando repositórios de ácidos nucleicos em escala global por meio de seleção bioquímica versátil e escalável de arquivos à temperatura ambiente
Por que é importante armazenar material genético
Imagine poder rastrear novos vírus, estudar doenças raras e preservar as impressões genéticas de ecossistemas inteiros sem depender de fileiras de freezers que consomem muita energia. Hoje, a maior parte do DNA e, especialmente, o RNA frágil precisa ser mantida extremamente fria, o que é caro e impraticável para muitas clínicas e laboratórios ao redor do mundo. Este trabalho apresenta uma nova maneira de armazenar e buscar grandes coleções de amostras genéticas à temperatura ambiente, mantendo a capacidade de localizar rapidamente apenas as amostras que os cientistas precisam para testes.
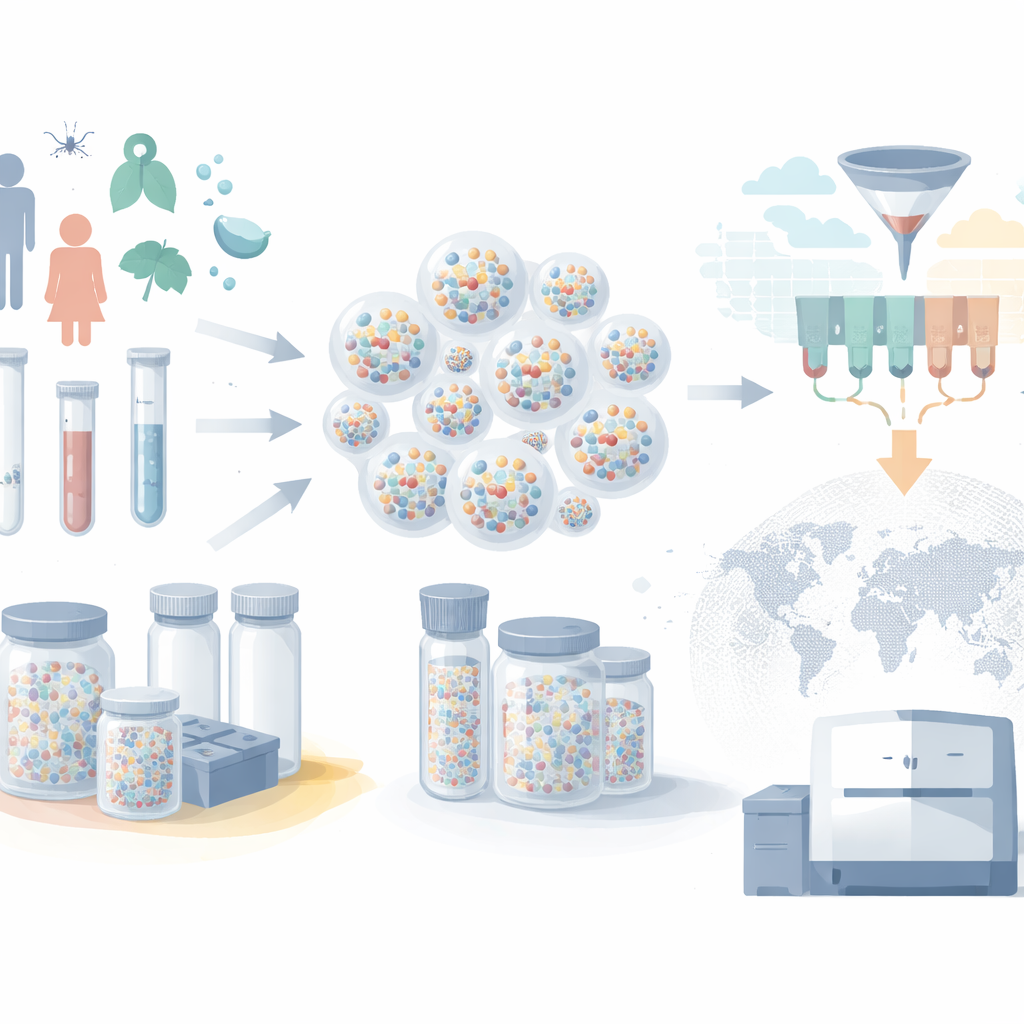
De fazendas de freezers a minúsculas cápsulas
Os biobancos modernos armazenam milhões de amostras de sangue, saliva e tecido, mas normalmente cada amostra fica em seu próprio tubo rotulado dentro de um grande freezer. À medida que as coleções crescem, essa abordagem de “um tubo por amostra” torna-se cara e lenta. Freezers exigem eletricidade contínua, sistemas robóticos movimentam amostras uma a uma, e o RNA pode se degradar se algo der errado. Os autores, em vez disso, usam cascas microscópicas de sílica — microcápsulas — para proteger o material genético. DNA e RNA são aprisionados dentro dessas partículas duráveis, que permanecem estáveis à temperatura ambiente. Muitos ácidos nucleicos diferentes podem ser armazenados juntos na mesma cápsula, e um grande número de cápsulas pode ser agrupado em um único tubo pequeno, reduzindo drasticamente o espaço de armazenamento e as necessidades energéticas.
Transformando tubos em um banco de dados pesquisável
Armazenar amostras é apenas metade do problema; os pesquisadores também precisam ser capazes de selecionar o subconjunto certo quando surgem novas perguntas. A inovação-chave deste trabalho é um esquema de rotulagem esperto que trata cada cápsula como um pequeno registro de banco de dados. Pequenos trechos de DNA ligados à superfície de cada cápsula funcionam como “etiquetas” que descrevem a amostra: por exemplo, idade do paciente, cidade de origem, mês e ano da coleta, status de vacinação e se a pessoa estava sintomática. Em vez de atribuir uma etiqueta única para cada valor possível, o sistema reutiliza um conjunto compacto de etiquetas e as combina de maneiras diferentes, muito parecido com a forma como números são escritos com dígitos ou como categorias podem ser codificadas usando combinações. Esse desenho “sensível ao tipo” permite que operações físicas simples sobre as etiquetas imitem as poderosas consultas de alcance e filtro que bancos de dados digitais realizam.
Como fazer perguntas às moléculas
Para recuperar amostras específicas de um tubo lotado, os autores usam sondas fluorescentes que se prendem apenas às cápsulas que apresentam etiquetas correspondentes. Essas sondas carregam corantes coloridos que podem ser lidos por um classificador em fluxo, que envia cápsulas fortemente fluorescentes por um caminho e as de baixa intensidade por outro. Ao escolher quais etiquetas iluminar e como combinar as cores, o sistema pode implementar operações lógicas como E (AND), OU (OR) e NÃO (NOT). Por exemplo, selecionar “não sintomático” significa rejeitar qualquer cápsula que brilhe quando testada para a etiqueta de sintomático. Intervalos numéricos, como faixas etárias ou períodos de datas, são tratados ignorando alguns dos “dígitos” menos importantes na idade ou data codificadas, de modo que uma única consulta pode recuperar todas as cápsulas cujas etiquetas caem dentro de uma janela escolhida.
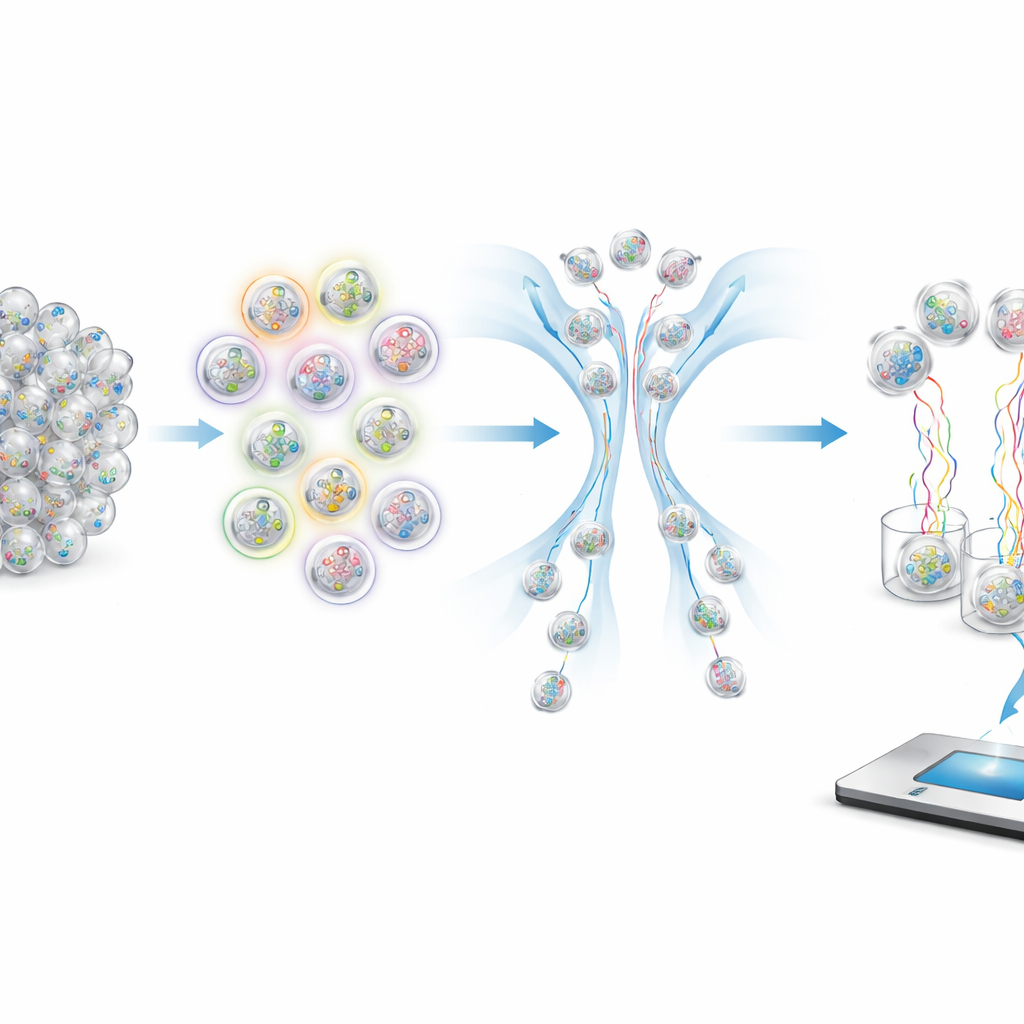
Testando o sistema com um surto simulado
Para demonstrar que a abordagem funciona na prática, os pesquisadores construíram um pequeno, porém realista, banco de dados de teste com 96 amostras sintéticas de SARS-CoV-2, modeladas como se tivessem sido coletadas de passageiros de avião que chegavam a Boston. Cada cápsula continha fragmentos de RNA viral mais um identificador interno único e etiquetas externas codificando informações fictícias do paciente e do voo. Em seguida, realizaram uma série de consultas que espelham a epidemiologia do mundo real: localizar todos os passageiros assintomáticos, selecionar faixas etárias específicas para procurar padrões de variantes e executar uma consulta combinada complexa que extraiu passageiros de uma determinada cidade, durante certos meses de 2020, que eram ou sintomáticos ou não vacinados. O sequenciamento das cápsulas recuperadas confirmou que as amostras corretas foram enriquecidas com altíssima precisão, mesmo quando o grupo desejado era apenas uma fração do pool total.
Prova de que amostras reais de pacientes podem ser preservadas
Além de casos de teste sintéticos, a equipe encapsulou amostras genuínas de pacientes infectados por SARS-CoV-2 contendo diferentes sublinhagens de Ômicron. Após armazenamento e recuperação, eles sequenciaram os genomas virais e os compararam com as mesmas amostras que nunca haviam sido encapsuladas. Apesar de trabalhar com quantidades muito baixas de RNA viral, o método ainda recuperou as variantes corretas, demonstrando que a proteção pela sílica não apaga diferenças genéticas sutis. Como cápsulas não alvo podem ser salvas após cada busca, o pool pode ser reutilizado repetidamente, e identificadores internos de DNA simples permitem verificações contínuas de integridade do arquivo, assim como checagens de integridade em armazenamento digital.
O que isso significa para o futuro
Em termos simples, este estudo mostra que amostras genéticas podem ser embaladas em cápsulas minúsculas e duráveis, amontoadas em um espaço pequeno à temperatura ambiente e depois separadas usando buscas flexíveis semelhantes a bancos de dados. O método reduz dramaticamente a dependência de freezers, enquanto permite consultas ricas que podem combinar faixas etárias, localizações, datas e estados de saúde em uma única operação. Com escalonamento adicional, tais arquivos à temperatura ambiente poderiam apoiar vigilância global de patógenos, medicina de precisão e até monitoramento ecológico de longo prazo em locais onde a infraestrutura de cadeia fria é escassa. O trabalho aponta para um futuro em que a informação biológica do mundo pode ser armazenada de forma compacta e acessada tão facilmente quanto arquivos na nuvem.
Citação: Berleant, J.D., Banal, J.L., Rao, D.K. et al. Enabling global-scale nucleic acid repositories through versatile, scalable biochemical selection from room-temperature archives. Nat Commun 17, 2807 (2026). https://doi.org/10.1038/s41467-026-69402-3
Palavras-chave: armazenamento de ácidos nucleicos, banco de dados molecular, codificação por DNA, vigilância de patógenos, biobanco à temperatura ambiente