Clear Sky Science · es
Habilitar repositorios de ácidos nucleicos a escala global mediante selección bioquímica versátil y escalable desde archivos a temperatura ambiente
Por qué importa conservar material genético
Imagine poder rastrear nuevos virus, estudiar enfermedades raras y preservar las huellas genéticas de ecosistemas completos sin depender de filas de congeladores que consumen mucha energía. Hoy, la mayoría del ADN y, especialmente, el frágil ARN deben mantenerse extremadamente fríos, lo que resulta costoso e impráctico para muchas clínicas y laboratorios en todo el mundo. Este artículo presenta una nueva forma de almacenar y buscar a través de vastas colecciones de muestras genéticas a temperatura ambiente, conservando la capacidad de encontrar rápidamente solo las muestras que los científicos necesitan para las pruebas.
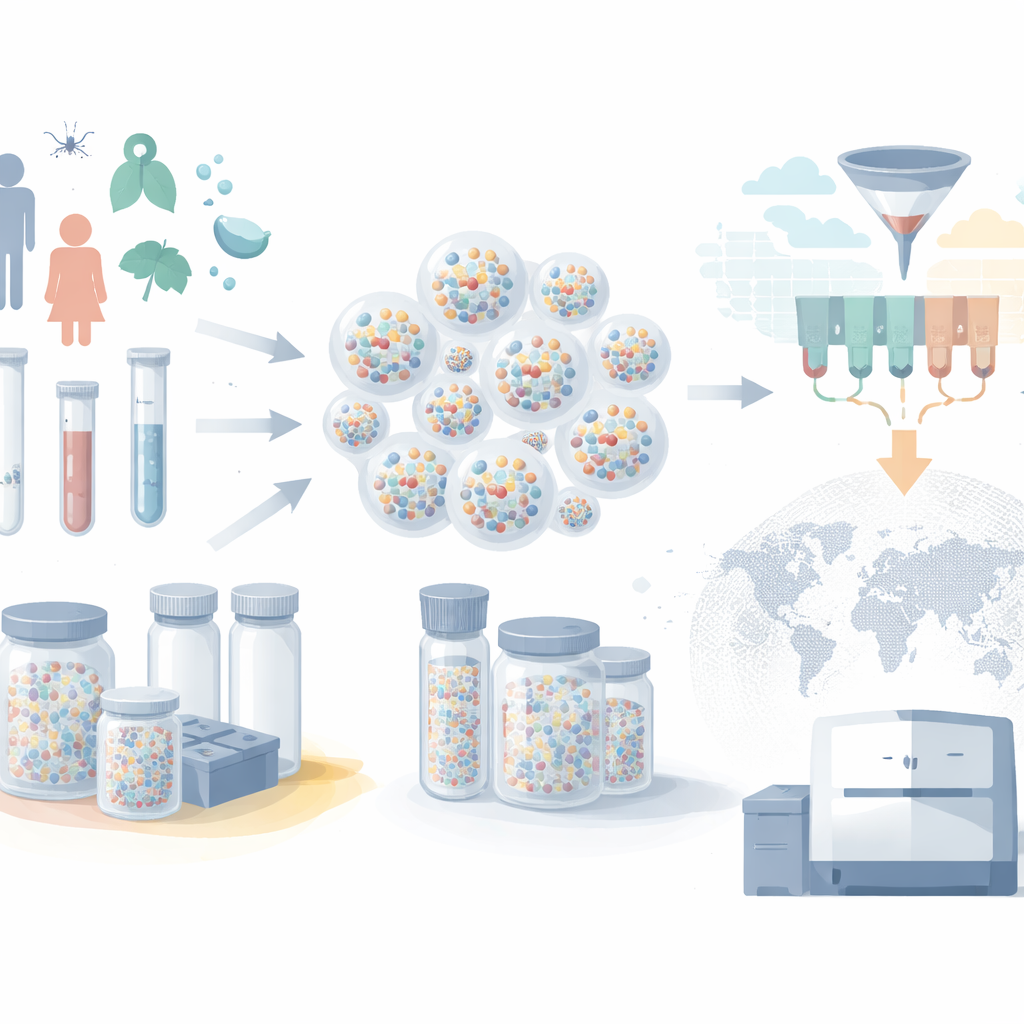
De granjas de congeladores a pequeñas cápsulas
Los biobancos modernos guardan millones de muestras de sangre, saliva y tejido, pero por lo general cada muestra vive en su propio tubo etiquetado dentro de un gran congelador. A medida que crecen las colecciones, este enfoque de “un tubo por muestra” se vuelve costoso y lento. Los congeladores exigen electricidad constante, los sistemas robóticos mueven las muestras una por una y el ARN puede degradarse si algo falla. Los autores usan en cambio cáscaras microscópicas de sílice—microcápsulas—para proteger el material genético. ADN y ARN quedan atrapados dentro de estas partículas duraderas, que permanecen estables a temperatura ambiente. Muchos ácidos nucleicos diferentes pueden almacenarse juntos en la misma cápsula, y un enorme número de cápsulas puede agruparse en un único tubo pequeño, reduciendo drásticamente el espacio de almacenamiento y las necesidades energéticas.
Convertir tubos en una base de datos buscable
Almacenar muestras es solo la mitad del problema; los investigadores también deben poder seleccionar el subconjunto correcto cuando surgen nuevas preguntas. La innovación clave en este trabajo es un ingenioso esquema de codificación que trata cada cápsula como un diminuto registro de base de datos. Fragmentos cortos de ADN adheridos al exterior de cada cápsula actúan como “etiquetas” que describen la muestra: por ejemplo, edad del paciente, ciudad de origen, mes y año de recolección, estado de vacunación y si la persona estaba sintomática. En lugar de asignar una etiqueta única a cada valor posible, el sistema reutiliza un conjunto compacto de etiquetas y las combina de diferentes maneras, de forma similar a cómo se escriben los números con dígitos o cómo las categorías pueden codificarse usando combinaciones. Este diseño “consciente del tipo” permite que operaciones físicas simples sobre las etiquetas imiten las potentes consultas de rango y filtro que realizan las bases de datos digitales.
Cómo formular preguntas a las moléculas
Para recuperar muestras específicas de un tubo lleno, los autores usan sondas fluorescentes que se adhieren únicamente a las cápsulas que llevan etiquetas coincidentes. Estas sondas transportan tintes coloreados que pueden leerse mediante un separador por flujo (flow sorter), que envía las cápsulas fuertemente brillantes por un camino y las tenues por otro. Al elegir qué etiquetas iluminar y cómo combinar los colores, el sistema puede implementar operaciones lógicas como AND, OR y NOT. Por ejemplo, seleccionar “no sintomático” significa rechazar cualquier cápsula que brille cuando se prueba la etiqueta de sintomático. Rangos numéricos como bandas de edad o intervalos de fechas se manejan ignorando algunos de los “dígitos” menos importantes en la edad o la fecha codificadas, de modo que una sola consulta puede extraer todas las cápsulas cuyas etiquetas caen dentro de una ventana elegida.
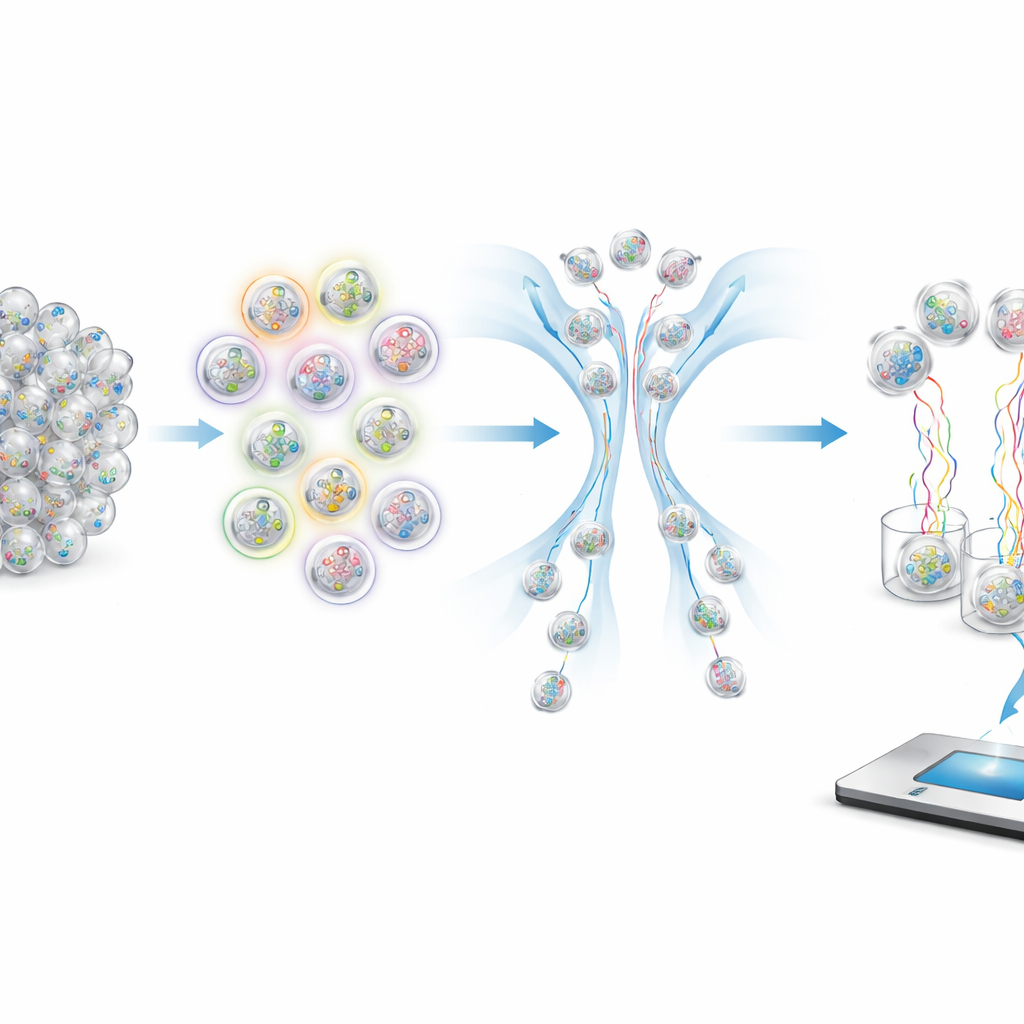
Probar el sistema con un brote simulado
Para demostrar que su enfoque funciona en la práctica, los investigadores construyeron una pequeña pero realista base de datos de prueba con 96 muestras sintéticas de SARS-CoV-2, modeladas como si hubieran sido recolectadas de pasajeros de aerolíneas que llegaban a Boston. Cada cápsula llevaba fragmentos de ARN viral más un identificador interno único y etiquetas externas que codificaban información ficticia de pacientes y vuelos. Luego realizaron una serie de consultas que reflejan la epidemiología del mundo real: hallar a todos los pasajeros asintomáticos, seleccionar rangos de edad específicos para buscar patrones de variantes y ejecutar una consulta combinada compleja que extrajo pasajeros de una ciudad determinada, durante ciertos meses de 2020, que eran sintomáticos o no estaban vacunados. La secuenciación de las cápsulas recuperadas confirmó que las muestras correctas se habían enriquecido con muy alta precisión, incluso cuando el grupo deseado era solo una fracción del conjunto total.
Prueba de que las muestras de pacientes reales se pueden preservar
Más allá de los casos de prueba sintéticos, el equipo encapsuló muestras genuinas de pacientes con SARS-CoV-2 que portaban diferentes sub-líneas de Omicron. Tras el almacenamiento y la recuperación, secuenciaron los genomas virales y los compararon con las mismas muestras que nunca se habían encapsulado. A pesar de trabajar con cantidades muy bajas de ARN viral, el método recuperó correctamente las variantes, demostrando que la protección con sílice no borra diferencias genéticas sutiles. Dado que las cápsulas no objetivo pueden conservarse después de cada búsqueda, la reserva puede reutilizarse repetidamente, y los identificadores internos de ADN simples permiten comprobaciones continuas de la integridad del archivo, similar a las verificaciones de integridad en el almacenamiento digital.
Lo que esto significa para el futuro
En términos sencillos, este estudio muestra que las muestras genéticas pueden empaquetarse en cápsulas diminutas y duraderas, apilarse juntas en un espacio reducido a temperatura ambiente y luego separarse usando búsquedas flexibles similares a las de una base de datos. El método reduce drásticamente la dependencia de los congeladores mientras permite consultas ricas que pueden combinar rangos de edad, ubicaciones, fechas y estados de salud en una sola operación. Con mayor escalado, estos archivos a temperatura ambiente podrían respaldar la vigilancia global de patógenos, la medicina de precisión e incluso el monitoreo ecológico a largo plazo en lugares donde la infraestructura de cadena de frío es escasa. El trabajo apunta hacia un futuro en el que la información biológica mundial pueda almacenarse de forma compacta y accederse tan fácilmente como archivos en la nube.
Cita: Berleant, J.D., Banal, J.L., Rao, D.K. et al. Enabling global-scale nucleic acid repositories through versatile, scalable biochemical selection from room-temperature archives. Nat Commun 17, 2807 (2026). https://doi.org/10.1038/s41467-026-69402-3
Palabras clave: almacenamiento de ácidos nucleicos, base de datos molecular, codificación con ADN, vigilancia de patógenos, biobancos a temperatura ambiente