Clear Sky Science · pl
Umożliwienie globalnych repozytoriów kwasów nukleinowych dzięki wszechstronnej, skalowalnej selekcji biochemicznej z archiwów w temperaturze pokojowej
Dlaczego przechowywanie materiału genetycznego ma znaczenie
Wyobraź sobie możliwość śledzenia nowych wirusów, badania rzadkich chorób i zachowania genetycznego odcisku całych ekosystemów bez potrzeby stosowania rzędu energochłonnych zamrażarek. Obecnie większość DNA, a zwłaszcza kruchy RNA, musi być przechowywana w bardzo niskich temperaturach, co jest kosztowne i niepraktyczne dla wielu klinik i laboratoriów na świecie. W tym artykule przedstawiono nowy sposób przechowywania i przeszukiwania ogromnych zbiorów próbek genetycznych w temperaturze pokojowej, przy jednoczesnej możliwości szybkiego odnalezienia potrzebnych naukowcom próbek do testów.
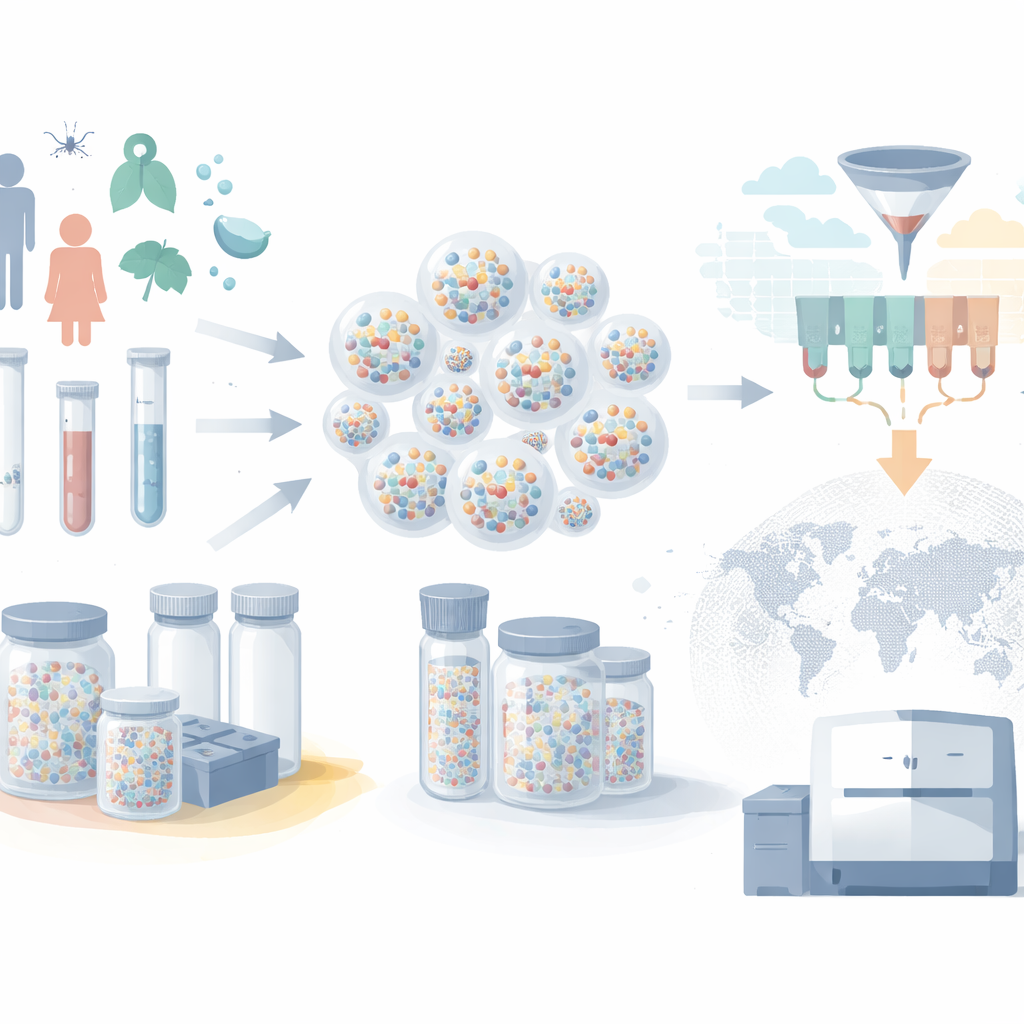
Od farm zamrażarek do maleńkich kapsułek
Nowoczesne biobanki przechowują miliony próbek krwi, śliny i tkanek, ale zwykle każda próbka znajduje się w osobnej, opisanej probówce wewnątrz dużej zamrażarki. W miarę powiększania się kolekcji podejście „jedna probówka na próbkę” staje się kosztowne i powolne. Zamrażarki wymagają stałej energii, systemy robotyczne przemieszczają próbki pojedynczo, a RNA może się degradować w razie awarii. Autorzy zamiast tego używają mikroskopijnych powłok krzemionkowych — mikrokapsułek — do ochrony materiału genetycznego. DNA i RNA są uwięzione wewnątrz tych trwałych cząstek, które pozostają stabilne w temperaturze pokojowej. Wiele różnych kwasów nukleinowych można przechowywać razem w tej samej kapsułce, a ogromne liczby kapsułek można łączyć w jednej małej probówce, co radykalnie zmniejsza potrzeby przestrzenne i energetyczne.
Przekształcenie probówek w przeszukiwalną bazę danych
Przechowywanie próbek to tylko połowa problemu; badacze muszą także móc wyselekcjonować właściwy podzbiór, gdy pojawiają się nowe pytania. Kluczową innowacją w tej pracy jest sprytne kodowanie etykiet, które traktuje każdą kapsułkę jak maleńki rekord w bazie danych. Krótkie fragmenty DNA przyczepione do zewnętrznej strony każdej kapsułki działają jak „tagi” opisujące próbkę: na przykład wiek pacjenta, miasto pochodzenia, miesiąc i rok pobrania, status szczepienia i czy osoba była objawowa. Zamiast przypisywać unikatowy tag dla każdej możliwej wartości, system ponownie wykorzystuje kompaktowy zestaw tagów i łączy je w różny sposób, podobnie jak liczby są zapisywane za pomocą cyfr lub jak kategorie można kodować przy pomocy kombinacji. Ten „świadomy typów” projekt pozwala na proste operacje fizyczne na tagach, które naśladują potężne zapytania zakresowe i filtrujące wykonywane przez cyfrowe bazy danych.
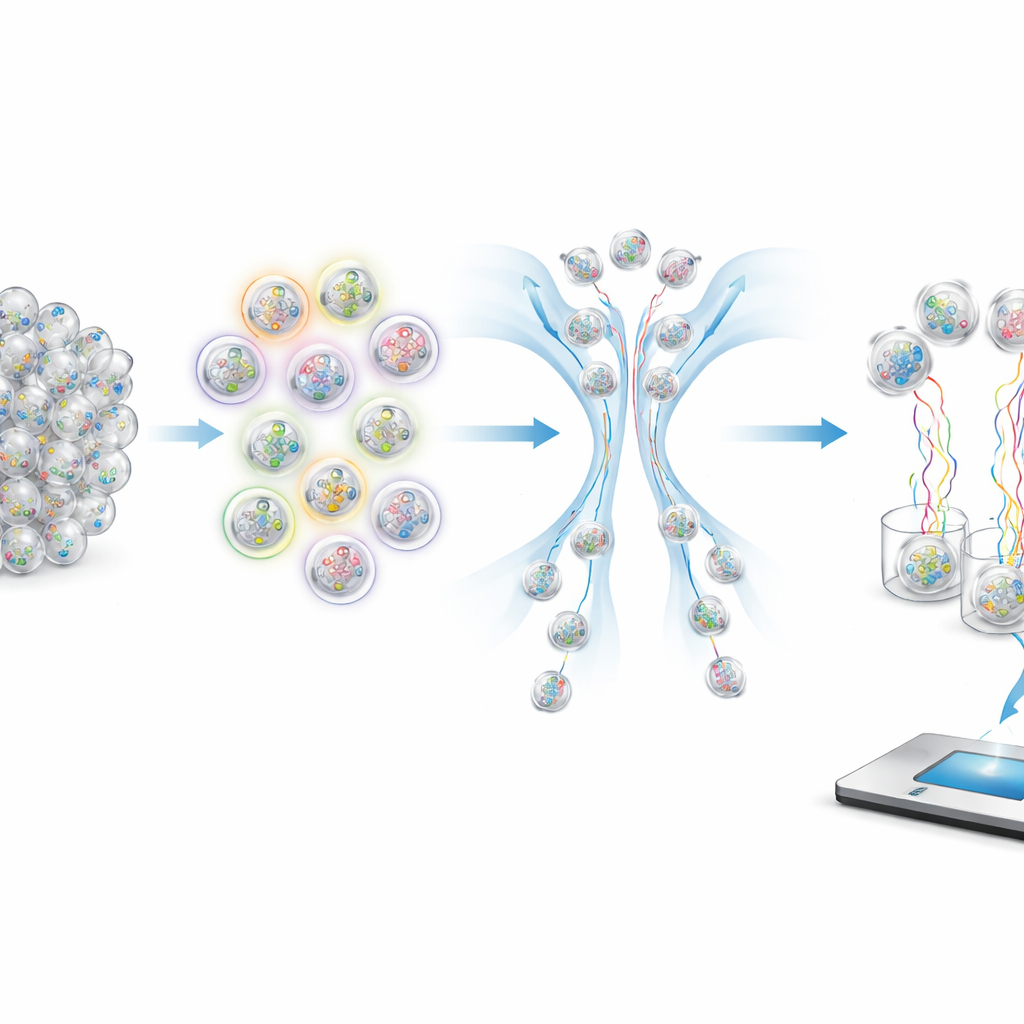
Jak zadawać pytania molekułom
Aby wyodrębnić konkretne próbki z zatłoczonej probówki, autorzy używają sond fluorescencyjnych, które przyczepiają się tylko do kapsułek noszących pasujące tagi. Te sondy niosą barwniki o różnych kolorach, które mogą być odczytane przez sortownik oparty na przepływie; intensywnie świecące kapsułki kierowane są jedną ścieżką, a słabo świecące inną. Poprzez wybór, które tagi podświetlić i jak łączyć kolory, system może realizować operacje logiczne takie jak I (AND), LUB (OR) i NIE (NOT). Na przykład wybór „nieobjawowy” oznacza odrzucenie każdej kapsułki, która świeci przy teście na tag objawowości. Zakresy liczbowe, takie jak przedziały wiekowe czy daty, obsługiwane są przez zignorowanie niektórych mniej istotnych „cyfr” w zakodowanym wieku lub dacie, dzięki czemu jedno zapytanie może wyciągnąć wszystkie kapsułki, których tagi mieszczą się w wybranym oknie.
Testowanie systemu na modelowym wybuchu epidemii
Aby pokazać, że ich podejście działa w praktyce, badacze zbudowali małą, ale realistyczną testową bazę danych z 96 syntetycznymi próbkami SARS-CoV-2, modelowanymi tak, jakby zostały pobrane od pasażerów linii lotniczych przylatujących do Bostonu. Każda kapsułka zawierała fragmenty wirusowego RNA, unikatowy wewnętrzny identyfikator oraz zewnętrzne tagi kodujące wymyślone informacje o pacjencie i locie. Następnie przeprowadzili serię zapytań odzwierciedlających rzeczywistą epidemiologię: znalezienie wszystkich pasażerów bez objawów, wybór określonych przedziałów wiekowych do poszukiwania wzorców wariantów oraz wykonanie złożonego zapytania łączonego, które wyciągnęło pasażerów z konkretnego miasta w wybranych miesiącach 2020 roku, którzy byli albo objawowi, albo nieszczepieni. Sekwencjonowanie pobranych kapsułek potwierdziło, że właściwe próbki zostały wzbogacone z bardzo wysoką dokładnością, nawet gdy żądana grupa stanowiła tylko ułamek całej puli.
Dowód, że prawdziwe próbki pacjentów można zachować
Ponad przypadkami testowymi z użyciem syntetycznych próbek, zespół enkapsulował autentyczne próbki SARS-CoV-2 pochodzące od pacjentów, zawierające różne podlinie Omikrona. Po przechowaniu i odzyskaniu przeprowadzili sekwencjonowanie genomów wirusa i porównali je z tymi samymi próbami, które nigdy nie były enkapsulowane. Mimo pracy z bardzo niskimi ilościami wirusowego RNA, metoda nadal odzyskała prawidłowe warianty, co pokazuje, że ochrona krzemionkowa nie zatarła subtelnych różnic genetycznych. Ponieważ kapsułki niebędące celem można zachować po każdym wyszukiwaniu, pula może być ponownie użyta wielokrotnie, a proste wewnętrzne identyfikatory DNA pozwalają na ciągłe kontrole stanu archiwum, podobnie jak kontrole integralności w pamięci cyfrowej.
Co to oznacza na przyszłość
Mówiąc prosto, badanie pokazuje, że próbki genetyczne można zapakować w maleńkie, trwałe kapsułki, zgromadzić razem w niewielkiej przestrzeni w temperaturze pokojowej, a później selekcjonować za pomocą elastycznych, przypominających bazy danych zapytań. Metoda znacznie zmniejsza zależność od zamrażarek, umożliwiając jednocześnie bogate zapytania łączące przedziały wiekowe, lokalizacje, daty i stany zdrowia w jednej operacji. Przy dalszej skalowalności takie archiwa w temperaturze pokojowej mogłyby wspierać globalny nadzór nad patogenami, medycynę precyzyjną, a nawet długoterminowe monitorowanie ekologiczne w miejscach, gdzie infrastruktura chłodnicza jest ograniczona. Praca wskazuje na przyszłość, w której światowa informacja biologiczna może być przechowywana kompaktowo i dostępna równie łatwo jak pliki w chmurze.
Cytowanie: Berleant, J.D., Banal, J.L., Rao, D.K. et al. Enabling global-scale nucleic acid repositories through versatile, scalable biochemical selection from room-temperature archives. Nat Commun 17, 2807 (2026). https://doi.org/10.1038/s41467-026-69402-3
Słowa kluczowe: przechowywanie kwasów nukleinowych, baza danych molekularnych, kodowanie DNA (barcoding), nadzór nad patogenami, przechowywanie biologiczne w temperaturze pokojowej